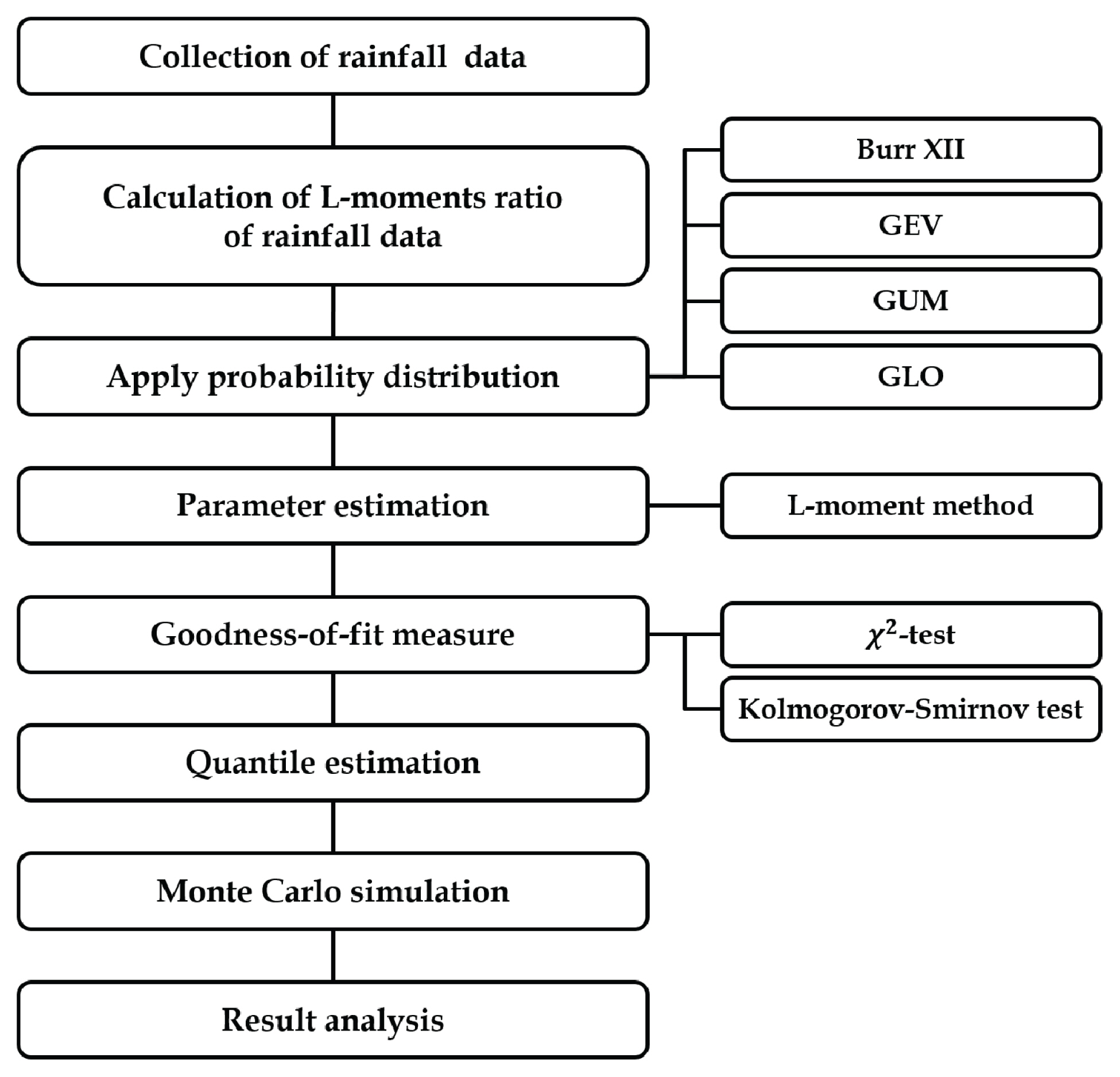
1. žĄú Ž°†
žĶúÍ∑ľ ÍłįŪõĄŽ≥ÄŪôĒŽ°ú žĚłŪēėžó¨ Í≥ľÍĪį ŪÜĶÍ≥ĄžěźŽ£ĆžĚė žĚľŽįėž†ĀžĚł Ž≤ĒžúĄŽ•ľ Ž≤óžĖīŽāėŽäĒ Í∑ĻŪēú ÍįÄŽ≠Ą ŽįŹ ŪôćžąėÍįÄ ŽĻąŽ≤ąŪēėÍ≤Ć ŽįúžÉĚŪēėÍ≥† žěąŽč§. žĚīŽü¨Ūēú žĚīžÉĀ ÍłįžÉĀŪėĄžÉĀžĚÄ žěźžóįžě¨ŪēīžôÄ ŽįÄž†ĎŪēėÍ≤Ć žóįÍīÄŽźėžĖī žěąžĖīžĄú žā¨ŪöĆ‚čÖÍ≤Ĺž†úž†ĀžúľŽ°ú žėĀŪĖ•žĚĄ ŽĮłžĻ† žąė žěąŽäĒ ž§ĎžöĒŪēú žöĒžĚłžĚīŽč§(Houghton et al., 2001). ŽĒįŽĚľžĄú Í∑ĻŪēú ÍįÄŽ≠Ą ŽįŹ Ūôćžąėžóź Ūö®Í≥ľž†ĀžúľŽ°ú ŽĆÄžĚĎŪēėÍłį žúĄŪēėžó¨ žąėÍ≥ĶÍĶ¨ž°įŽ¨ľžĚė žĄ§Í≥Ą žčú Žč§žĖĎŪēú Žį©Ž≤ēžĚĄ ž†Āžö©Ūēėžó¨ žēąž†ĄžĄĪžĚĄ ŪôēŽ≥īŪēėŽäĒ Žį©žēąžĚī ŪĀ¨Í≤Ć Ž∂ÄÍįĀŽźėÍ≥† žěąŽč§. žĚľŽįėž†ĀžúľŽ°ú žąėÍ≥ĶÍĶ¨ž°įŽ¨ľžĚė žĄ§Í≥Ąžóź ÍįÄžě• Íłįžīąž†ĀžĚīÍ≥† Í∑ľÍįĄžĚī ŽźėŽäĒ ž†ąžį®ŽäĒ ŪôēŽ•†ÍįēžöįŽüČ žāįž†ēžĚīŽč§. ŪĎúŽ≥łžúľŽ°úŽ∂ÄŪĄį ž∂Ēž∂úŽźú žąėŽ¨łžěźŽ£Ćžóź ŽĆÄŪēėžó¨ Žč§žĖĎŪēú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ ž†Āžö©ŪēėÍ≥†, ŽĆÄžÉĀ žěźŽ£ĆŽ•ľ ž†Āž†ąŪēėÍ≤Ć ŽāėŪÉÄŽāľ žąė žěąŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ žĄ†ž†ēŪēīžēľ ŪēúŽč§. žĄ†ž†ēŽźú ŪôēŽ•†Ž∂ĄŪŹ¨Ūėēžóź ŽĒįŽĚľ ŪôēŽ•†ÍįēžöįŽüČžĚī Í≤įž†ēŽźėÍłį ŽēĆŽ¨łžóź ž†ĀŪē©Ūēú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ žĄ†ž†ēŪēėŽäĒ Í≤ÉžĚī Žß§žöį ž§ĎžöĒŪēėŽč§(Heo, 2016). ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚī žąėŽ¨łžěźŽ£ĆŽ•ľ ž†Āž†ąŪēėÍ≤Ć ŪĎúŪėĄŪēėŽ†§Ž©ī ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚī ŪĎúŪėĄŪē† žąė žěąŽäĒ ŪÜĶÍ≥Ąž†Ā ŪäĻžĄĪžĚė Ž≤ĒžúĄÍįÄ ŽĄďžĖīžēľ ŪēúŽč§. žĚīŽ•ľ žúĄŪēėžó¨ žąėŽ¨łžěźŽ£ĆžĚė Žč§žĖĎŪēú ŪÜĶÍ≥Ąž†Ā ŪäĻžĄĪžĚĄ ž†Āž†ąŪěą ŪĎúŪėĄŪē† žąė žěąŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ ÍįúŽįúŪēėÍ≥†, ž†Āžö©ŪēėÍłį žúĄŪēú žóįÍĶ¨ÍįÄ Íĺłž§ÄŪěą žßĄŪĖČŽźėÍ≥† žěąŽč§. žąėŽ¨łŪÜĶÍ≥Ą Ž∂ĄžēľžóźžĄúŽäĒ Í∑ĻžĻė žąėŽ¨łžā¨žÉĀžĚĄ ŪēīžĄĚŪēėÍ≥† Ž≥īŽč§ ž†ĀŪē©Ūēú ŪôēŽ•†ÍįēžöįŽüȞ̥ žāįž†ēŪēėÍłį žúĄŪēėžó¨ ÍįĀ ÍĶ≠ÍįÄŽ≥Ą ŽėźŽäĒ žßÄžó≠Ž≥ĄŽ°ú Žč§žĖĎŪēú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ ž†Āžö©ŪēėÍ≥† žěąŽč§. ŽĮłÍĶ≠ žąėžěźžõźŪŹČžĚėŪöĆ(U.S. Water Resources Council, 1976)ŽäĒ ŪôćžąėŽĻąŽŹĄŪēīžĄĚ žąėŪĖČ žčú log-pearson type III (LP3) Ž∂ĄŪŹ¨Ž•ľ Í∂Ćžě•ŪēėÍ≥† žěąžúľŽ©į, Ūėłž£ľžĚė Australian Rainfall and Runoff (The Institution of Engineers, 2001) Ž≥īÍ≥†žĄúžóźžĄúŽŹĄ LP3 Ž∂ĄŪŹ¨Ž•ľ žā¨žö©Ūēėžó¨ ŪôēŽ•†ÍįēžöįŽüȞ̥ žāįž†ēŪēėÍ≥† Intensity-Depth-Frequency (IDF) Í≥°žĄ†žĚĄ žú†ŽŹĄŪē† Í≤ɞ̥ Í∂ĆÍ≥†ŪēėžėÄŽč§. žėĀÍĶ≠žĚė Í≤Ĺžöį Flood Studies Report (NERC, 1975)žóźžĄú žßÄžó≠ŪôćžąėŽĻąŽŹĄŪēīžĄĚ žčú Generalized extreme value (GEV) Ž∂ĄŪŹ¨Ž•ľ ž∂Ēž≤úŪēėžėÄžúľŽāė žĚīŪõĄ Flood Estimation Handbook (IH, 1999)žĄúŽäĒ Generalized logistic (GLO) Ž∂ĄŪŹ¨Ž•ľ žā¨žö©Ūē† Í≤ɞ̥ Í∂Ćžě•ŪēėÍ≥† žěąŽč§. ÍĶ≠ŽāīžóźžĄúŽäĒ žöįŽ¶¨ŽāėŽĚľ 22Íįú žßÄž†źžĚĄ ŽĆÄžÉĀžúľŽ°ú žóį žĶúŽĆÄ ÍįēžöįžěźŽ£ĆŽ•ľ žĚīžö©Ūēėžó¨ ž†Āž†ē Ž∂ĄŪŹ¨Ž™®ŪėēžĚĄ žĄ†ž†ēŪēú Í≤įÍ≥ľ žĶúž†Ā Ž∂ĄŪŹ¨Ž™®ŪėēžúľŽ°ú GEV Ž∂ĄŪŹ¨ÍįÄ žĄ†ž†ēŽźú ŽįĒ žěąŽč§(Heo and Kim, 1995; Kim et al., 1996). ŽėźŪēú ÔĹĘŪēúÍĶ≠ ŪôēŽ•†ÍįēžöįŽüČŽŹĄ žěĎžĄĪ(MOCT, 2000)ÔĹ£žóźžĄúŽäĒ GUM Ž∂ĄŪŹ¨ŪėēžĚĄ žöįŽ¶¨ŽāėŽĚľ ŽĆÄŪĎú Íįēžöį ŪôēŽ•†Ž∂ĄŪŹ¨Ž™®ŪėēžúľŽ°ú ž∂Ēž≤úŪēėžėÄÍ≥†, ÔĹĘŪôēŽ•†ÍįēžöįŽüČŽŹĄ ÍįúžĄ† ŽįŹ Ž≥īžôĄ žóįÍĶ¨(MLTM, 2011)ÔĹ£žóźžĄúŽŹĄ ž†Āž†ē ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžúľŽ°ú GUM Ž∂ĄŪŹ¨Ž•ľ žĪĄŪÉĚŪēėÍ≥† žěąŽč§. Lee, Lee, et al. (2000), Heo et al. (2007) ŽďĪžĚė žóįÍĶ¨žóźžĄúŽäĒ GUM Ž∂ĄŪŹ¨žôÄ GLO Ž∂ĄŪŹ¨Ž•ľ žßÄžó≠ŽĻąŽŹĄŪēīžĄĚžĚė žĶúž†ĀŽ∂ĄŪŹ¨ŪėēžúľŽ°ú žĪĄŪÉĚŪēú ŽįĒ žěąŽč§.
ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚī Í∑ĻŪēú žąėŽ¨łžā¨žÉĀžĚĄ Ž≥īŽč§ Ž™ÖŪôēŪēėÍ≤Ć ŪēīžĄĚŪēėÍłį žúĄŪēīžĄúŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžóźžĄú žĘĆ‚čÖžöįŽ°ú žĻėžöįž≥źžßĄ Í∑ĻŪēúžā¨žÉĀžĚĄ žěė ŪĎúŪėĄŪē† žąė žěąžĖīžēľ ŪēúŽč§. ž¶Č, ž£ľžĖīžßĄ ŪĎúŽ≥ł žěźŽ£ĆžĚė žôúÍ≥°ŽŹĄŽ•ľ ž†Āž†ąŪěą ŪĎúŪėĄŪē† žąė žěąžĖīžēľ ŪēėÍ≥† žĚīŽ•ľ žúĄŪēīžĄ† ŪĎúŽ≥łžěźŽ£ĆžĚė žôúÍ≥°ŽŹĄžôÄ žßĀž†Ďž†ĀžĚł žóįÍīÄžĚī žěąŽč§Í≥† žēĆŽ†§žßĄ ŪėēžÉĀŽß§ÍįúŽ≥Äžąė(shape parameter)žĚė žó≠Ūē†žĚī Žß§žöį ž§ĎžöĒŪēėŽč§. ŪēėžßÄŽßĆ Íłįž°īžóź žā¨žö©Žźú ŽĆÄŽ∂ÄŽ∂ĄžĚė ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēŽď§žĚÄ ŪēėŽāėžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ•ľ ÍįÄžßÄÍ≥† žěąžĖīžĄú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚī ŪĎúŪėĄŪē† žąė žěąŽäĒ ŪÜĶÍ≥Ąž†Ā ŪäĻžĄĪ Ž≤ĒžúĄžóź ŪēúÍ≥ĄÍįÄ žěąŽč§. žĚīŽü¨Ūēú ŪēúÍ≥Ąž†źžĚĄ Í∑ĻŽ≥ĶŪēėÍłį žúĄŪēėžó¨ žÉĀŽĆÄž†ĀžúľŽ°ú ŽßéžĚÄ Žß§ÍįúŽ≥ÄžąėŽ•ľ žĚīžö©Ūēėžó¨ Žč§žĖĎŪēú ŪėēŪÉúžĚė žôúÍ≥°ŽŹĄŽ•ľ Í≥†Ž†§Ūē† žąė žěąŽäĒ kappažôÄ Wakeby Ž∂ĄŪŹ¨žóź ŽĆÄŪēú Žč§žĖĎŪēú žóįÍĶ¨ÍįÄ žßĄŪĖČŽźėžóąŽč§(Lee et al., 1998; Lee, Song, et al., 2000; Oh, 2001; Maeng et al., 2006; Heo et al., 2012). Í∑łŽü¨Žāė kappažôÄ Wakeby Ž∂ĄŪŹ¨ŽäĒ Žč§žĖĎŪēú ŪĎúŽ≥ł žěźŽ£Ćžóź ŽĆÄŪēī ŽĻĄÍĶźž†Ā žēąž†ēž†ĀžĚł Žß§ÍįúŽ≥ÄžąėŽ•ľ ž∂Ēž†ēŪē† žąė žěąžúľŽāė žÉĀŽĆÄž†ĀžúľŽ°ú ŽßéžĚÄ Žß§ÍįúŽ≥ÄžąėŽ°ú žĚłŪēėžó¨ Žß§ÍįúŽ≥Äžąė ž∂Ēž†ēžóź ŽĆÄŪēú Ž∂ąŪôēžč§žĄĪžĚī ŽÜíÍ≥† Žß§ÍįúŽ≥Äžąė ž∂Ēž†ēŽį©Ž≤ēÍ≥ľ ž†ĀŪē©žĄĪ ž°įÍĪīžóź ŽĒįŽĚľ žĚīžö©žóź Ž∂ąŪéłŪē®žĚī ž°īžě¨ŪēėŽäĒ Žč®ž†źžĚī žěąŽč§(Melching et al., 1987; Kim et al., 2004; Kuo et al., 2008; Heo et al., 2012; Na et al., 2014).
ŪēúŪéł, Burr XII Ž∂ĄŪŹ¨ŽäĒ 1942ŽÖĄžóź Burržóź žĚėŪēī ž†úžēąŽźú Ž∂ĄŪŹ¨Ž°ú type IŽ∂ÄŪĄį XIIÍĻĆžßÄ 12ÍįÄžßÄ ŪėēŪÉúŽ°ú ÍĶ¨Ž∂ĄŽźėžĖī žěąŽč§(Burr, 1942). žĚī ž§ĎžóźžĄú Burr XII Ž∂ĄŪŹ¨ŽäĒ žīąÍłįžóź 2Ž≥Äžąė Ž∂ĄŪŹ¨Ž™®ŪėēžúľŽ°ú Ž≥īŪóėÍ≥ĄŽ¶¨Ūēô(Klugman, 1986; Embrechts et al., 1997), žěĄŪēô(Lindsay et al., 1996), ŪôėÍ≤Ĺ(Shao, 2000), žč†ŽĘįžĄĪ Ž∂Ąžēľ(Wang et al., 1996; Wingo, 1983, 1993), žÉĚž°īŽ∂ĄžĄĚ(Shao and Zhou, 2004)Í≥ľ ÍįôžĚī Žč§žĖĎŪēú Ž∂ĄžēľžóźžĄú ž†Āžö©ŽźėÍ≥† Í∑ł žöįžąėžĄĪžĚī Í≤Äž¶ĚŽźėžóąŽč§. ŪēėžßÄŽßĆ žąėŽ¨łŪÜĶÍ≥Ą Ž∂ĄžēľžóźžĄúŽäĒ 2Ž≥Äžąė Burr XII Ž∂ĄŪŹ¨žôÄ Žč§Ž•ł ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēÍ≥ľžĚė žóįÍīÄ ÍīÄÍ≥Ąžóź ŽĆÄŪēīžĄú žóįÍĶ¨ÍįÄ žßĄŪĖČŽźėžóąÍ≥†(Burr and Cislak, 1968; Rodriguez, 1977; Tadikamalla, 1980), žĚīŪõĄ žąėŽ¨łžěźŽ£Ćžóź ŽĆÄŪēú ž†Āžö©žĄĪžĚĄ ŽÜížĚīÍłį žúĄŪēī Í∑úŽ™®Žß§ÍįúŽ≥Äžąė(scale parameter)ÍįÄ ž∂ĒÍįÄŽźú 3Ž≥Äžąė ŪėēŪÉúžĚė Burr XII Ž∂ĄŪŹ¨ÍįÄ ÍįúŽįúŽźėžóąŽč§(Tadikamalla, 1980; Shao, 2004). ŪäĻŪěą Shao et al. (2004)žĚī ž†úžčúŪēú extended Burr XII (BUR) Ž∂ĄŪŹ¨ŽäĒ Íłįž°īžĚė Burr XII Ž∂ĄŪŹ¨Ž•ľ Ūôēžě•Ūēėžó¨ Ūēú ÍįúžĚė Í∑úŽ™®Žß§ÍįúŽ≥ÄžąėžôÄ ŽĎź ÍįúžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ•ľ ÍįĖŽäĒ 3Ž≥Äžąė Ž∂ĄŪŹ¨Ž°ú Íłįž°ī Burr XII Ž∂ĄŪŹ¨žôÄ Žč¨Ž¶¨ ŪĎúŽ≥łžěźŽ£ĆÍįÄ ÍįĖŽäĒ Žč§žĖĎŪēú Ž≤ĒžúĄžĚė ž≤®žėąŽŹĄžôÄ žôúÍ≥°ŽŹĄŽ•ľ Í≥†Ž†§Ūē† žąė žěąŽäĒ Í≤ÉžúľŽ°ú žēĆŽ†§ž†ł žěąŽč§. Shao et al. (2004)ŽäĒ BUR Ž∂ĄŪŹ¨Ž•ľ ž§ĎÍĶ≠ Žā®Ž∂ÄžßÄžó≠žĚė ž£ľÍįē(Pearl River) žú†žó≠Í≥ľ Ž∂ĀŽŹôŽ∂ÄžĚė Dang Jian Kou River žú†žó≠žĚė ŪôćžąėžěźŽ£Ćžóź ž†Āžö©Ūēėžó¨ Íłįž°īžóź žā¨žö©ŪēėŽćė LP3 Ž∂ĄŪŹ¨Žāė generalized Pareto (GPA) Ž∂ĄŪŹ¨Ž≥īŽč§ ŽćĒ žöįžąėŪēú Í≤įÍ≥ľŽ•ľ ŪôēžĚłŪēėžėÄÍ≥†, Ganora and Laio (2015)ŽäĒ žĚīŪÉąŽ¶¨žēĄ Ž∂ĀžĄúž™Ĺžú†žó≠ 115Íįú žßÄž†źžĚė ŪôćžąėžěźŽ£Ćžóź ž†Āžö©Ūēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚė ž†Āžö©žĄĪ ŽįŹ žöįžąėžĄĪžĚĄ Í≤Äž¶ĚŪēú ŽįĒ žěąŽč§. žöįŽ¶¨ŽāėŽĚľžóźžĄúŽŹĄ Seo et al. (2017)žĚÄ BUR Ž∂ĄŪŹ¨ŪėēžĚĄ žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£Ćžóź ž†Āžö©Ūēėžó¨ L-moment ratio diagramžĚĄ Ž∂ĄžĄĚŪē®žúľŽ°úžć® ŪēúÍįēžú†žó≠žóźžĄú ž†Āžö©žĄĪžĚī žöįžąėŪēú Í≤ÉžúľŽ°ú Í≤Äž¶ĚŪēú ŽįĒ žěąŽč§.
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ BUR Ž∂ĄŪŹ¨žĚė ŪäĻžĄĪžĚĄ žāīŪéīŽ≥īÍ≥†žěź žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£ĆžĚė ŽĻąŽŹĄŪēīžĄĚžóź ž£ľŽ°ú žā¨žö©ŽźėŽäĒ GEV, GUM, GLO Ž∂ĄŪŹ¨žôÄ BUR Ž∂ĄŪŹ¨Ž•ľ žĚīžö©Ūēú ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ žąėŪĖČŪēėžėÄÍ≥† Í≤Äž†ē Í≤įÍ≥ľŽ•ľ ŽĻĄÍĶź‚čÖŽ∂ĄžĄĚŪēėžėÄŽč§. ŽėźŪēú Monte Carlo Ž™®žĚėžč§ŪóėžĚĄ žĚīžö©Ūēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚė ž†Āžö© ÍįÄŽä•žĄĪžĚĄ ž†ēŽüČž†ĀžúľŽ°ú Í≤ÄŪ܆ŪēėžėÄŽč§.
2. ÍłįŽ≥łžĚīŽ°†
2.1 ŪôēŽ•†Ž∂ĄŪŹ¨Ž™®Ūėē
2.1.1 Burr XII Ž∂ĄŪŹ¨
Ž≥ł žóįÍĶ¨žóźžĄú žā¨žö©Žźú BUR Ž∂ĄŪŹ¨ŽäĒ Shao et al. (2004)žóź žĚėŪēī žÜĆÍįúŽźú Ž∂ĄŪŹ¨ŪėēžúľŽ°ú Íłįž°ī 2Ž≥Äžąė BUR Ž∂ĄŪŹ¨Ž•ľ Ūôēžě•Ūēėžó¨ Ūēú ÍįúžĚė Í∑úŽ™®Žß§ÍįúŽ≥ÄžąėžôÄ ŽĎź ÍįúžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ•ľ ÍįÄžßÄŽäĒ ŪäĻžßēžĚī žěąžúľŽ©į, Íłįž°ī 2Ž≥Äžąė BUR Ž∂ĄŪŹ¨Ž≥īŽč§ Žč§žĖĎŪēú žôúÍ≥°ŽŹĄžôÄ ž≤®žėąŽŹĄŽ•ľ ÍįÄžßÄŽäĒ ŪĎúŽ≥łžóź ŽĆÄŪēī ž†Āžö©žĚī ÍįÄŽä•Ūēú žě•ž†źžĚī žěąŽč§. 3Ž≥Äžąė BUR Ž∂ĄŪŹ¨žĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžôÄ ŪôēŽ•†Ž∂ĄŪŹ¨Ūē®žąėŽäĒ Žč§žĚĆ Eqs. (1)‚ąľ(2)žôÄ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§(Shao et al., 2004; Ganora and Laio, 2015).
(2)
žó¨ÍłįžĄú őĪŽäĒ Í∑úŽ™®Žß§ÍįúŽ≥ÄžąėžĚīÍ≥†, ő≤žôÄ ő≤1žĚÄ ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėžĚīŽč§. xžĚė Ž≤ĒžúĄŽäĒ ő≤‚ȧ0 žĚľ ŽēĆ 0‚ȧx<‚ąěžĚīÍ≥†, ő≤>0 žĚľ ŽēĆŽäĒ 0 ‚ȧ x < őĪ / ő≤ 1 / ő≤ 1
2.1.2 Gumbel Ž∂ĄŪŹ¨
GUM Ž∂ĄŪŹ¨ŽäĒ žĶúŽĆÄžĻė ŪėĻžĚÄ žĶúžÜĆžĻė ŽďĪ Í∑ĻžĻė žěźŽ£ĆžĚė ŽĻąŽŹĄŪēīžĄĚžóź ž£ľŽ°ú žā¨žö©ŽźėŽ©į, ŪôćžąėŽüČ ŽėźŽäĒ ÍįēžąėŽüČ žěźŽ£ĆžĚė ŽĻąŽŹĄŪēīžĄĚžóź ŽßéžĚī žĚīžö©ŽźúŽč§. GUM Ž∂ĄŪŹ¨žĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžôÄ ŪôēŽ•†Ž∂ĄŪŹ¨Ūē®žąėŽäĒ Žč§žĚĆ Eqs. (3)‚ąľ(4)žôÄ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§(Hosking and Wallis, 1997).
žó¨ÍłįžĄú őľŽäĒ žúĄžĻėŽß§ÍįúŽ≥Äžąė(location parameter) Í∑łŽ¶¨Í≥† őĪŽäĒ Í∑úŽ™®Žß§ÍįúŽ≥Äžąė žĚīŽč§. xžĚė Ž≤ĒžúĄŽäĒ -‚ąě < x < ‚ąěžĚīŽč§.
2.1.3 Generalized Extreme Value Ž∂ĄŪŹ¨
GEV Ž∂ĄŪŹ¨ŽäĒ Í∑ĻžĻė žąėŽ¨łžā¨žÉĀ ŽĻąŽŹĄŪēīžĄĚžóź ž£ľŽ°ú žā¨žö©ŽźėŽäĒ Ž∂ĄŪŹ¨Ž™®ŪėēžúľŽ°ú žē장ú žĖłÍłČŪēú GUM Ž∂ĄŪŹ¨žôÄ ŽćĒŽ∂ąžĖī žöįŽ¶¨ŽāėŽĚľ Íįēžöįžā¨žÉĀžóź ž†ĀŪē©Ūēú Í≤ÉžúľŽ°ú žēĆŽ†§ž†ł ŽßéžĚī žā¨žö©ŽźėÍ≥† žěąŽč§. ŪäĻŪěą GUM Ž∂ĄŪŹ¨žôÄ ŽĻĄÍĶźŪēėžó¨ ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėžĚė ž°īžě¨Ž°ú Í∑ĻžĻė žąėŽ¨łžěźŽ£Ćžóź Ž≥īŽč§ žú†žóįŪēėÍ≤Ć ž†Āžö©Ūē† žąė žěąŽč§. GEV Ž∂ĄŪŹ¨žĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžôÄ ŪôēŽ•†Ž∂ĄŪŹ¨Ūē®žąėŽäĒ Žč§žĚĆ Eqs. (5)‚ąľ(6)Í≥ľ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§(Hosking and Wallis, 1997).
(5)
žó¨ÍłįžĄú őĪŽäĒ Í∑úŽ™®Žß§ÍįúŽ≥Äžąė, ő≤ŽäĒ ŪėēžÉĀŽß§ÍįúŽ≥Äžąė Í∑łŽ¶¨Í≥† őľŽäĒ žúĄžĻėŽß§ÍįúŽ≥ÄžąėžĚīŽč§. xžĚė Ž≤ĒžúĄŽäĒ ő≤ = 0žĚľ ŽēĆ -‚ąě < x < ‚ąěžĚīÍ≥† ő≤ > 0, ő≤ < 0 žĚľ ŽēĆŽäĒ őľ + őĪ/ő≤ Íįížóź žĚėŪēī žÉĀŪēúÍ≥ľ ŪēėŪēúžĚī ž†ēŪēīžßĄŽč§. ŽėźŪēú GEV Ž∂ĄŪŹ¨ŽäĒ ő≤ = 0 ž°įÍĪīžóźžĄúŽäĒ GUM Ž∂ĄŪŹ¨ÍįÄ ŽźėÍ≥† ő≤ > 0žóźžĄúŽäĒ Weibull Ž∂ĄŪŹ¨, Í∑łŽ¶¨Í≥† ő≤ < 0žĚł Í≤ĹžöįŽäĒ Fr√©chet Ž∂ĄŪŹ¨ÍįÄ ŽźėŽäĒ ŪäĻžßēžĚĄ ÍįÄžßÄÍ≥† žěąŽč§.
2.1.4 Generalized logistic Ž∂ĄŪŹ¨
GLO Ž∂ĄŪŹ¨ŽäĒ 2Ž≥Äžąė logistic Ž∂ĄŪŹ¨žĚė žĚľŽįėŪôĒŽźú Ž™®ŪėēžúľŽ°ú kappa Ž∂ĄŪŹ¨žĚė ŪäĻžąėŪēú ŪėēŪÉúžĚīŽč§. žĶúÍ∑ľ žßÄžó≠ŽĻąŽŹĄŪēīžĄĚžóźžĄú žā¨žö©žĚī ž¶ĚÍįÄŪēėÍ≥† žěąŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžúľŽ°ú Íłįž°īžĚė GEV Ž∂ĄŪŹ¨Ž≥īŽč§ ŪôēŽ•†ŽįÄŽŹĄŪē®žąėžĚė žė§Ž•łž™Ĺ Íľ¨Ž¶¨Ž∂ÄŽ∂ĄžĚī ŽĎźÍļľžöī ŪäĻžßēžĚĄ ÍįÄžßÄÍ≥† žěąŽč§. GLO Ž∂ĄŪŹ¨žĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžôÄ ŪôēŽ•†Ž∂ĄŪŹ¨Ūē®žąėŽäĒ Žč§žĚĆ Eqs. (7)‚ąľ(8)Í≥ľ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§(Hosking and Wallis, 1997).
žó¨ÍłįžĄú őĪŽäĒ Í∑úŽ™®Žß§ÍįúŽ≥Äžąė, ő≤ŽäĒ ŪėēžÉĀŽß§ÍįúŽ≥Äžąė Í∑łŽ¶¨Í≥† őľŽäĒ žúĄžĻėŽß§ÍįúŽ≥ÄžąėžĚīŽč§. xžĚė Ž≤ĒžúĄŽäĒ ő≤ = 0žĚľ ŽēĆ -‚ąě < x < ‚ąěžĚīÍ≥† ő≤ > 0, ő≤ < 0žĚľ ŽēĆ őľ + őĪ/ő≤ Íįížóź žĚėŪēėžó¨ žÉĀŪēúÍ≥ľ ŪēėŪēúžĚī ž†ēŪēīžßĄŽč§.
2.2 Žß§ÍįúŽ≥Äžąė ž∂Ēž†ē
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ Žß§ÍįúŽ≥Äžąė ž∂Ēž†ēŽį©Ž≤ēžúľŽ°ú L-moment Žį©Ž≤ēžĚĄ žĚīžö©ŪēėžėÄŽč§. L-moment Žį©Ž≤ēžĚÄ žį®žąėÍįÄ Žč§Ž•ł ŪôēŽ•†ÍįÄž§ĎŽ™®Ž©ėŪäł(Probability weighted moments, PWM)Ž•ľ žĄ†ŪėēžúľŽ°ú ÍįÄž§ĎŪēėžó¨ ŪéłžĚėÍįÄ ž†úÍĪįŽźú Ž™®Ž©ėŪ䳎•ľ ÍĶ¨ŪēėŽäĒ Žį©Ž≤ēžúľŽ°ú žĚľŽįė Ž™®Ž©ėŪ䳎≤ēÍ≥ľ žú†žā¨ŪēėÍ≤Ć žā¨žö©ŽźėŽ©į ŪôēŽ•†Ž∂ĄŪŹ¨Ž™®ŪėēžĚė Žß§ÍįúŽ≥ÄžąėŽ•ľ ž∂Ēž†ēŪē† žąė žěąŽč§. PWMžĚÄ Ž≥ÄžąėÍįíÍ≥ľ Ž≥ÄžąėžĚė ŪŹČÍ∑†ÍįíÍ≥ľžĚė žį®žĚīŽ•ľ Ž™®Ž©ėŪäłžĚė žį®žąėžóź ŽĒįŽĚľ ÍĪįŽď≠ž†úÍ≥ĪŪēėžó¨ Ž™®Ž©ėŪ䳎•ľ Í≥ĄžāįŪēėŽ©į, Eq. (9)žôÄ ÍįôžĚī ž†ēžĚėŽźúŽč§(Greenwood et al., 1979).
žó¨ÍłįžĄú x(F)ŽäĒ quantile functionžĚīÍ≥† sŽäĒ Ž™®Ž©ėŪäłžĚė žį®žąėžĚīŽč§. BUR Ž∂ĄŪŹ¨žĚė PWMžĚÄ Hao and Singh (2009)žóź žĚėŪēīžĄú žú†ŽŹĄŽźėžóąžúľŽ©į, ő≤ÍįížĚÄ žĖĎžĚė ÍįížĚĄ ÍįÄžßą žąė žóÜŽäĒ Í≤ÉžĚī ŪäĻžßēžĚīŽč§(Hao and Singh, 2009). Burr XII Ž∂ĄŪŹ¨žĚė PWMžĚÄ Eq. (10)Í≥ľ ÍįôŽč§.
(10)
žó¨ÍłįžĄú őď(‚ąô)ŽäĒ ÍįźŽßą Ūē®žąėŽ•ľ ŽāėŪÉÄŽāīŽ©į, L-moment őĽ1, őĽ2, őĽ3, őĽ4Ž•ľ PWMžĚė žĄ†Ūėēž°įŪē©žúľŽ°ú ŪĎúžčúŪēėŽ©ī Žč§žĚĆ Eqs. (11)‚ąľ(14)žôÄ ÍįôŽč§(Landwehr et al., 1979; Hosking and Wallis, 1997).
Eqs. (11)‚ąľ(14)Ž•ľ žĚīžö©Ūēėžó¨ L-moment ŽĻĄŽ•ľ Žč§žĚĆ Eqs. (15)‚ąľ(17)Í≥ľ ÍįôžĚī ÍĶ¨Ūē† žąė žěąŽč§(Hosking and Wallis, 1997).
L-CVžôÄ L-skewnessŽ•ľ Ž¨īžį®žõźŪôĒŪēėÍ≥† žĚīŽď§žĚė žÉĀÍīÄÍīÄÍ≥ĄŽ•ľ ŪÜĶŪēīžĄú ŪėēžÉĀŽß§ÍįúŽ≥Äžąė ő≤žôÄ ő≤1žĚĄ ÍĶ¨Ūē† žąė žěąžúľŽ©į(Ganora and Laio, 2015), Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ Seo et al. (2017)žóź žĚėŪēī žú†ŽŹĄŽźú L-momentžôÄ L-moment ratioŽ•ľ žā¨žö©ŪēėžėÄŽč§. BUR Ž∂ĄŪŹ¨žĚė Í∑úŽ™®Žß§ÍįúŽ≥ÄžąėžôÄ ÍįĀÍįĀžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ•ľ ÍĶ¨ŪēėŽäĒ žčĚžĚÄ Žč§žĚĆ Eqs. (18)‚ąľ(22)žôÄ ÍįôŽč§.
(19)
(21)
žó¨ÍłįžĄú ŌĄŽäĒ ŪĎúŽ≥łžĚė L-CVŽ•ľ ŽāėŪÉÄŽāīŽ©į, žā¨žö©Žźú GEV, GUM, GLO Ž∂ĄŪŹ¨žĚė Žß§ÍįúŽ≥ÄžąėŽäĒ Hosking and Wallis (1997)žĚė Žį©Ž≤ēžĚĄ žįłÍ≥†Ūēėžó¨ ž∂Ēž†ēŪēėžėÄŽč§.
2.3 ž†ĀŪē©ŽŹĄ Í≤Äž†ē
ž†ĀŪē©ŽŹĄ Í≤Äž†ē(goodness-of-fit test, GOF test)žĚÄ ŽĆÄžÉĀ žěźŽ£ĆŽ°úŽ∂ÄŪĄį žĖĽžĖīžßÄŽäĒ Ž∂ĄŪŹ¨žôÄ ÍįÄž†ēŪēú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚī žĖľŽßąŽāė žěė žĚľžĻėŪēėŽäĒÍįÄŽ•ľ Í≤Äž†ēŪēėŽäĒ Í≤ÉžĚīŽč§. Ž™®žßώ讞Ěė ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ žēĆžßÄ Ž™ĽŪēėŽ©ī Íłįž°īžĚė ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžúľŽ°ú Ž™®žßώ讞Ěė žĄĪžßąžĚĄ ž†ēŪôēŪěą ŽāėŪÉÄŽāīÍłį žĖīŽ†§žöįŽĮÄŽ°ú Žč§žĖĎŪēú ÍłįŽ≤ēžĚĄ ŪÜĶŪēīžĄú ŽßéžĚÄ ž†ēŽ≥īŽ•ľ žĚīžö©Ūēėžó¨ ž†Āž†ąŪēú ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ žĄ†ž†ēŪēėŽäĒ Í≤ÉžĚī Ūē©Ž¶¨ž†ĀžĚīŽč§(Shin et al., 2010). ŪôēŽ•†ŽįÄŽŹĄŪē®žąėžóź ŽĆÄŪēīžĄúŽäĒ Ōá2-test, ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžóź ŽĆÄŪēīžĄúŽäĒ Kolmogorov-Smirnov (K-S) test Žį©Ž≤ēžĚĄ žĚīžö©Ūēėžó¨ ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ žąėŪĖČŪēėžėÄŽč§.
2.3.1 Ōá2-test
Ōá2-testŽäĒ ŽĆÄžÉĀ žěźŽ£Ćžóź ž†ĀŪē©ŪēėŽč§Í≥† ÍįÄž†ēŪēú ŪôēŽ•†ŽįÄŽŹĄŪē®žąėžôÄ ÍĶįžßĎŪôĒŽźú žěźŽ£ĆŽ•ľ žĚīžö©Ūēú ŽĻąŽŹĄŪēīžĄĚžĚĄ ŪÜĶŪēėžó¨ ÍĶ¨ŪēīžßÄŽäĒ Í≤ĹŪóėž†Ā ŪôēŽ•†ŽįÄŽŹĄŪē®žąėŽ•ľ ŽĻĄÍĶźŪēėŽäĒ Í≤Äž†ēŽį©Ž≤ēžúľŽ°ú, žěźŽ£ĆŽ•ľ ŪĀ¨Íłįžóź ŽĒįŽĚľ mÍįúžĚė Í≥ĄÍłČ ÍĶ¨ÍįĄžúľŽ°ú ŽāėŽąĄÍ≥† žĚīŽ°†ÍįíÍ≥ľ žěźŽ£ĆÍįížĚė ž†ąŽĆÄ ŽŹĄžąėŽ•ľ ŽĻĄÍĶźŪēėŽäĒ Žį©Ž≤ēžúľŽ°ú Í≤Äž†ēŪÜĶÍ≥ĄŽüČ qŽäĒ Žč§žĚĆÍ≥ľ ÍįôŽč§.
žó¨ÍłįžóźžĄú njŽäĒ ÍīÄžł° žěźŽ£ĆžĚė jŽ≤ąžßł ÍĶ¨ÍįĄžĚė ŪĎúŽ≥ł ÍīÄžł° ŽŹĄžąė, ej = npjŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨žĚė jŽ≤ąžßł ÍĶ¨ÍįĄžĚė žĚīŽ°†ŽŹĄžąėžĚīŽ©į, mžĚÄ Í≥ĄÍłČ ÍĶ¨ÍįĄžĚė žąėŽ•ľ ŽāėŪÉÄŽāłŽč§. ŽėźŪēú pjŽäĒ ÍĶ¨ÍįĄ Žāī ŪäĻž†ē ÍłįÍįĀžĻėŽ•ľ ŽßĆž°ĪŪēėŽäĒ Ž™®žĚėŽ≥ÄžąėŪôēŽ•†Ž°ú, žú†žĚėžąėž§Ä őĪžóź ŽĆÄŪēī Í∑ÄŽ¨īÍįÄžĄ§žĚī q‚Č•KŽ°ú ÍłįÍįĀŽźúŽč§Í≥† ŪēėŽ©ī P(q‚Č•K;q~Ōá2(k=1)) = őĪŽ°ú ž†ēžĚėŽźėŽ©į K = Ōá2(k-1)žúľŽ°ú Í≥ĄÍłČ ÍĶ¨ÍįĄžĚĄ ŽāėŽąą ŪõĄ Í≤įž†ēŽźúŽč§. Í≥ĄžāįŽźú ŪÜĶÍ≥ĄŽüČžĚÄ Ōá2 < Ōá 2 1 - őĪ , v Ōá 1 - őĪ , ¬† v 2
2.3.2 Kolmogorov-Smirnov test
K-S testžĚė ÍłįŽ≥łž†ĀžĚł ž†ąžį®ŽäĒ ž£ľžĖīžßĄ ŪĎúŽ≥łžěźŽ£ĆžĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėžôÄ ÍįÄž†ēŽźú žĚīŽ°†ž†Ā ŪôēŽ•†Ž∂ĄŪŹ¨Ž™®ŪėēžĚė ŽąĄÍįÄŽ∂ĄŪŹ¨Ūē®žąėŽ•ľ ŽĻĄÍĶźŪēėŽäĒ Í≤ÉžúľŽ°ú žĖĎžěźžĚė žĶúŽĆÄŪéłžį®ÍįÄ ŪĎúŽ≥łžĚė ŪĀ¨ÍłįžôÄ žú†žĚėžąėž§Äžóź ŽĒįŽĚľ Í≤įž†ēŽźėŽäĒ ŪēúÍ≥ĄŪéłžį®Ž≥īŽč§ ŪĀ¨Ž©ī ŪēīŽčĻ Ž∂ĄŪŹ¨ÍįÄ ÍłįÍįĀŽźėŽäĒ Í≤Äž†ē Žį©Ž≤ēžĚīŽč§.
žó¨ÍłįžĄú Sn(x)ŽäĒ žěźŽ£ĆŽ•ľ ŪĀ¨ÍłįžąúžúľŽ°ú žě¨ŽįįžóīŪĖąžĚĄ ŽēĆžĚė kŽ≤ąžßł žěźŽ£ĆžĚė žĚīŽ°†ž†Ā ŽąĄž†ĀŽįúžÉĚŪôēŽ•†, nžĚÄ žěźŽ£ĆžĚė žīĚ ÍįúžąėžĚīŽč§. ž†Ąž≤ī ÍĶ¨ÍįĄžĚė Sn(x)žôÄ F(x)žĚė žĶúŽĆÄ Ūéłžį®ŽäĒ Dn = max|F(x) - Sn(x)|Ž°ú Í≥ĄžāįŪēúŽč§. žĶúŽĆÄŪéłžį® DnžĚÄ nžĚė ŪĀ¨Íłįžóź ŽĒįŽĚľ žĘĆžöįŽźėŽäĒ ŪôēŽ•†Ž≥ÄžąėŽ°úžĄú žú†žĚėžąėž§Ä őĪžóź ŽĒįŽĚľ ž†ĀŪē©žĄĪžĚī Í≤įž†ēŽźúŽč§.
2.4 Log likelihood
žöįŽŹĄ(likelihood)ŽäĒ ŪôēŽ•†Ž∂ĄŪŹ¨Ūē®žąėžóźžĄú Ž™®žąėÍįÄ žĖīŽĖ§ ŪôēŽ•†Ž≥ÄžąėžĚė žěźŽ£ĆžôÄ žĚľÍīÄŽźėŽäĒ ž†ēŽŹĄŽ•ľ ŽāėŪÉÄŽāīŽäĒ ÍįížĚīŽč§. ž¶Č, Ž™®Ž∂ĄŪŹ¨žóźžĄú ŪēīŽčĻ žěźŽ£Ćžóź ŽĆÄŪēėžó¨ Ž∂Äžó¨ŪēėŽäĒ ŪôēŽ•†Ž°ú Žč§žĚĆÍ≥ľ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§.
Log likelihood(logL)ŽäĒ likelihood Ūē®žąėžóź Ž°úÍ∑ł Ūē®žąėŽ•ľ žĒĆžöī Í≤ÉžúľŽ°ú, ŪôēŽ•† Ž≥ÄžąėÍįÄ ŽŹÖŽ¶Ĺ ŪôēŽ•† Ž≥ÄžąėŽ°ú ŽāėŽąĄžĖīžßÄŽäĒ Í≤ĹžöįžôÄ ÍįôžĚī ŪôēŽ•† Ž∂ĄŪŹ¨ Ūē®žąėÍįÄ Í≥ĪžÖą ÍľīŽ°ú Žāėžė¨ ŽēĆ ŽĮłŽ∂ĄÍ≥ĄžāįžĚė ŪéłžĚėžĄĪžĚĄ žúĄŪēī ž£ľŽ°ú žā¨žö©ŽźúŽč§. Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ Ž∂ĄŪŹ¨Ūėē ÍįĄ ž†ĀŪē©žĄĪžĚĄ ŽĻĄÍĶźŪēėÍłį žúĄŪēėžó¨ ÍįĀ Ž∂ĄŪŹ¨ŪėēžĚė Žß§ÍįúŽ≥ÄžąėŽäĒ L-momentŽ≤ēžĚĄ žĚīžö©Ūēėžó¨ ž∂Ēž†ēŪēėžėÄÍ≥† log likelihood Íįí(logL)žĚĄ žā¨žö©Ūēėžó¨ Ž∂ĄŪŹ¨ŪėēžĚĄ ŪŹČÍįÄŪēėžėÄŽč§. ÍįĀ Ž∂ĄŪŹ¨ŪėēžóźžĄú žāįž†ēŽźú logL ÍįížĚĄ ŽĻĄÍĶźŪēėžó¨ logL ÍįížĚī ŪĀīžąėŽ°Ě Ž∂ĄŪŹ¨ŪėēžĚī Ž™®žĚėŪēú žěźŽ£ĆŽ•ľ žěė ŪĎúŪėĄŪēúŽč§Í≥† ŪĆźŽč®Ūē† žąė žěąŽč§.
3. ž†Āžö© ŽįŹ Í≤įÍ≥ľ
3.1 Žį©Ž≤ēŽ°†
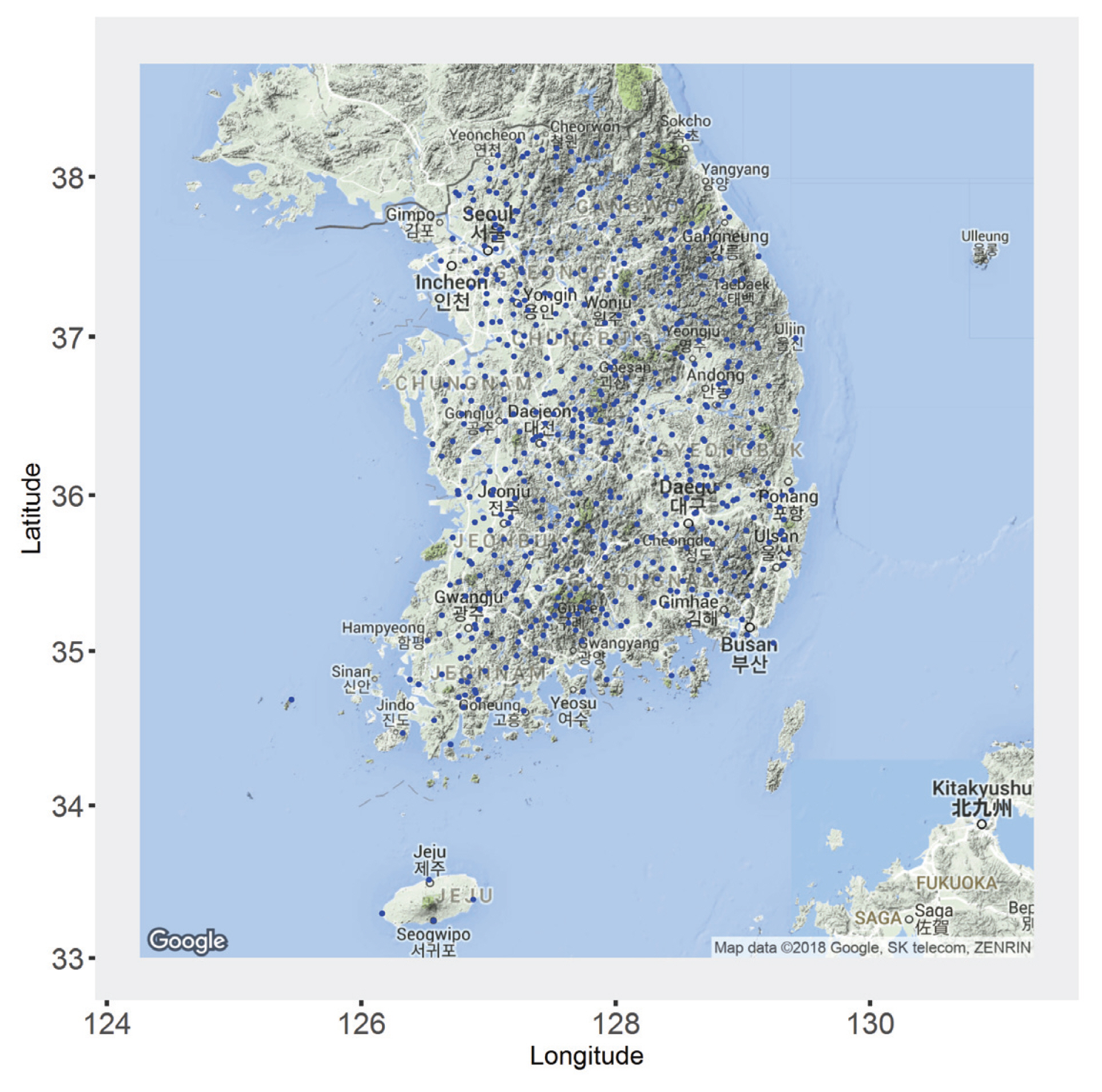
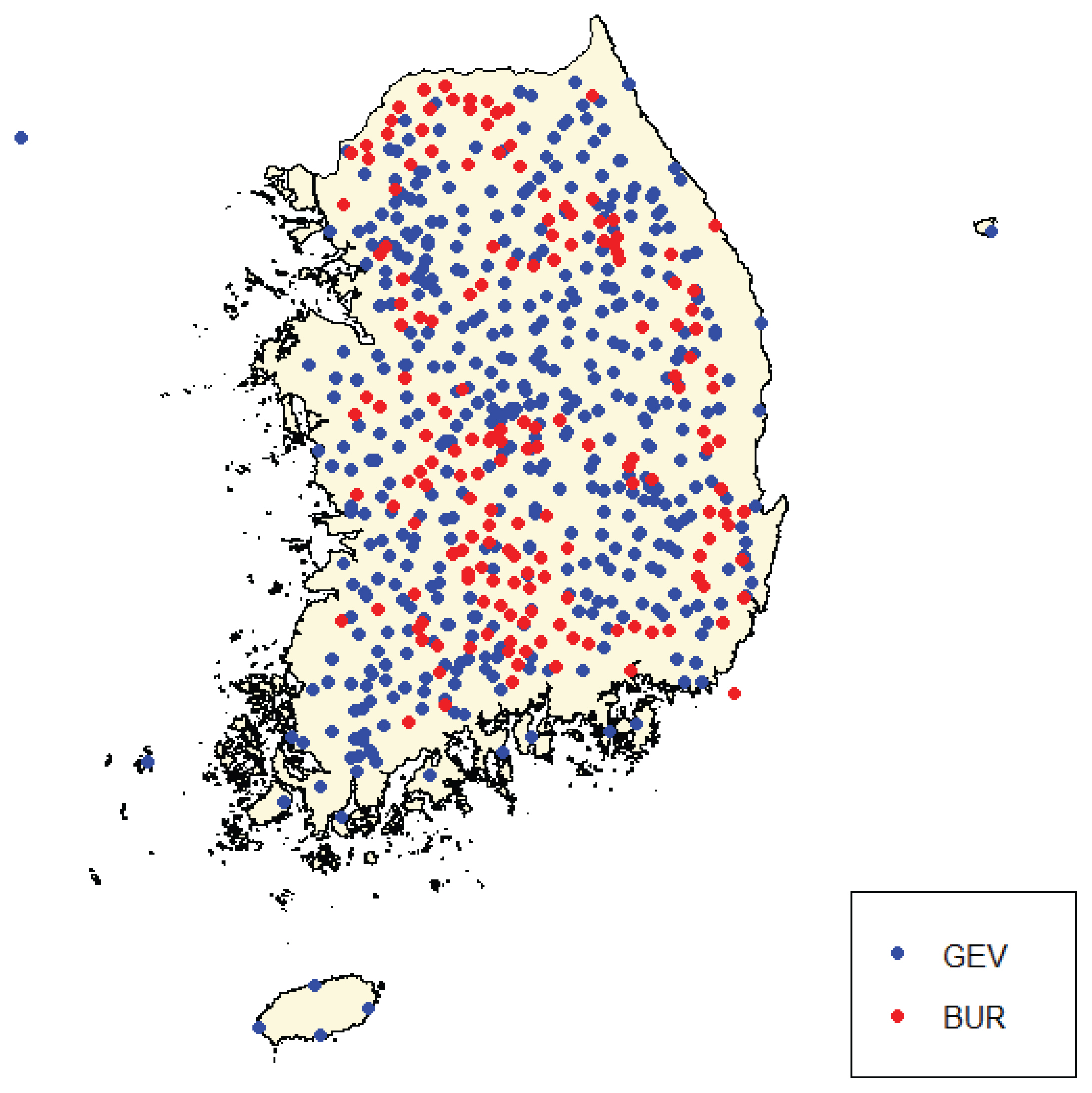
Fig. 1žĚÄ Ž≥ł žóįÍĶ¨žĚė ŪĚźŽ¶ĄžĚĄ ŽāėŪÉÄŽāł Í≤ÉžúľŽ°ú žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£Ćžóź ŽĆÄŪēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚė ž†Āžö© ÍįÄŽä•žĄĪžĚĄ Í≤ÄŪ܆ŪēėÍ≥†žěź 24žčúÍįĄ žóį žĶúŽĆÄ ÍįēžöįžěźŽ£ĆŽ•ľ žĚīžö©Ūēėžó¨ ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ žąėŪĖČŪēėžėÄŽč§. ŽėźŪēú, BUR Ž∂ĄŪŹ¨ŪėēžĚė ž†Āžö©žĄĪžĚĄ Í≤ÄŪ܆ŪēėÍ≥†žěź Monte Carlo Ž™®žĚėžč§ŪóėžĚĄ žĚīžö©ŪēėžėÄÍ≥†, ÍįĀ žßÄž†źžĚė ÍīÄžł°ÍįížúľŽ°úŽ∂ÄŪĄį ž∂Ēž†ēŽźú Žß§ÍįúŽ≥ÄžąėŽ•ľ kappa Ž∂ĄŪŹ¨Ūėēžóź ž†Āžö©Ūēėžó¨ žěźŽ£ĆŽ•ľ ŽįúžÉĚŪēėÍ≥† GEV, GLO, GUM, BUR Ž∂ĄŪŹ¨Ūėēžóź ž†ĀŪē©žčúžľú log likelihoodŽ•ľ Í≥ĄžāįŪēú ÍįížĚĄ Íłįž§ÄžúľŽ°ú ž†Āž†ąŪēú Ž∂ĄŪŹ¨ŪėēžĚĄ ŪĆźŽč®ŪēėžėÄŽč§. Ž≥ł žóįÍĶ¨Ž•ľ žąėŪĖČŪēėÍłį žúĄŪēėžó¨ ÍĶ≠Ū܆ÍĶźŪÜĶŽ∂Ä, ÍłįžÉĀž≤≠, ŪēúÍĶ≠žąėžěźžõźÍ≥Ķžā¨ ŽďĪžĚė žöįŽ¶¨ŽāėŽĚľ 617Íįú žßÄž†źžóźžĄú 24žčúÍįĄ žóį žĶúŽĆÄ Íįēžöį žěźŽ£ĆŽ•ľ žąėžßĎŪēėžėÄŽč§. žąėžßĎŽźú žóį žĶúŽĆÄ Íįēžöį žěźŽ£ĆŽäĒ ŪēúÍįē žú†žó≠ 212Íįú, ŽāôŽŹôÍįē žú†žó≠ 206Íįú, ÍłąÍįē žú†žó≠ 117Íįú, Í∑ł žôł(žĄ¨žßĄÍįē, žėĀžāįÍįē žú†žó≠) 82Íįú žßÄž†źžúľŽ°ú ÍĶ¨žĄĪŽźėžĖī žěąžúľŽ©į ÍįĀ žßÄž†źžĚė žúĄžĻėŽäĒ Fig. 2žôÄ ÍįôŽč§.
3.2 ž†ĀŪē©ŽŹĄ Í≤Äž†ē Í≤įÍ≥ľ
ž†Ąžą†Ūēú ŽįĒžôÄ ÍįôžĚī žöįŽ¶¨ŽāėŽĚľ 617Íįú žßÄž†źžĚĄ ŽĆÄžÉĀžúľŽ°ú ž†Āžö©Ūēú Ž∂ĄŪŹ¨ŪėēŽ≥Ą Ōá2-testžôÄ K-S testŽ•ľ ŪÜĶÍ≥ľŪēú žßÄž†źžĚė žąėŽäĒ Table 1Í≥ľ ÍįôŽč§. Table 1žóźžĄú Ōá2-test Í≤įÍ≥ľŽ•ľ žāīŪéīŽ≥īŽ©ī GUM Ž∂ĄŪŹ¨ŪėēžĚī ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ ŪÜĶÍ≥ľŪēėŽäĒ žßÄž†źžąėÍįÄ 570ÍįúŽ°ú Žč§Ž•ł Ž∂ĄŪŹ¨ŪėēÍ≥ľ ŽĻĄÍĶźŪēėžó¨ žÉĀŽĆÄž†ĀžúľŽ°ú žěĎÍ≤Ć ŽāėŪÉÄŽā¨žúľŽ©į, Žč§Ž•ł Ž∂ĄŪŹ¨ŪėēžĚė ž†ĀŪē©ŽŹĄ Í≤Äž†ē ŪÜĶÍ≥ľ žßÄž†ź žąėŽäĒ ÍįôÍ≤Ć ŽāėŪÉÄŽā¨Žč§. ŽėźŪēú, GUM, GEV, GLO, BUR Ž∂ĄŪŹ¨ŪėēžĚÄ Ž™®Žď† žßÄž†źžóźžĄú K-S testŽ•ľ ŪÜĶÍ≥ľŪēėŽäĒ Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§. žĚīŽäĒ žßÄžÜćžčúÍįĄ 24žčúÍįĄ ÍįēžöįžěźŽ£ĆžĚė ŽĻąŽŹĄŪēīžĄĚžóźŽäĒ GUM Ž∂ĄŪŹ¨Ūėē Ž≥īŽč§ŽäĒ GEV, GLO, BUR Ž∂ĄŪŹ¨ŪėēžĚĄ žĚīžö©ŪēėŽäĒ Í≤ÉžĚī Í∑ĻžĻė žąėŽ¨łžěźŽ£ĆžĚė ŪÜĶÍ≥Ąž†Ā ŪäĻžĄĪžĚĄ ŽāėŪÉÄŽāīŽäĒŽćį ž†ĀŪē©Ūē† Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§. ŽėźŪēú, BUR Ž∂ĄŪŹ¨ŪėēžĚÄ GEV, GLO Ž∂ĄŪŹ¨ŪėēÍ≥ľ ŽŹôžĚľŪēú žßÄž†źŽď§žóźžĄú ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ ŪÜĶÍ≥ľŪēėŽäĒ Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨žúľŽ©į, ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ ŪÜĶÍ≥ľŪēú žßÄž†źžóź ŽĆÄŪēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚĄ ž†Āžö©Ūēėžó¨ ŪôēŽ•†ÍįēžöįŽüȞ̥ žāįž†ēŪēėŽäĒ Í≤Éžóź Ž¨łž†úÍįÄ žóܞ̥ Í≤ÉžúľŽ°ú žÉĚÍįĀŽźúŽč§.
Table 2žóźŽäĒ ž†ĀŪē©ŽŹĄ Í≤Äž†ē žčú ÍįÄžě• žěĎžĚÄ Í≤Äž†ēŪÜĶÍ≥ĄŽüČžúľŽ°ú Í≤Äž†ēžĚĄ ŪÜĶÍ≥ľŪēú žĶúž†ĀžĚė Ž∂ĄŪŹ¨ŪėēžĚĄ žĄ†ž†ēŪēėžėÄÍ≥†, ÍįĀ Ž∂ĄŪŹ¨ŪėēŽ≥ĄŽ°ú žĄ†ž†ēŽźú žßÄž†ź žąėŽ•ľ ž†ēŽ¶¨ŪēėžėÄŽč§. žĚľŽįėž†ĀžúľŽ°ú K-S test Ž≥īŽč§ ÍłįÍįĀŽ†•žĚī žöįžąėŪēėŽč§Í≥† žēĆŽ†§žßĄ Ōá2-test Í≤įÍ≥ľŽ•ľ žāīŪéīŽ≥īŽ©ī GEV Ž∂ĄŪŹ¨ŽäĒ 296ÍįúŽ°ú ÍįÄžě• ŽßéžĚÄ žßÄž†źžóźžĄú Í≤Äž†ēŪÜĶÍ≥ĄŽüČ ÍįížĚī ÍįÄžě• žěĎÍ≤Ć ŽāėŪÉÄŽā¨Žč§. BUR Ž∂ĄŪŹ¨ŽäĒ 101ÍįúŽ°ú GUM Ž∂ĄŪŹ¨Ūėē Ž≥īŽč§ Ž≥īŽč§ ž†ĀžßÄŽßĆ GLO Ž∂ĄŪŹ¨Ūėē Ž≥īŽč§ŽäĒ ŽßéžĚÄ žßÄž†źžóźžĄú žĄ†ž†ēŽźėžóąŽč§. ŽėźŪēú, K-S testžóźžĄúŽäĒ BUR Ž∂ĄŪŹ¨ÍįÄ 174Íįú žßÄž†źžóźžĄú Í≤Äž†ē ŪÜĶÍ≥ĄŽüČ ÍįížĚī ÍįÄžě• žěĎÍ≤Ć ŽāėŪÉÄŽā¨Í≥†, GEV Ž∂ĄŪŹ¨Ūėēžóź žĚīžĖī ŽĎź Ž≤ąžßłŽ°ú ŽßéžĚÄ žßÄž†źžóźžĄú žĄ†ž†ēŽźú Í≤ɞ̥ ŪôēžĚłŪē† žąė žěąŽč§.
3.3 Monte Carlo Ž™®žĚėžč§Ūóė
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ ÍįĀ Ž∂ĄŪŹ¨Ūėēžóź ŽĆÄŪēú ž†Āžö©žĄĪžĚĄ Í≤ÄŪ܆ŪēėÍłį žúĄŪēėžó¨ Monte Carlo Ž™®žĚėžč§ŪóėžĚĄ žąėŪĖČŪēėžėÄÍ≥†, ÍīÄžł°ÍįížúľŽ°ú ž∂Ēž†ēŽźú Žß§ÍįúŽ≥ÄžąėŽäĒ kappa Ž∂ĄŪŹ¨Ūėēžóź ž†ĀŪē©žčúžľú Ž™®žĚėžěźŽ£ĆŽ•ľ ŽįúžÉĚžčúžľįŽč§(Hosking and Wallis, 1997). 500ŪöĆ ŽįėŽ≥ĶžąėŪĖČŪēėžó¨ žĖĽžĖīžßĄ Ž™®žĚėŽįúžÉĚ ÍįížĚĄ ÍįĀ Ž∂ĄŪŹ¨Ūėēžóź ž†Āžö©Ūēėžó¨ log likelihood ÍįížĚĄ žāįž†ēŪēėžėÄŽč§. Table 3žĚÄ Ž™®žĚėŽįúžÉĚŪēú žěźŽ£ĆŽ•ľ žĚīžö©Ūēėžó¨ log likelihood ÍįížĚĄ ÍįĀ Ž∂ĄŪŹ¨ŪėēŽ≥ĄŽ°ú žāįž†ēŪēėžó¨ ŽĻĄÍĶźŪēėžėĞ̥ ŽēĆ žĪĄŪÉĚŽźú ŪöüžąėŽ•ľ ŽāėŪÉÄŽāł Í≤ÉžúľŽ°ú, GEV Ž∂ĄŪŹ¨ŪėēžĚī 617Íįú žßÄž†ź ž§ĎžóźžĄú 447Íįú žßÄž†ź(žēĹ 72.45%)žóźžĄú 1žąúžúĄ(First)Ž°ú žĪĄŪÉĚŽźėžóąŽč§ Žč§žĚĆžúľŽ°ú BUR Ž∂ĄŪŹ¨ŪėēžĚÄ 170Íįú žßÄž†ź(žēĹ 27.55%)žóźžĄú 1žąúžúĄŽ°ú žĪĄŪÉĚŽźėžóąžúľŽ©į, GUM, GLO Ž∂ĄŪŹ¨ŪėēžĚÄ 1žąúžúĄŽ°ú žĪĄŪÉĚŽźú žßÄž†źžĚī žóÜŽäĒ Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§. GEV Ž∂ĄŪŹ¨ŪėēžĚĄ 1žąúžúĄŽ°ú žĪĄŪÉĚŪēú žßÄž†ź ž§Ď 2žąúžúĄ(Second)Ž°ú BUR Ž∂ĄŪŹ¨ŪėēžĚī žĪĄŪÉĚŽźú žßÄž†źžĚÄ 294ÍįúžĚīÍ≥†, GUM Ž∂ĄŪŹ¨ŪėēÍ≥ľ GLO Ž∂ĄŪŹ¨ŪėēžĚÄ ÍįĀÍįĀ 111Íįú, 42Íįú žßÄž†źžóźžĄú žĪĄŪÉĚŽźėžóąŽč§. ŽėźŪēú BUR Ž∂ĄŪŹ¨ŪėēžĚĄ 1žąúžúĄŽ°ú žĪĄŪÉĚŪēú žßÄž†ź ž§Ď 2žąúžúĄŽ°ú GEV Ž∂ĄŪŹ¨ŪėēžĚÄ 158Íįú žßÄž†ź, GLO Ž∂ĄŪŹ¨ŪėēžĚÄ 17Íįú žßÄž†źžóźžĄú žĪĄŪÉĚŽźėžóąŽč§. BUR Ž∂ĄŪŹ¨ŪėēžĚÄ GEV Ž∂ĄŪŹ¨Ūėēžóź žĚīžĖīžĄú žĪĄŪÉĚŽĻĄžú®žĚī ŽĎź Ž≤ąžßłŽ°ú ŽÜíÍ≤Ć ŽāėŪÉÄŽāėŽ©į Žč§Ž•ł Ž∂ĄŪŹ¨Ūėē(GUM, GLO)Í≥ľ ŽĻĄÍĶźŪēėžó¨ žöįŽ¶¨ŽāėŽĚľ Í∑ĻžĻė žąėŽ¨łžěźŽ£ĆžĚė ŪÜĶÍ≥Ąž†Ā ŪäĻžĄĪžĚĄ žěė ŽāėŪÉÄŽāīŽäĒ Í≤ÉžúľŽ°ú žÉĚÍįĀŽźúŽč§. ž¶Č, BUR Ž∂ĄŪŹ¨ŪėēžĚÄ žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£Ć ŽĻąŽŹĄŪēīžĄĚžóź ž†Āžö©žĚī ÍįÄŽä•Ūē† Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§.
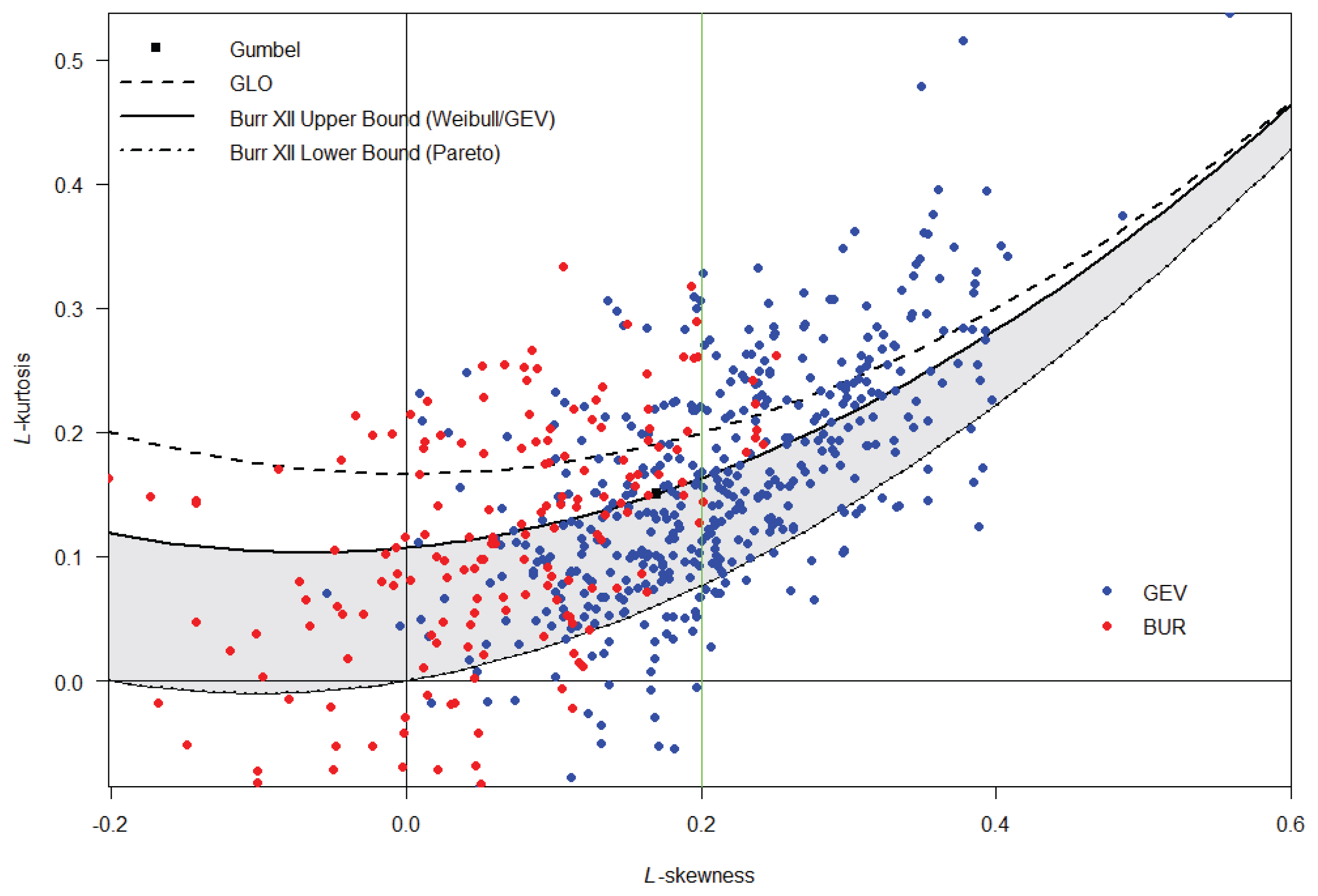
L-moment ratio diagramžĚÄ ŪôēŽ•†Ž∂ĄŪŹ¨ŪėēŽ≥ĄŽ°ú ÍįĖŽäĒ Í≥†žú†žĚė L-moment ratiožôÄ ž£ľžĖīžßĄ ŪĎúŽ≥ł žěźŽ£ĆžĚė ÍįížĚĄ ŽĻĄÍĶźŪēėžó¨ ž†Āž†ēŪôēŽ•†Ž∂ĄŪŹ¨ŪėēžĚĄ žĄ†ž†ēŪēėŽäĒ ŪĆźŽč®žĚė Íłįž§ÄžĚĄ ž†úÍ≥ĶŪēúŽč§Í≥† Ūē† žąė žěąŽč§. Fig. 3žĚÄ 617Íįú žßÄž†źžóź ŽĆÄŪēėžó¨ L-moment ratio (L-skewness, L-kurtosis)Ž•ľ ŽāėŪÉÄŽāł Í∑łŽ¶ľžúľŽ°ú ÍįĀ žßÄž†źŽ≥ĄŽ°ú žĪĄŪÉĚŽźú Ž∂ĄŪŹ¨Ūėēžóź ŽĆÄŪēėžó¨ ÍįĀÍįĀ ŪĆĆŽěÄžÉČ(GEV), ŽĻ®ÍįĄžÉČ(BUR)žúľŽ°ú ŽāėŪÉÄŽÉąŽč§. GEV Ž∂ĄŪŹ¨ŪėēžĚÄ L-skewnessÍįÄ 0.1Ž≥īŽč§ ŪĀį Í≤Ĺžöį ŽßéžĚÄ žßÄž†źžóź ž†Āžö©ÍįÄŽä•ŪēėŽ©į, ž†Āžö©Ūēú Ž∂ĄŪŹ¨Ūėē ž§ĎžóźžĄúŽäĒ ÍįÄžě• žöįžąėŪēėÍ≥† Žč§žĖĎŪēú Ž≤ĒžúĄžóźžĄú ž†Āžö©žĚī ÍįÄŽä•Ūēú Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§. BUR Ž∂ĄŪŹ¨ŪėēžĚÄ 2ÍįúžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ°ú ÍĶ¨žĄĪŽźėžĖī žěąžĖī ž†Āž†ēŪēú Ž≤ĒžúĄÍįÄ žėĀžó≠žúľŽ°ú ŽāėŪÉÄŽāėŽ©į ž£ľŽ°ú L-skewnessÍįÄ 0.2 žĚīŪēėžĚł Í≤Ĺžöįžóź ŽßéžĚÄ žßÄž†źžóź ž†Āžö© ÍįÄŽä•Ūēú Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§.
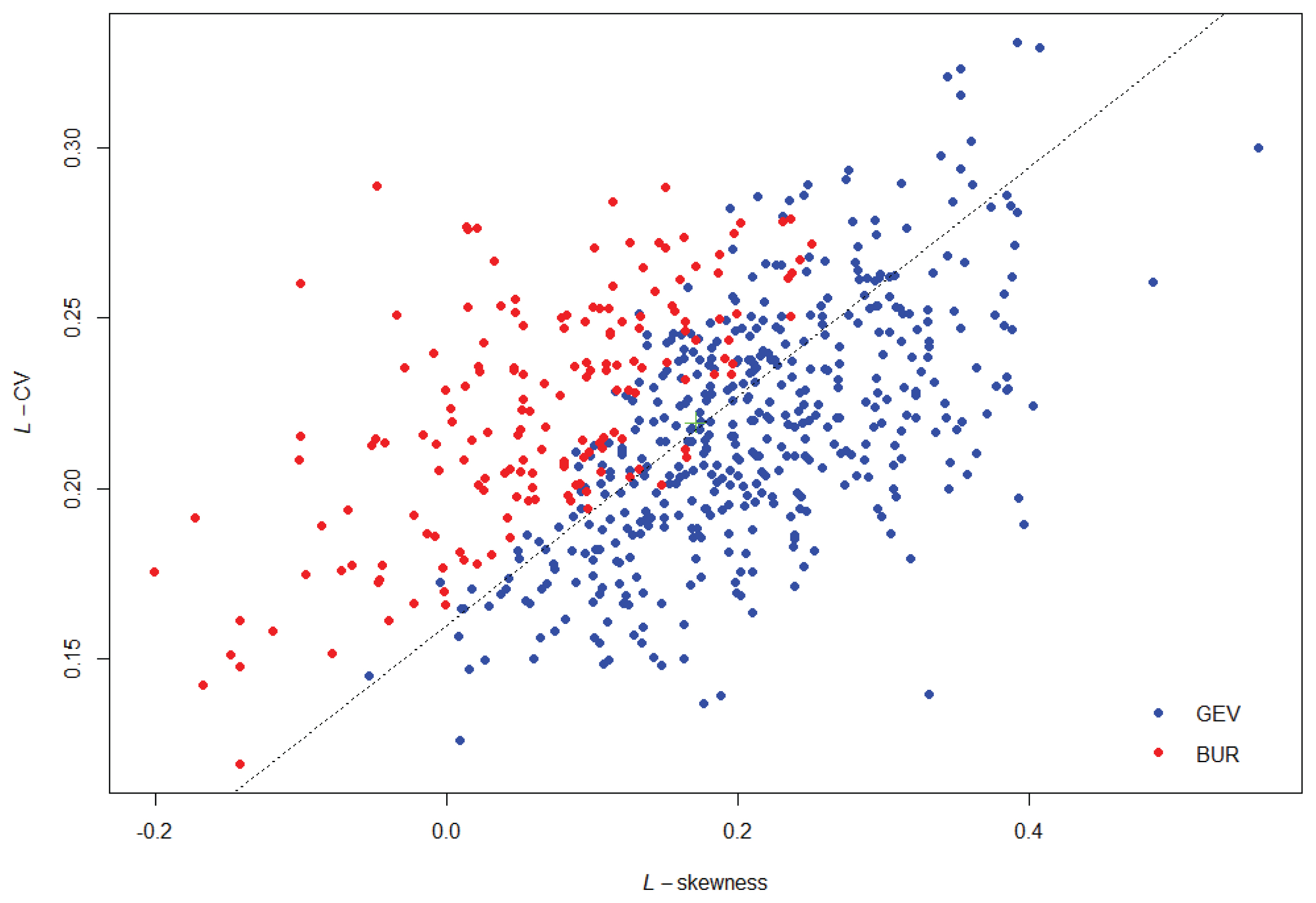
Fig. 4ŽäĒ L-moment ratio (L-CV, L-kurtosis)Ž•ľ ŽāėŪÉÄŽāł Í∑łŽ¶ľžúľŽ°ú ÍįĀ žßÄž†źŽ≥ĄŽ°ú 1žąúžúĄŽ°ú žĪĄŪÉĚŽźú Ž∂ĄŪŹ¨ŪėēžĚÄ Fig. 3Í≥ľ ŽŹôžĚľŪēėŽč§. Fig. 3 Ž≥īŽč§ŽäĒ žĘÄ ŽćĒ Ž™ÖŪôēŪēėÍ≤Ć Ž∂ĄŪŹ¨ŪėēŽ≥ĄŽ°ú ž†Āž†ēŽ≤ĒžúĄÍįÄ ŽāėŪÉÄŽāėÍ≥† žěąŽč§. L-skewnessÍįÄ 0.2Ž≥īŽč§ žěĎžĚÄ Ž≤ĒžúĄžóźžĄúŽäĒ L-CVÍįížĚī ŪĀį Í≤Ĺžöį GEV Ž∂ĄŪŹ¨ŪėēŽ≥īŽč§ BURR Ž∂ĄŪŹ¨ŪėēžĚī žĪĄŪÉĚŽź† ÍįÄŽä•žĄĪžĚī ŽćĒ ŽÜížĚÄ Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§.
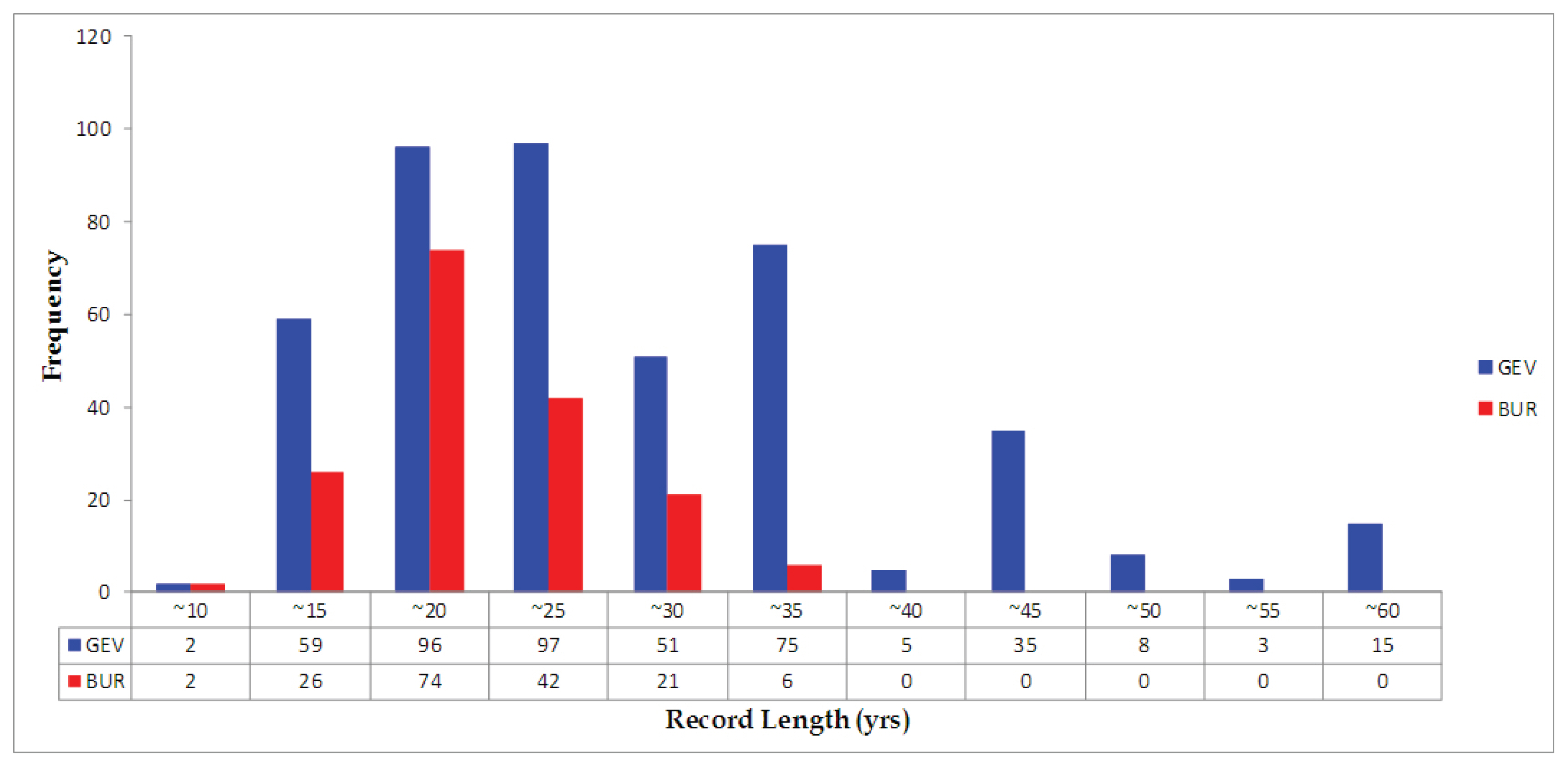
Fig. 5ŽäĒ 617Íįú žßÄž†źžóźžĄú žĪĄŪÉĚŽźú GEV, BUR Ž∂ĄŪŹ¨ŪėēžĚĄ žßÄŽŹĄžÉĀžóź ŪĎúÍłįŪēėžó¨ ŽāėŪÉÄŽāīžóąŽč§. GEV, BUR Ž∂ĄŪŹ¨Ūėē Ž™®ŽĎź Í≥ĶÍįĄž†ĀžúľŽ°ú Í≥†Ž•īÍ≤Ć Ž∂ĄŪŹ¨ŪēėžėÄžúľŽ©į, žßÄž†źŽ≥ĄŽ°ú ž†ĀŪē©ŪēėŽč§Í≥† žĄ†ŪÉĚŽźú Ž∂ĄŪŹ¨Ūėēžóź ŽĆÄŪēú Í≥ĶÍįĄž†ĀžĚł žÉĀÍīÄžĄĪžĚÄ ž†ĀžĚÄ Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§. žĪĄŪÉĚŽźú Ž∂ĄŪŹ¨Ūėēžóź ŽĆÄŪēėžó¨ ÍįĀ žßÄž†źŽ≥Ą žěźŽ£ĆŽÖĄžąėžĚė ŽĻąŽŹĄŽäĒ Fig. 6Í≥ľ ÍįôžĚī ŽāėŪÉÄŽā¨žúľŽ©į, žěźŽ£ĆŽÖĄžąėŽäĒ 9ŽÖĄŽ∂ÄŪĄį 57ŽÖĄÍĻĆžßÄ žßÄž†źŽ≥ĄŽ°ú Žč§žĖĎŪēėžėÄŽč§. ÍįēžöįžěźŽ£ĆžĚė ÍłįÍįĄžĚī 30ŽÖĄ žĚīžÉĀžĚł 147Íįú žßÄž†ź ž§Ď 141Íįú žßÄž†źžĚÄ GEV Ž∂ĄŪŹ¨ŪėēžĚī ŽćĒ ž†ĀŪē©ŪēėŽč§Í≥† ŽāėŪÉÄŽā¨Í≥†, BUR Ž∂ĄŪŹ¨ŪėēžĚĄ žĪĄŪÉĚŪēú 6Íįú žßÄž†ź ž§Ď ÍįÄžě• Íłī žěźŽ£ĆÍłįÍįĄžĚÄ 35ŽÖĄžĚīŽč§. ž¶Č, žěźŽ£ĆÍłįÍįĄžĚī Íłī žßÄž†źžóźžĄúŽäĒ ŽĆÄž≤īŽ°ú GEV Ž∂ĄŪŹ¨ŪėēžĚī ž†ĀŪē©Ūēú Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§.
4. Í≤į Ž°†
Ž≥ł žóįÍĶ¨ŽäĒ ŽĎź ÍįúžĚė ŪėēžÉĀŽß§ÍįúŽ≥ÄžąėŽ•ľ ÍįÄžßÄÍ≥† žěąžĖī Žč§žĖĎŪēú ŪÜĶÍ≥ĄŽüȞ̥ žú†žóįŪēėÍ≤Ć ŪĎúŪėĄŪē† žąė žěąŽč§Í≥† žēĆŽ†§žßĄ BUR Ž∂ĄŪŹ¨ŪėēžĚĄ žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£Ćžóź ž†Āžö©Ūēėžó¨ žā¨žö© ÍįÄŽä•žĄĪžĚĄ žāīŪéīŽ≥īÍ≥†žěź ŪēėžėÄŽč§. žöįŽ¶¨ŽāėŽĚľ 617Íįú žßÄž†źžĚĄ ŽĆÄžÉĀžúľŽ°ú žĚľŽįėž†ĀžúľŽ°ú žöįŽ¶¨ŽāėŽĚľ ÍįēžöįžěźŽ£Ćžóź ž†ĀŪē©ŪēėŽč§Í≥† žēĆŽ†§žßĄ GEV, GUM, GLO Ž∂ĄŪŹ¨ ŽďĪÍ≥ľ Ūē®ÍĽė ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ žąėŪĖČŪēėžėÄÍ≥†, Monte Carlo Ž™®žĚėžč§ŪóėžĚĄ ŪÜĶŪēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚė ž†Āžö© ÍįÄŽä•žĄĪžĚĄ ž†ēŽüČž†ĀžúľŽ°ú ŪŹČÍįÄŪēėžėÄŽč§. Ž≥ł žóįÍĶ¨Ž•ľ ŪÜĶŪēėžó¨ žēĄŽěėžôÄ ÍįôžĚÄ Í≤įÍ≥ľŽ•ľ žĖĽžĚĄ žąė žěąžóąŽč§.
(1) ž†Āžö©Ūēú ŪôēŽ•†Ž∂ĄŪŹ¨Ūėēžóź ŽĆÄŪēú Žß§ÍįúŽ≥ÄžąėŽäĒ L-momentŽ≤ēžĚĄ žĚīžö©Ūēėžó¨ ž∂Ēž†ēŪēėžėÄÍ≥† Ōá2-testžôÄ K-S test Žį©Ž≤ēžĚĄ žĚīžö©Ūēėžó¨ ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ žąėŪĖČŪēėžėÄŽč§. Í∑ł Í≤įÍ≥ľ GUM Ž∂ĄŪŹ¨ŪėēžĚė ž†ĀŪē©ŽŹĄ Í≤Äž†ē ŪÜĶÍ≥ľžú®žĚī ÍįÄžě• ŽāģÍ≤Ć ŽāėŪÉÄŽā¨Í≥†, BUR Ž∂ĄŪŹ¨ŪėēžĚÄ GEV, GLO Ž∂ĄŪŹ¨ŪėēÍ≥ľ ŽĻĄÍĶźŪēėžó¨ ŪĀį žį®žĚīÍįÄ ŽāėžßÄ žēäŽäĒ Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§. ž†ĀŪē©ŽŹĄ Í≤Äž†ēžĚĄ ŪÜĶÍ≥ľŪēú Ž∂ĄŪŹ¨ŪėēŽ≥Ą Í≤Äž†ēŪÜĶÍ≥ĄŽüȞ̥ ŽĻĄÍĶźŪēú Í≤įÍ≥ľ GEV Ž∂ĄŪŹ¨ŪėēžĚī ÍįÄžě• ŽßéžĚÄ žßÄž†źžóźžĄú žěĎÍ≤Ć žāįž†ēŽźėžóąÍ≥†, ž†ĀŪē©ŽŹĄ Í≤Äž†ē Žį©Ž≤ēžóź ŽĒįŽĚľ BUR Ž∂ĄŪŹ¨ŪėēžĚÄ ŽĎź Ž≤ąžßł(K-S) ŽėźŽäĒ žĄł Ž≤ąžßł(CS)Ž°ú žěĎÍ≤Ć žāįž†ēŽźėžóąŽč§.
(2) Monte Carlo Ž™®žĚėžč§ŪóėžĚĄ ŪÜĶŪēėžó¨ ÍįĀ Ž∂ĄŪŹ¨ŪėēžĚė log likelihoodÍįížĚĄ ŽĻĄÍĶźŪēú Í≤įÍ≥ľ GEV Ž∂ĄŪŹ¨ŪėēžĚī ÍįÄžě• ŽßéžĚÄ žßÄž†źžóźžĄú ž†Āž†ąŪēú Ž∂ĄŪŹ¨ŪėēžúľŽ°ú žĪĄŪÉĚŽźėžóąÍ≥†, Í∑ł Ží§Ž•ľ žĚīžĖī BUR Ž∂ĄŪŹ¨ŪėēžĚī ž†Āž†ąŪēú Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§. ŽėźŪēú BUR Ž∂ĄŪŹ¨ŪėēžĚė L-skewness ÍįížĚī 0.2 žĚīŪēėžĚīŽ©į L-CV ÍįížĚė ÍīÄÍ≥Ąžóź ŽĒįŽĚľ ž†Āžö© ÍįÄŽä•žĄĪžĚī žĽ§žßÄŽ©į, žöįžąėŪēú Í≤įÍ≥ľŽ•ľ ŽŹĄž∂úŪē† žąė žěąžĚĄ Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§.
(3) ÍįĀ žßÄž†źŽ≥ĄŽ°ú ž†ĀŪē©ŪēėŽč§Í≥† žĪĄŪÉĚŽźú Ž∂ĄŪŹ¨ŪėēžĚĄ Í≥ĶÍįĄž†ĀžúľŽ°ú Í≤ÄŪ܆Ūēú Í≤įÍ≥ľ Í≥ĶÍįĄžÉĀÍīÄžĄĪžĚÄ ž†ĀžĚÄ Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Í≥†, 30ŽÖĄ žĚīžÉĀžĚė Íłī žěźŽ£ĆÍłįÍįĄžĚī žěąŽäĒ žßÄž†źžóźžĄúŽäĒ GEV Ž∂ĄŪŹ¨ŪėēžĚī BUR Ž∂ĄŪŹ¨Ūėē Ž≥īŽč§ ž†ĀŪē©Ūēú Í≤ÉžúľŽ°ú ŽāėŪÉÄŽā¨Žč§.
(4) GUM, GEV, GLO Ž∂ĄŪŹ¨ŪėēžĚÄ žöįŽ¶¨ŽāėŽĚľ Íįēžöį žěźŽ£Ćžóź ŽĻĄÍĶźž†Ā ž†ĀŪē©ŪēėŽč§Í≥† žēĆŽ†§ž†ł žěąÍ≥†, ŽĄźŽ¶¨ žā¨žö©ŽźėÍ≥† žěąŽäĒ Ž∂ĄŪŹ¨ŪėēžĚīŽč§. Ž≥ł žóįÍĶ¨žóźžĄú ž†úžčúŪēú BUR Ž∂ĄŪŹ¨ŪėēžĚÄ Íłįž°īžĚė Žč§Ž•ł Ž∂ĄŪŹ¨ŪėēÍ≥ľ Ūē®ÍĽė ŽĻĄÍĶźŪēėžó¨ žöįŽ¶¨ŽāėŽĚľ Íįēžöį žěźŽ£ĆžĚė ŽĻąŽŹĄŪēīžĄĚžóź ž†Āžö©ŪēėŽäĒ ŽćįžóźŽäĒ Ž¨łž†úÍįÄ žóܞ̥ Í≤ÉžúľŽ°ú ŪĆźŽč®ŽźúŽč§. Íłįž°īžĚė Ž∂ĄŪŹ¨ŪėēžĚī ž†ĀŪē©ŪēėžßÄ žēäžĚÄ žßÄž†źžóź ŽĆÄŪēėžó¨ BUR Ž∂ĄŪŹ¨ŪėēžĚĄ ž†Āžö©Ūē† Í≤Ĺžöį, Ž≥īŽč§ ž†ĀŪē©Ūēú ŪôēŽ•†žąėŽ¨łŽüȞ̥ žāįž†ēŪēėŽäĒŽćį ŽŹĄžõÄžĚī Žź† Í≤ÉžúľŽ°ú ÍłįŽĆÄŽźúŽč§.