1. ΉΕε Έκι
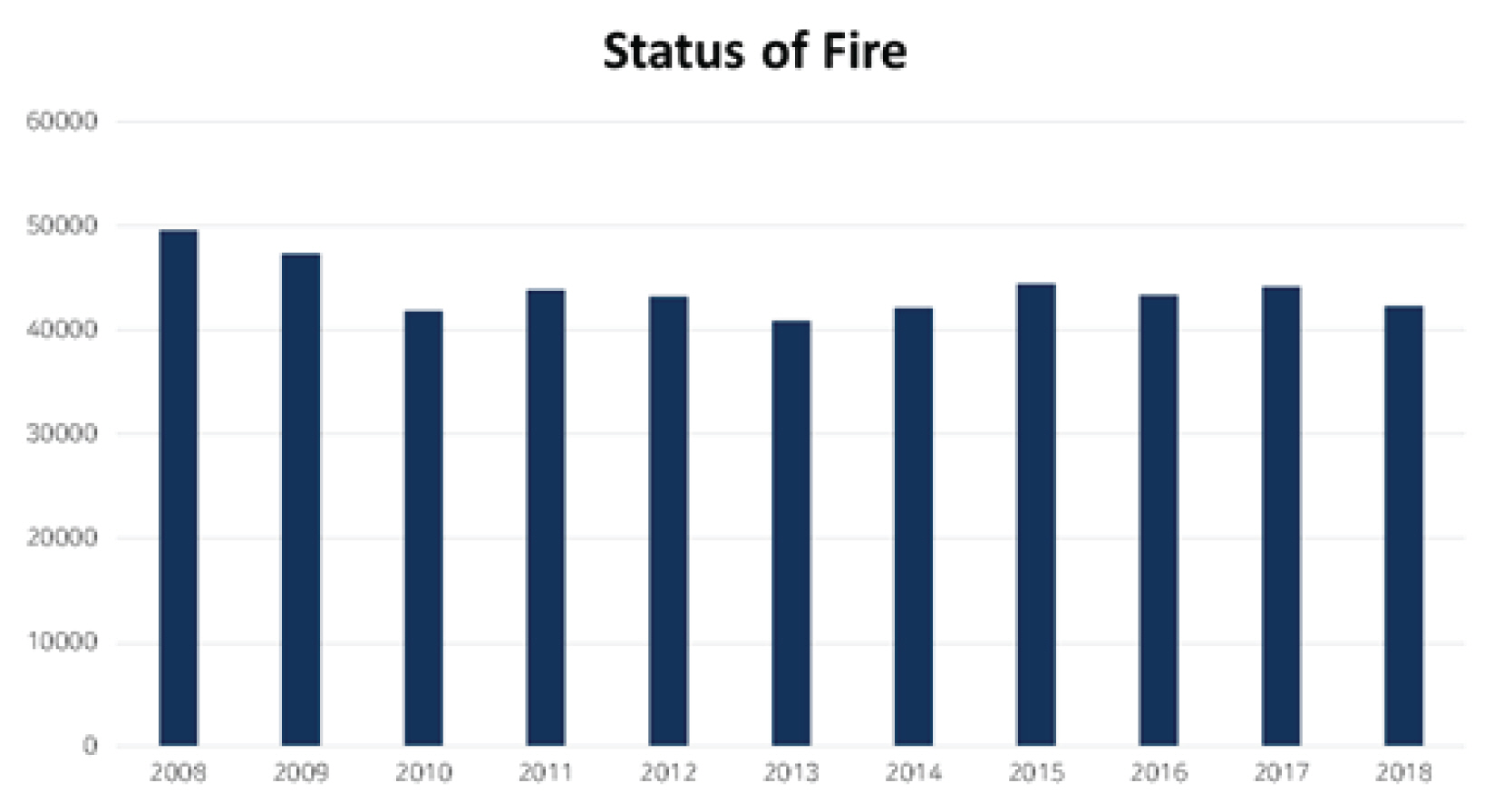
Ή╡εΆ╖╝ 10ΈΖΕ Ά░Ε ΈπνΈΖΕ 40,000Ά▒┤ Ήζ┤ΉΔΒΉζα ΊβΦΉηυΉΓυΆ│ιΆ░Α Έ░εΉΔζΊΧαΆ│ι ΉηΙΉε╝Έσ░(Fig. 1), Ήζ┤ ΉΓυΆ│ιΈκε Ήζ╕ΊΧαΉΩυ ΈπνΉζ╝ 6ΈςΖΉζα Ήζ╕ΈςΖΊΦ╝ΊΧ┤ Έ░Π 127ΈπΝΉδΡΉζα ΉηυΉΓ░ΊΦ╝ΊΧ┤Ά░Α Έ░εΉΔζΊΧαΆ│ι ΉηΙΈΜν. Ά│ΕΉΗΞΊΧ┤ΉΕε Έ░εΉιΕΊΧαΈΛΦ ΉΗΝΈ░σΉΜεΉΛνΊΖεΉΩΡΈΠΕ Έ╢ΙΆ╡υΊΧαΆ│ι ΊβΦΉηυΉΓυΆ│ι Έ░εΉΔζΉζΑ ΉνΕΉΨ┤ΈΥνΉπΑ ΉΧΛΆ│ι ΉηΙΉε╝Έσ░ ΊβΦΉηυΉΓυΆ│ι ΊΛ╣ΉΕ▒ΉΔΒ ΉΓυΆ│ιΈ░εΉΔζΉζΕ ΉνΕΉζ┤Ά╕░ ΉεΕΊΧε ΈςΖΊβΧΊΧε ΈΝΑΉ▒ΖΉΙαΈο╜Ήζ┤ Έ╢ΙΆ░ΑΈΛξΊΧαΈΜν. ΊΧσΈουΉιΒΉζ╕ ΉΗΝΈ░σΉιΧΉ▒ΖΈΝΑΉΧΙΉζΕ ΉΙαΈο╜ΊΧαΆ╕░ ΉεΕΊΧ┤ Ά╡φΆ░ΑΊβΦΉηυΉιΧΈ│┤ΉΜεΉΛνΊΖε(NFDS)ΉζΑ 2007ΈΖΕΈΠΕΈ╢ΑΊΕ░ Ά░ΒΉλΖ ΊβΦΉηυΉιΧΈ│┤ ΈΞ░Ήζ┤ΊΕ░Έξ╝ Ή╢ΧΉιΒΊΧαΆ╕░ ΉΜεΉηΣΊΧαΉαΑΉε╝Έσ░, ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΊβεΉγσΊΧε ΊβΦΉηυΉιΧΈ│┤ Έ░Π ΊβΦΉηυΊΗ╡Ά│Ε Έ╢ΕΉΕζΉΩΡ Ά┤ΑΊΧε ΉΩ░Ά╡υΈΥνΉζ┤ ΊβεΈ░εΊΧαΆ▓Ν ΉπΕΊΨΚΈΡαΆ│ι ΉηΙΈΜν.
NFDSΈΛΦ 1ΈΖΕ 6Ά░εΉδΦ ΈΠβΉΧΙ ΉΙαΉπΣΊΧε ΈΞ░Ήζ┤ΊΕ░Έξ╝ Ά╕░Έ░αΉε╝Έκε ΊβΦΉηυΉεΕΊΩα ΉαΙΉ╕κΈςρΈΞ╕ΉζΕ Ά░εΈ░εΊΧαΉαΑΆ│ι ΊβΦΉηυΉζα ΉεΕΊΩαΉιΧΈΠΕΈξ╝ ΊΣεΊαΕΊΧαΆ╕░ ΉεΕΊΧ┤ ΊβΦΉηυΉεΕΊΩαΉπΑΉΙα(Chang et al., 2008)Έξ╝ Ά░εΈ░εΊΧαΉαΑΈΜν. ΊβΦΉηυΉεΕΊΩαΉπΑΉΙαΈξ╝ ΊγΝΆ╖ΑΈ╢ΕΉΕζΉζΕ Ά╕░Έ░αΉε╝Έκε ΉΙαΊΧβΉιΒ ΈςρΈΞ╕ΉζΕ ΉΔζΉΕ▒ΊΧαΉΩυ ΈΓαΊΔΑΈΓ┤ΉΩΙΈΛΦΈΞ░ ΊγΝΆ╖ΑΈ╢ΕΉΕζ ΊΛ╣ΉΕ▒ΉΔΒ ΊβΦΉηυ ΉεΕΊΩαΉζΕ ΊβΦΉηυ ΉγΦΉζ╕ Ά░ΕΉζα ΉΕιΊαΧΆ┤ΑΆ│ΕΈκε ΊΣεΊαΕΊΧαΉΩυ ΊβΦΉηυΉζα Έ│╡ΉηκΊΧε ΊαΕΉΔΒΉζΕ ΉιεΈΝΑΈκε ΊΣεΊαΕΊΧαΉπΑ Ές╗ΊΧαΈΛΦ ΊΧεΆ│ΕΆ░Α ΉηΙΈΜν.
Ryu and Kim (2012)ΉζΑ ΊβΦΉηυ Έ░εΉΔζΉΩΡ ΉαΒΊΨξΉζΕ Έψ╕Ή╣αΈΛΦ ΉγΦΉζ╕Έ╢ΕΉΕζΉζΕ ΉΧΝΉΧΕΈ│┤Ά╕░ ΉεΕΊΧαΉΩυ ΉζαΉΓυΆ▓░ΉιΧΊΛ╕ΈουΈκε ΊβΦΉηυ ΉαΙΉ╕κ ΈςρΈΞ╕ΉζΕ ΉΔζΉΕ▒ΊΧαΉΩυ ΉΛ╡ΈΠΕΆ░Α ΊβΦΉηυΉβΑ ΉΩ░Ά┤ΑΉΕ▒Ήζ┤ ΈΗΤΈΜνΈΛΦ Ά▓ΔΉζΕ ΉΩ░Ά╡υΊΧαΉαΑΉε╝Έσ░, Kim et al. (2013) ΉζΑ ΉζαΉΓυΆ▓░ΉιΧΊΛ╕ΈουΈξ╝ ΊβεΉγσΊΧαΉΩυ ΉπΑΉΩφΈ│Ε ΊβΦΉηυΊβΧΈξιΉζΕ ΉαΙΉ╕κΊΧαΈΛΦ ΈςρΈΞ╕ΉζΕ ΉΔζΉΕ▒ΊΧαΉΩυ Brier ΉιΡΉΙαΈξ╝ ΊΗ╡ΊΧ┤ ΉαΙΉ╕κ ΈςρΈΞ╕Ήζα ΉΕ▒ΈΛξΉζΕ Ά▓ΑΉοζΊΧαΉαΑΈΜν. ΊΧαΉπΑΈπΝ ΉζαΉΓυΆ▓░ΉιΧΊΛ╕ΈουΈξ╝ ΊβεΉγσΊΧε ΉαΙΉ╕κ ΈςρΈΞ╕ΉζΑ ΈΜρΆ│ΕΈ│ΕΈκε ΊΧε Ά░εΉζα ΊβΦΉηυ ΉγΦΉζ╕Έ│ΑΉΙαΈπΝΉζΕ Ά│ιΈινΊΧαΉΩυ Έ╢ΕΈξαΊΧεΈΜνΈΛΦ ΉιΡΉΩΡΉΕε ΊβΦΉηυ ΉγΦΉζ╕Έ│ΑΉΙα Ά░ΕΉζα Ά┤ΑΆ│ΕΈξ╝ Ά│ιΈινΊΧι ΉΙα ΉΩΗΈΜνΈΛΦ ΊΧεΆ│ΕΆ░Α ΉηΙΈΜν.
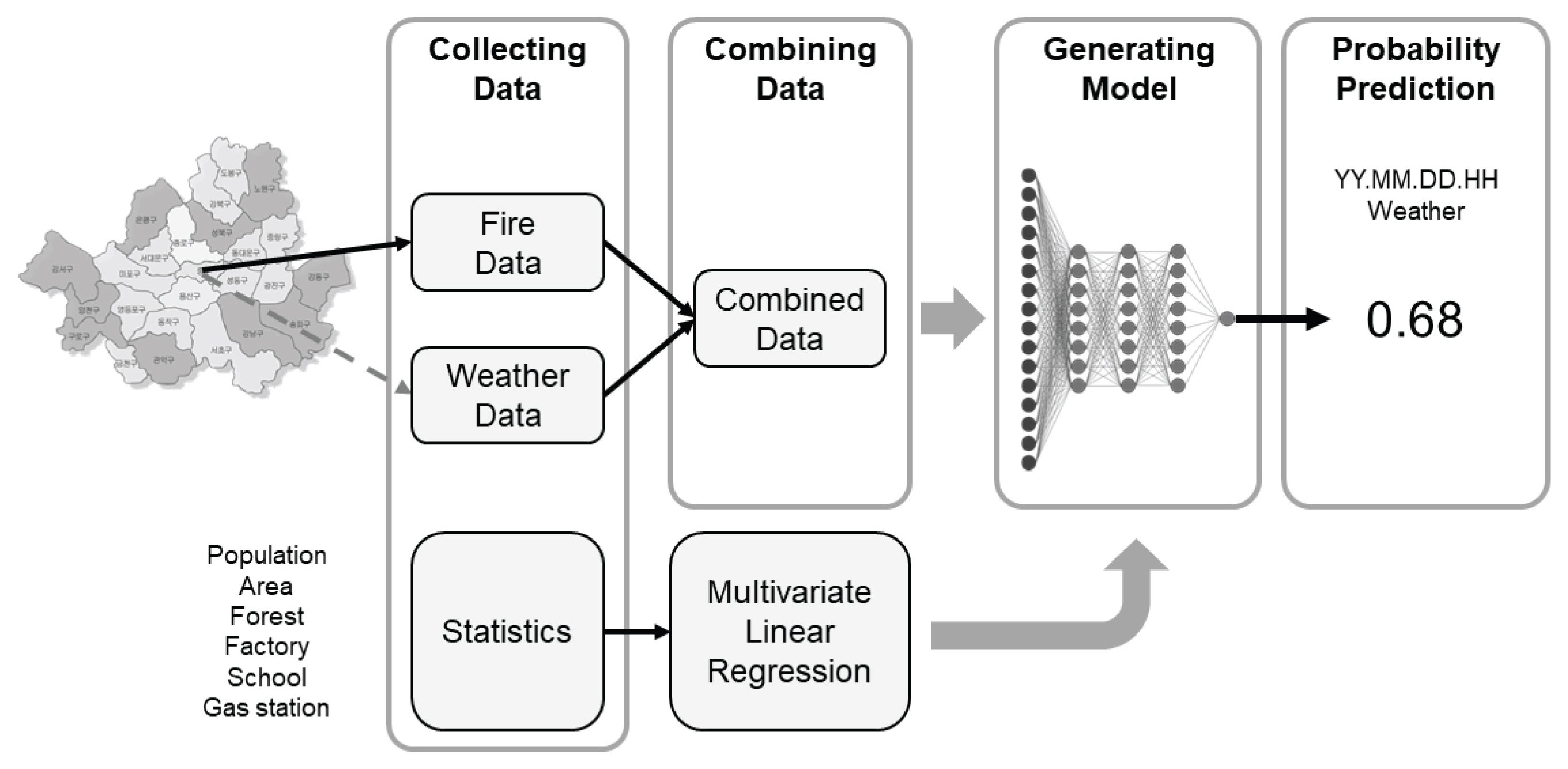
ΈΦ░Έζ╝ΉΕε Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ ΉγΦΉζ╕Έ│ΑΉΙα Ά░Ε Έ│╡ΉηκΊΧε Ά┤ΑΆ│ΕΈξ╝ Ά│ιΈινΊΧι ΉΙα ΉηΙΈΛΦ Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΈςρΈΞ╕ΉζΕ ΊβεΉγσΊΧαΉΩυ ΊβΦΉηυΊβΧΈξιΉζΕ ΉαΙΉ╕κΊΧι ΉΙα ΉηΙΈΛΦ ΈςρΈΞ╕ΉζΕ Ά╡υΉ╢ΧΊΧαΉαΑΈΜν. 2008ΈΖΕΈ╢ΑΊΕ░ 2017ΈΖΕΆ╣ΝΉπΑΉζα ΊβΦΉηυΈΞ░Ήζ┤ΊΕ░ΉβΑ Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░Έξ╝ ΊΗ╡ΊΧσΊΧαΉΩυ Έπν ΉΜεΆ░Ε ΊβΦΉηυΈ░εΉΔζΉΩυΈ╢ΑΈξ╝ ΈΓαΊΔΑΈΓ┤ΈΛΦ ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉΔζΉΕ▒ΊΧαΆ│ι, Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΈςρΈΞ╕ΉζΕ ΊΧβΉΛ╡ ΉΜεΊΓρ ΊδΕ ΊβΦΉηυ Έ░εΉΔζΊβΧΈξι ΉαΙΉ╕κ Ά▓░Ά│╝ΉβΑ ΉΜνΉιε ΊβΦΉηυΈ░εΉΔζΉΩυΈ╢ΑΈξ╝ Έ╣ΕΆ╡ΡΊΧαΉΩυ ΈςρΈΞ╕Ήζα ΉΕ▒ΈΛξΉζΕ Ά▓ΑΉοζΊΧαΉαΑΈΜν. ΈαΡΊΧε Έ│╕ ΉΩ░Ά╡υΉζα Ά▓░Ά│╝Έξ╝ ΉΕιΊΨΚΉΩ░Ά╡υΉβΑΉζα ΉιΧΊβΧΈΠΕ Έ╣ΕΆ╡ΡΈξ╝ ΊΗ╡ΊΧ┤ Έ│╕ ΉΩ░Ά╡υΉζα Ήγ░ΉΙαΉΕ▒ΉζΕ ΉηΖΉοζΊΧαΉαΑΈΜν.
2. Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΕ ΊβεΉγσΊΧε ΊβΦΉηυΊβΧΈξι ΉαΙΉ╕κ
Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕε ΉιεΉΧΙΊΧαΈΛΦ ΊβΦΉηυΊβΧΈξι ΉαΙΉ╕κΈςρΈΞ╕ΉζΑ Έπν ΉΜεΆ░Ε Ή╕κΉιΧΈΡαΈΛΦ ΈΓιΉΦρ ΉιΧΈ│┤Έξ╝ Έ░ΦΊΔΧΉε╝Έκε Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΉαΙΉ╕κΈςρΈΞ╕ΉζΕ ΊβεΉγσΊΧαΉΩυ ΊβΦΉηυΈ░εΉΔζ ΊβΧΈξιΉζΕ Ά│ΕΉΓ░ΊΧεΈΜν. Έ│╕ ΉΩ░Ά╡υΈΛΦ ΈΞ░Ήζ┤ΊΕ░ ΉΙαΉπΣ, ΈΞ░Ήζ┤ΊΕ░ ΊΗ╡ΊΧσ, ΉαΙΉ╕κΈςρΈΞ╕ ΉΔζΉΕ▒ Έ░Π ΊβΧΈξιΆ│ΕΉΓ░ ΈΜρΆ│ΕΈκε Ά╡υΉΕ▒ΈΡαΈσ░(Fig. 2) 2008ΈΖΕΈ╢ΑΊΕ░ 2017ΈΖΕΆ╣ΝΉπΑ 10ΈΖΕ Ά░Ε Ή╢ΧΉιΒΈΡε ΊβΦΉηυΈΞ░Ήζ┤ΊΕ░ Έ░Π Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░Ά░Α ΉΓυΉγσΈΡαΉΩΙΈΜν.
ΉΔζΉΕ▒ΈΡε ΉαΙΉ╕κΈςρΈΞ╕ΉζΑ ΉδΦ, Ήζ╝, ΉΜε, ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞ Έ│ΑΉΙαΈξ╝ ΉΓυΉγσΊΧαΈσ░, Έπν ΉΜεΆ░Ε ΊΧ┤ΈΜ╣ ΉπΑΉΩφΉζα ΊβΦΉηυΈ░εΉΔζ ΊβΧΈξι(0%~100%)ΉζΕ ΉΧΝ ΉΙα ΉηΙΉΨ┤ ΉΜνΉΜεΆ░Ε ΊβΦΉηυ ΈΝΑΈ╣ΕΆ░Α Ά░ΑΈΛξΊΧαΈΜν.
2.1 ΈΞ░Ήζ┤ΊΕ░ ΉΙαΉπΣ
ΉαΙΉ╕κΈςρΈΞ╕ ΉΔζΉΕ▒ΉζΕ ΉεΕΊΧ┤ ΉΕεΉγ╕ΉΜε ΊβΦΉηυ ΈΞ░Ήζ┤ΊΕ░ΉβΑ ΉΕεΉγ╕ΉΜε Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░, Ά╖╕ΈουΆ│ι ΉΕεΉγ╕ΉΜεΉζα Ήζ╕Ά╡υ, Έσ┤ΉιΒ, ΊΗιΉπΑΉζ┤Ήγσ ΈΥ▒ΉζΕ ΈΓαΊΔΑΈΓ┤ΈΛΦ ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉΙαΉπΣΊΧαΉαΑΈΜν. ΈΞ░Ήζ┤ΊΕ░ ΉΙαΉπΣΆ╕░Ά░ΕΉζΑ 2008ΈΖΕ 1ΉδΦ 1Ήζ╝Έ╢ΑΊΕ░ 2017ΈΖΕ 12ΉδΦ 31Ήζ╝Ά╣ΝΉπΑ Ή┤ζ 10ΈΖΕΉζ┤Έσ░ ΊβΦΉηυ ΈΞ░Ήζ┤ΊΕ░ΈΛΦ 50,864Ά▒┤, Ά╕░ΉΔΒ ΈΞ░Ήζ┤ΊΕ░ΈΛΦ 87,686Ά▒┤, ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░ΈΛΦ 10Ά▒┤(ΈΖΕ ΈΜρΉεΕ)ΉζΕ ΉΙαΉπΣΊΧαΉαΑΈΜν.
ΊβΦΉηυΈΞ░Ήζ┤ΊΕ░ΈΛΦ Ά╡φΆ░ΑΊβΦΉηυΉιΧΈ│┤ΉΕ╝ΊΕ░(NFDS)Έξ╝ ΊΗ╡ΊΧ┤ ΉΙαΉπΣΊΧαΉαΑΉε╝Έσ░ ΊβΦΉηυΉΓυΆ│ι Έ░εΉΔζΉΜεΆ░Ε(ΈΖΕ, ΉδΦ, Ήζ╝, ΉΜε) Έ░Π ΊβΦΉηυΉειΊαΧ, ΊβΦΉηυΈ░εΉΔζ ΉπΑΉΩφ, Έ░εΊβΦΉγΦΉζ╕, Έ░εΊβΦΉηξΉΗΝ ΈΥ▒Ήζα ΉιΧΈ│┤Έξ╝ ΊΠυΊΧρΊΧαΆ│ι ΉηΙΈΜν. Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░ΈΛΦ Ά╕░ΉΔΒΉ▓φΉζΕ ΊΗ╡ΊΧ┤ ΉΙαΉπΣΊΧαΉαΑΉε╝Έσ░ Έπν ΉΜεΆ░Ε Ή╕κΉιΧΊΧε ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞ, ΊΤΞΊΨξ, Ά░ΧΉγ░ΈθΚ ΈΥ▒Ήζα ΉιΧΈ│┤Έξ╝ ΊΠυΊΧρΊΧαΆ│ι ΉηΙΈΜν. ΈπΙΉπΑΈπΚΉε╝Έκε ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░ΈΛΦ ΉΕεΉγ╕ΉΜεΉζα Ήζ╕Ά╡υ, Έσ┤ΉιΒ, ΊΗιΉπΑ Ήζ┤Ήγσ(ΉηΕΉΧ╝, Ά│╡Ήηξ, ΊΧβΆ╡Ρ, Ήμ╝ΉειΉΗΝ) ΊαΕΊβσΉζΕ ΊΠυΊΧρΊΧαΆ│ι ΉηΙΈΜν.
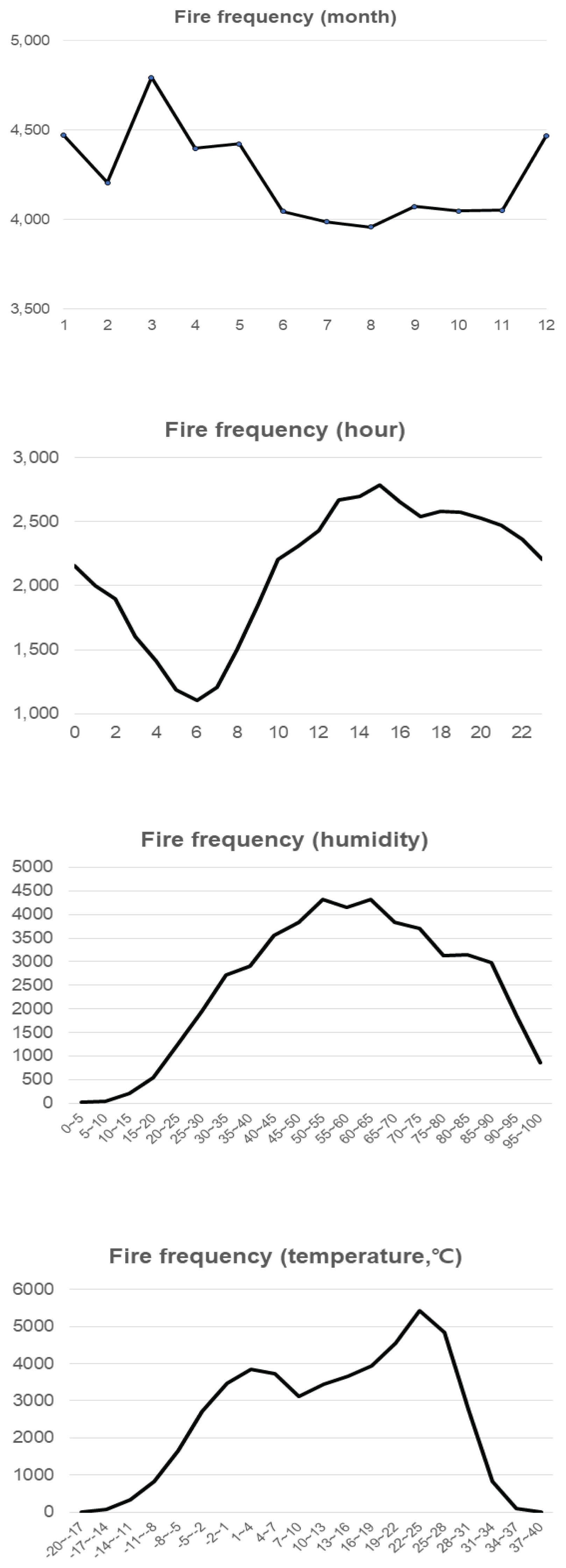
ΉΙαΉπΣΊΧε ΊβΦΉηυ Έ░Π Ά╕░ΉΔΒ ΈΞ░Ήζ┤ΊΕ░Ήζα ΈΜνΉΨΣΊΧε ΉιΧΈ│┤ ΉνΣΉΩΡΉΕε ΉαΙΉ╕κΈςρΈΞ╕ ΉΔζΉΕ▒ΉΩΡ ΉΓυΉγσΊΧι Ήμ╝ΉγΦ Έ│ΑΉΙαΈΥνΉζΕ ΉΕιΉιΧΊΧαΉΩυ ΈΣΡ ΉλΖΈξαΉζα ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΊΗ╡ΊΧσΊΧαΆ╕░ ΉεΕΊΧε ΉιΕΉ▓αΈου ΉηΣΉΩΖΉζΕ ΉπΕΊΨΚΊΧαΉαΑΈΜν. Έ│ΑΉΙαΈΛΦ ΈΞ░Ήζ┤ΊΕ░Έ╢ΕΉΕζΉζΕ Ά╕░Έ░αΉε╝Έκε ΉΕιΉιΧΊΧαΉαΑΉε╝Έσ░ Έ╢ΕΉΕζΆ▓░Ά│╝ΈΛΦ Fig. 3ΉΩΡ ΈΓαΊΔΑΈΓ┤ΉΩΙΈΜν. ΉΜεΆ░ΕΉΩΡ ΈΦ░Έξ╕ Έ╢ΕΉΕζΆ▓░Ά│╝Έξ╝ Έ│┤Έσ┤ ΊβΦΉηυΈΛΦ 1ΉδΦΈ╢ΑΊΕ░ 12ΉδΦ ΉΓυΉζ┤ ΉνΣ 3ΉδΦΉΩΡ Ά░ΑΉηξ ΈπΟΉζ┤ Έ░εΉΔζΊΧαΈσ░ 7~8ΉδΦ ΉΓυΉζ┤ΉΩΡ ΉιΒΆ▓Ν Έ░εΉΔζΊΧεΈΜν. ΈαΡΊΧε 0ΉΜεΈ╢ΑΊΕ░ 23ΉΜε ΉΓυΉζ┤ ΉνΣ ΉιΡΉΜυΉΜεΆ░Ε 13~15ΉΜεΉΩΡ ΈπΟΉζ┤ Έ░εΉΔζΊΧαΉΩυ ΉΔΙΈ▓╜ΉΜεΆ░Ε 5~7ΉΜεΉΩΡ ΉιΒΆ▓Ν Έ░εΉΔζΊΧεΈΜν. ΈΜνΉζΝΉε╝Έκε ΈΓιΉΦρΉΩΡ ΈΦ░Έξ╕ Έ╢ΕΉΕζΆ▓░Ά│╝Έκε ΊβΦΉηυΈΛΦ Ά╕░ΉαρΉζ┤ 19 έΕΔ~28 έΕΔ ΉΓυΉζ┤Ήζ╝ ΈΧΝ ΈπΟΉζ┤ Έ░εΉΔζΊΧαΆ│ι, ΉΛ╡ΈΠΕΆ░Α 50~65Ήζ╝ ΈΧΝ ΈπΟΉζ┤ Έ░εΉΔζΊΧεΈΜν. ΈΦ░Έζ╝ΉΕε ΊβΦΉηυ ΈΞ░Ήζ┤ΊΕ░ΉΩΡΉΕεΈΛΦ ΈΖΕ, ΉδΦ, Ήζ╝, ΉΜεΈξ╝ ΊβΦΉηυ ΉγΦΉζ╕Έ│ΑΉΙαΈκε ΉΕιΉιΧΊΨΙΉε╝Έσ░ Ά╕░ΉΔΒ ΈΞ░Ήζ┤ΊΕ░ΉΩΡΉΕεΈΛΦ ΈΖΕ, ΉδΦ, Ήζ╝, ΉΜε, ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞ ΉιΧΈ│┤Έξ╝ Έ│ΑΉΙαΈκε ΉΕιΉιΧΊΧαΉαΑΈΜν. ΈΣΡ ΉλΖΈξαΉζα ΈΞ░Ήζ┤ΊΕ░ΈΛΦ Tables 1 and 2ΉΩΡ ΈΓαΊΔΑΈΓ┤ΉΩΙΈΜν.
2.2 ΈΞ░Ήζ┤ΊΕ░ ΊΗ╡ΊΧσ
ΉαΙΉ╕κΈςρΈΞ╕ΉζΕ ΉΔζΉΕ▒ΊΧαΆ╕░ ΉεΕΊΧε Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΕ ΊΧβΉΛ╡ΉΜεΊΓνΆ╕░ ΉεΕΊΧ┤ΉΕεΈΛΦ Ήμ╝ΉΨ┤ΉπΕ ΉΔΒΊβσ(ΉδΦ, Ήζ╝, ΉΜε, ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞ)ΉΩΡΉΕε ΊβΦΉηυΈ░εΉΔζ ΉΩυΈ╢ΑΈξ╝ ΉΧΝ ΉΙα ΉηΙΈΛΦ ΈΞ░Ήζ┤ΊΕ░Ά░Α ΊΧΕΉγΦΊΧαΈΜν. ΊβΦΉηυ ΈΞ░Ήζ┤ΊΕ░ΈΛΦ Έ░εΉΔζΊΧε ΊβΦΉηυΉΩΡ ΈΝΑΊΧε ΈΞ░Ήζ┤ΊΕ░ΈπΝ ΊΠυΊΧρΊΧαΆ│ι ΉηΙΉΨ┤ Έ░εΉΔζΊΧαΉπΑ ΉΧΛΉζΑ ΉΔΒΊβσΉΩΡ ΈΝΑΊΧε ΉιΧΈ│┤Έξ╝ ΊΧβΉΛ╡ΊΧι ΉΙα ΉΩΗΈΜν. ΈΦ░Έζ╝ΉΕε ΉΙαΉπΣΈΡε ΈΣΡ ΉλΖΈξαΉζα ΈΞ░Ήζ┤ΊΕ░Έξ╝ Έ░ΦΊΔΧΉε╝Έκε ΉΩ░ΉΗΞΉιΒΉζ╕ ΉΜεΆ░ΕΉ╢ΧΉΩΡΉΕε ΊβΦΉηυ Έ░εΉΔζΉΩυΈ╢ΑΈξ╝ ΈΓαΊΔΑΈΓ┤ΈΛΦ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ ΉΔζΉΕ▒Ήζ┤ ΊΧΕΉγΦΊΧαΈΜν.
ΊβΦΉηυ ΈΞ░Ήζ┤ΊΕ░ΉβΑ Ά╕░ΉΔΒ ΈΞ░Ήζ┤ΊΕ░ΉΩΡΉΕε ΈΠβΉζ╝ΊΧε ΉΜεΆ░ΕΉΩΡ ΉΙαΉπΣΈΡε ΈΞ░Ήζ┤ΊΕ░Έξ╝ Έ│ΣΊΧσΊΧαΉΩυ ΉΩ░ΉΗΞΈΡε ΉΜεΆ░ΕΉ╢ΧΉΩΡΉΕε Έ░εΉΔζΊΧε ΊβΦΉηυΈξ╝ έΑαYesέΑβΈκε ΊΣεΉΜεΊΧε ΊδΕ, ΊβΦΉηυΆ░Α Έ░εΉΔζΊΧαΉπΑ ΉΧΛΉζΑ ΈΓαΈρ╕ΉπΑ ΉΜεΆ░ΕΈΝΑΉΩΡ έΑαNoέΑβΈξ╝ ΊΣεΉΜεΊΧεΈΜν. ΊβΦΉηυ Έ░εΉΔζΉΜεΆ░ΕΆ│╝ Ά╕░ΉΔΒ ΈΞ░Ήζ┤ΊΕ░ Ή╕κΉιΧΉΜεΆ░ΕΉζ┤ ΈΠβΉζ╝ΊΧε ΈΞ░Ήζ┤ΊΕ░ΈΛΦ Tables 2 and 3ΉΩΡ ΉζΝΉαΒΉε╝Έκε ΈΓαΊΔΑΈΓ┤ΉΩΙΈΜν. ΈαΡΊΧε, Ά░βΉζΑ ΉΜεΆ░ΕΈΝΑΉΩΡ Έ░εΉΔζΊΧε 2ΊγΝ Ήζ┤ΉΔΒΉζα ΊβΦΉηυΆ▒┤ΉΙα(ex. 2008ΈΖΕ 1ΉδΦ 1Ήζ╝ 0ΉΜε, 2017ΈΖΕ 12ΉδΦ 31Ήζ╝ 17ΉΜε)ΉΩΡ ΈΝΑΊΧαΉΩυ Έ░εΉΔζΊΧε ΊβΦΉηυ ΊγθΉΙαΈπΝΊΒ╝ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ΉΩΡ Έ░αΉαΒΊΧαΉαΑΈΜν. ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ΈΛΦ Ή┤ζ 100,943Ά▒┤Ήζα ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΊΠυΊΧρΊΧαΈσ░ Έ░εΉΔζΊβΦΉηυ 50,875Ά▒┤Ά│╝ Έψ╕Έ░εΉΔζΊβΦΉηυ 50,068Ά▒┤Ήε╝Έκε Ά╡υΉΕ▒ΈΡεΈΜν. Έ░εΉΔζΆ│╝ Έψ╕Έ░εΉΔζΉΓυΉζ┤Ήζα Έ╣ΕΉερΉζ┤ 50:50ΉζΕ Ήζ┤ΈμρΆ│ι ΉηΙΉε╝ΈψΑΈκε Ά╖ιΊαΧ ΉηΙΈΛΦ ΈΞ░Ήζ┤ΊΕ░Ά╡υΉΕ▒Ήζ┤ΈΜν.
2.3 ΉΕιΊαΧΊγΝΆ╖Α ΈςρΈΞ╕ ΉΔζΉΕ▒
2008ΈΖΕΈ╢ΑΊΕ░ 2017ΈΖΕΆ╣ΝΉπΑ ΉΙαΉπΣΊΧε ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░(Table 4)ΈΛΦ 1ΈΖΕ ΈΠβΉΧΙ ΉΕεΉγ╕ΉΜεΉΩΡ Έ░εΉΔζΊΧε ΊβΦΉηυΈ╣ΙΈΠΕΉβΑ ΉΕεΉγ╕ΉΜε ΊΗ╡Ά│ΕΉζα Ά┤ΑΆ│ΕΈ╢ΕΉΕζΉζΕ ΉεΕΊΧ┤ ΉΓυΉγσΈΡαΉΩΙΈΜν. ΉΕεΉγ╕ΉΜεΉζα ΊΗ╡Ά│Ε Ά░ΤΆ│╝ ΊβΦΉηυΈ╣ΙΈΠΕΉΓυΉζ┤Ήζα Ά┤ΑΆ│ΕΈΛΦ ΈΜνΉνΣΉΕιΊαΧΊγΝΆ╖Α(Multivariate Linear Regression) ΈςρΈΞ╕ΈπΒΉζΕ ΊΗ╡ΊΧ┤ ΈΓαΊΔΑΈΓ┤ΉΩΙΉε╝Έσ░ ΉΜζΉζΑ Eq. (1)Ά│╝ Ά░βΉζ┤ ΈΓαΊΔΑΈΓυΈΜν.
(1)
ΉΕιΊαΧΊγΝΆ╖ΑΈςρΈΞ╕Ήζα ΊΠΚΆ╖ιΉιΙΈΝΑΉανΉ░ρΈΛΦ 37.85Ήζ┤Έσ░ Ήζ┤ ΈςρΈΞ╕ΉζΕ 2015~2017ΈΖΕΈΠΕΉζα ΉΩ░Ά░Ε ΊβΦΉηυΈ╣ΙΈΠΕΈξ╝ ΉαΙΉ╕κΊΧαΈΛΦ ΈΞ░ ΊβεΉγσΊΧαΉαΑΈΜν. ΉαΙΉ╕κΈΡε ΉΩ░Ά░Ε ΊβΦΉηυΈ╣ΙΈΠΕΈΛΦ 1ΈΖΕ, 8760ΉΜεΆ░ΕΉε╝Έκε ΈΓαΈΙΕΉΨ┤ ΉΜεΆ░ΕΈΜ╣ ΊΠΚΆ╖ι ΊβΦΉηυΈ░εΉΔζ ΊβΧΈξιΈκεΉΞρ Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζα Ή╢εΈιξΉ╕╡ ΊΟ╕ΊΨξΆ░ΤΉε╝Έκε ΉΓυΉγσΈΡαΉΩΙΈΜν.
2.4 Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΈςρΈΞ╕ ΉΔζΉΕ▒
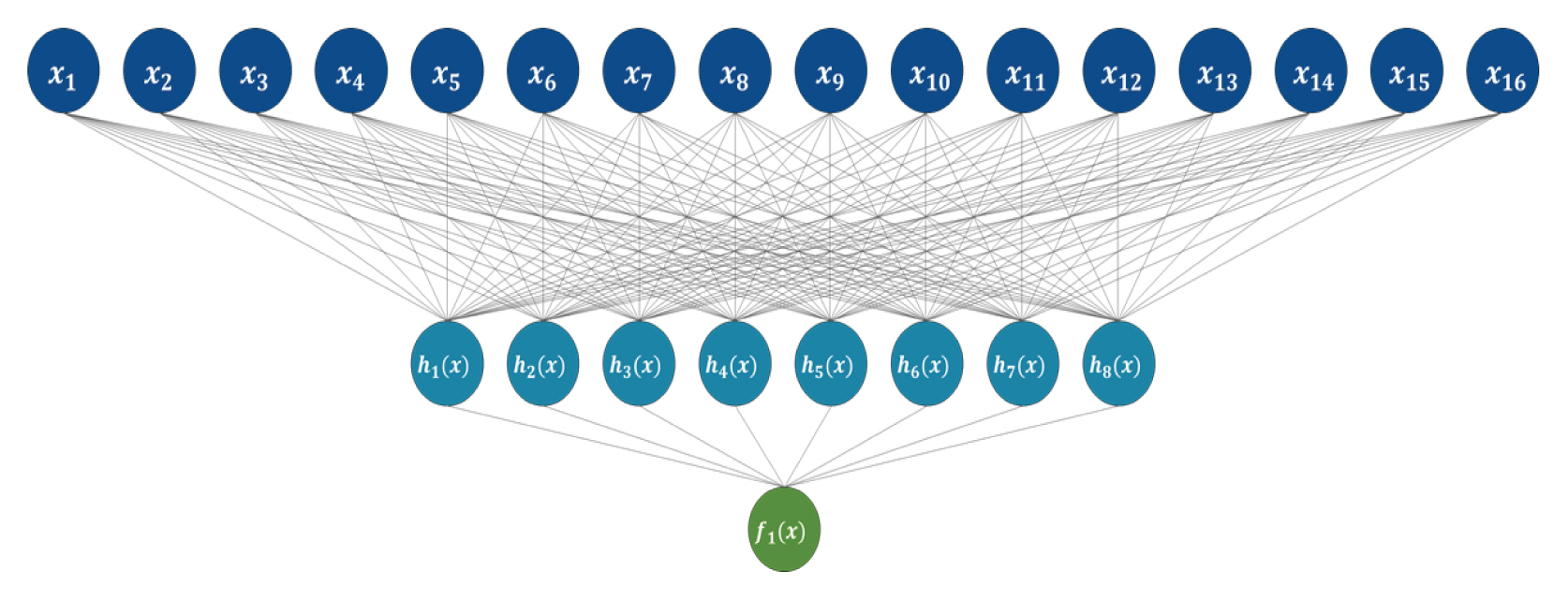
ΉΧηΉΩΡΉΕε Ά╡υΉ╢ΧΈΡε ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ΈΛΦ Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΈςρΈΞ╕ΉζΕ ΊΧβΉΛ╡ΊΧαΈΛΦ ΈΞ░ ΉΓυΉγσΈΡεΈΜν. Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΑ Ά╕░Ά│ΕΊΧβΉΛ╡Ήζα ΊΗ╡Ά│ΕΊΧβΉιΒ ΊΧβΉΛ╡ΉΧΝΆ│ιΈουΉοα ΉνΣΉζα ΊΧαΈΓαΈκε ΉΩυΈθυ Ή╕╡Ήζα ΈΚ┤Έθ░Ήζ┤ ΉΩ░Ά▓░ΈΡαΉΨ┤ ΉηΙΈΛΦ Ά╡υΉκ░Έξ╝ ΈΓαΊΔΑΈΓ┤Έσ░ ΉΩ░Ά▓░ Ά░ΕΉζα Ά░ΑΉνΣΉ╣αΈξ╝ Ά░▒ΉΜιΊΧαΈσ░ ΊΧβΉΛ╡Ήζ┤ Ήζ┤ΈμρΉΨ┤ΉπΑΈΛΦ ΊΛ╣ΉπΧΉζ┤ ΉηΙΈΜν(Neal, 1996). ΉΜιΆ▓╜ΈπζΉζΑ ΊΒυΆ▓Ν ΉηΖΈιξΉ╕╡(Input Layer), ΉζΑΈΜΚΉ╕╡(Hidden Layer), Ή╢εΈιξΉ╕╡(Output Layer)Ήε╝Έκε Ά╡υΉΕ▒ΈΡαΈσ░ Fig. 4ΈΛΦ Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ Ά╡υΉκ░Ήζα Ά░ΕΈΜρΊΧε ΉαΙΈξ╝ ΈΓαΊΔΑΈΓ╕ΈΜν. 16Ά░εΉζα Έ│ΑΉΙαΈξ╝ ΉηΖΈιξΉ╕╡ΉΩΡΉΕε ΉηΖΈιξΈ░δΆ│ι 8Ά░εΉζα ΈΖ╕ΈΥεΈκε Ήζ┤ΈμρΉΨ┤ΉπΕ ΉζΑΈΜΚΉ╕╡ ΉΧΙΉζα ΊβεΉΕ▒ΊΧρΉΙα hk(╧Θ)Έξ╝ Ά▒░Ή╣ε ΊδΕ Ή╢εΈιξΉ╕╡Ήζα Ή╢εΈιξ Ά░ΤΉζ┤ Ή╡εΉλΖ ΊβΧΈξι Ά░ΤΉε╝Έκε Ά│ΕΉΓ░ΈΡαΈΛΦ ΊαΧΊΔεΉζ┤ΈΜν. Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΕ 35Ά░εΉζα ΉηΖΈιξΈΖ╕ΈΥεΉβΑ 3Ά░εΉζα ΉζΑΈΜΚΉ╕╡ Ά╖╕ΈουΆ│ι ΊβΧΈξιΆ│ΕΉΓ░ΉζΕ ΉεΕΊΧε 1Ά░εΉζα Ή╢εΈιξΈΖ╕ΈΥεΈκε Ά╡υΉΕ▒ΊΧαΉαΑΈΜν. ΉζΑΈΜΚΉ╕╡ΉζΑ Ά▓╜ΊΩαΉΩΡ ΉζαΊΧε Ή╡εΉιΒΊβΦΈξ╝ ΊΗ╡ΊΧ┤ 3Ά░εΉζα Ή╕╡ΉζΕ ΉΓυΉγσΊΧαΉαΑΉε╝Έσ░ Ά░Β Ή╕╡ΉζΑ 64, 32, 16Ά░εΉζα ΈΖ╕ΈΥεΈκε Ά╡υΉΕ▒ΊΧαΉαΑΈΜν. ΉζΑΈΜΚΉ╕╡Ήζα ΊβεΉΕ▒ΊΧρΉΙα(Activation function)ΈΛΦ ReLU ΊΧρΉΙαΈξ╝ ΉΓυΉγσΊΧαΉαΑΆ│ι, ΊβΧΈξιΆ│ΕΉΓ░ΉζΕ ΉεΕΊΧε Ή╢εΈιξΉ╕╡Ήζα ΊΧρΉΙαΈΛΦ Sigmoid ΊΧρΉΙαΈξ╝ ΉΓυΉγσΊΧαΉαΑΈΜν.
Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΑ ΉανΉ░ρΉΩφΉιΕΊΝΝ(Back-propagation) ΉΧΝΆ│ιΈουΉοαΉΩΡ ΉζαΊΧ┤ ΊΧβΉΛ╡ΈΡαΈσ░(Hagan and Menhaj, 1994) Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζα ΊγρΉερΉιΒΉζ╕ ΊΧβΉΛ╡ΉζΕ ΉεΕΊΧ┤ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░Ήζα Έ│ΑΉΙαΈΥνΉζΕ Table 5ΉΩΡ ΈΦ░Έζ╝ Έ▓ΦΉμ╝ΊβΦ(Categorization)ΊΧαΉΩυ Έ▓ΦΉμ╝ΊαΧ Έ│ΑΉΙα(Categorical variable)Έκε ΊΧβΉΛ╡ΉζΕ ΉπΕΊΨΚΊΧαΉαΑΈΜν. έΑαΉδΦέΑβ Έ│ΑΉΙαΈΛΦ Ά│ΕΉιΙΉιΒ ΊΛ╣ΉΕ▒ΉζΕ Έ░αΉαΒΊΧαΉΩυ Έ┤Ε, ΉΩυΈοΕ, Ά░ΑΉζΕ, Ά▓ρΉγ╕ 4Ά░ΑΉπΑ Έ▓ΦΉμ╝Έκε ΈΓαΈΙΕΉΩΙΆ│ι, έΑαΉζ╝έΑβ Έ│ΑΉΙαΈΛΦ 4Ήζ╝ΈπΙΈΜν ΊΧαΈΓαΈκε Έυ╢Ά│ι έΑαΉΜεέΑβ Έ│ΑΉΙαΈΛΦ 3ΉΜεΆ░ΕΈπΙΈΜν ΊΧαΈΓαΈκε Έυ╢ΉΨ┤ Ά░ΒΆ░Β 8Ά░ΑΉπΑ Έ▓ΦΉμ╝Έκε ΈΓαΈΙΕΉΩΙΈΜν. έΑαΉαρΈΠΕέΑβ, έΑαΉΛ╡ΈΠΕέΑβ, έΑαΊΤΞΉΗΞέΑβ Έ│ΑΉΙαΈΛΦ ΈΞ░Ήζ┤ΊΕ░ Έ╢ΕΊΠυΈΠΕΉΩΡ ΈΦ░Έζ╝ ΈπνΉγ░ ΈΓχΉζΝ, ΈΓχΉζΝ, Έ│┤ΊΗ╡, ΈΗΤΉζΝ, ΈπνΉγ░ ΈΗΤΉζΝ 5Ά░ΑΉπΑ Έ▓ΦΉμ╝Έκε ΈΓαΈΙΕΉΩΙΈΜν. Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ 2008ΈΖΕΈ╢ΑΊΕ░ 2014ΈΖΕΆ╣ΝΉπΑ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ 70,484Ά▒┤ΉζΕ ΊΧβΉΛ╡ΈΞ░Ήζ┤ΊΕ░Έκε, 2015ΈΖΕΈ╢ΑΊΕ░ 2017ΈΖΕΆ╣ΝΉπΑ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░ 30,459Ά▒┤ΉζΕ ΊΠΚΆ░ΑΈΞ░Ήζ┤ΊΕ░Έκε ΉΓυΉγσΊΧαΉαΑΈΜν.
ΊΧβΉΛ╡Ήζ┤ ΉβΕΈμΝΈΡε ΉΜιΆ▓╜ΈπζΈςρΈΞ╕ΉζΑ ΉδΦ, Ήζ╝, ΉΜε, ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞ ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉηΖΈιξΈ░δΉΧΕ ΉΕεΉγ╕ΉΜεΉζα ΊβΦΉηυΈ░εΉΔζΊβΧΈξιΉζΕ 0~100% Ά░ΤΉε╝Έκε ΈΓαΊΔΑΈΓ╕ΈΜν. ΉαΙΉ╕κΈΡε ΊβΧΈξιΉζΕ ΉΜνΉιε ΊβΦΉηυΈ░εΉΔζ ΉΩυΈ╢ΑΉβΑ Έ╣ΕΆ╡ΡΈξ╝ ΊΗ╡ΊΧ┤ ΈςρΈΞ╕Ήζα ΉιΧΊβΧΉΕ▒ΉζΕ ΊΠΚΆ░ΑΊΧεΈΜν.
3. Ά▓░ Ά│╝
Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ ΉΧηΉΕε ΉΕιΊΨΚΈΡε ΉζαΉΓυΆ▓░ΉιΧΊΛ╕Έου ΈςρΈΞ╕Ά│╝Ήζα Ά▓░Ά│╝ Έ╣ΕΆ╡ΡΈξ╝ ΉεΕΊΧ┤ ΉΔΒΈΝΑ ΉιΙΈΝΑ ΉανΉ░ρ(RAE)Έξ╝ ΈςρΈΞ╕Ήζα ΉΕ▒ΈΛξ Ά▓ΑΉοζ ΉπΑΊΣεΈκε ΉΕιΉιΧΊΧαΉαΑΈΜν. RAEΈΛΦ ΉαΙΉ╕κΈςρΈΞ╕Ήζα ΉΕ▒ΈΛξΉζΕ Ά▓ΑΉοζΊΧι ΈΧΝ ΈπΟΉζ┤ ΉΥ░Ήζ┤ΈΛΦ ΉπΑΊΣεΉζ┤Έσ░ ΈςρΈΞ╕Ήζα ΉζαΉκ┤ΉΕ▒, ΉηΣΉζΑ Έ│ΑΊβΦΉΩΡ ΈΝΑΊΧε Έψ╝Ά░ΡΈΠΕ ΈΥ▒Ήζα Ή╕κΈσ┤ΉΩΡ ΉηΙΉΨ┤ΉΕε Ήγ░ΉΙαΊΧε ΊΠΚΆ░ΑΉπΑΊΣεΈκεΉΞρ ΉΓυΉγσΈΡεΈΜν(Armstrong and Collopy, 1992).
ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρΈΛΦ Eq. (2)Ά│╝ Ά░βΈΜν.
nΉζΑ ΊΠΚΆ░ΑΈΞ░Ήζ┤ΊΕ░Ήζα Ά░εΉΙα, piΈΛΦ ΉαΙΉ╕κΈςρΈΞ╕ΉΩΡΉΕε Ά│ΕΉΓ░ΈΡε ΊβΦΉηυ Έ░εΉΔζ ΊβΧΈξιΆ░Τ, aiΈΛΦ ΉΜνΉιε ΊβΦΉηυΈ░εΉΔζ ΉΩυΈ╢Α(Έ░εΉΔζ:1, Έψ╕Έ░εΉΔζ:0), a ┬ψ i
Table 6ΉΩΡΉΕεΈΛΦ Ryu et al. (2014) ΉΩ░Ά╡υΉζα ΉζαΉΓυΆ▓░ΉιΧΊΛ╕ΈουΈςρΈΞ╕Ά│╝Ήζα ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρΈξ╝ Έ╣ΕΆ╡ΡΊΧε Ά▓░Ά│╝Έξ╝ Έ│┤ΉΩυΉνΑΈΜν. ΉζαΉΓυΆ▓░ΉιΧΊΛ╕Έου ΈςρΈΞ╕Ήζα ΉΕεΉγ╕ΉΜε ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρΈΛΦ 0.9594Έξ╝ ΈΓαΊΔΑΈΓ┤Έσ░, Έ│╕ ΉΩ░Ά╡υΉζα ΉαΙΉ╕κΈςρΈΞ╕ ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρΈΛΦ ΉλΑ ΈΞΦ Ήγ░ΉΙαΊΧε ΉιΧΊβΧΈΠΕΈξ╝ Έ│┤ΉΩυΉμ╝ΉΩΙΈΜν. ΉΕεΉγ╕ΉΜε ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░(Ήζ╕Ά╡υ, Έσ┤ΉιΒ, ΊΗιΉπΑΉζ┤Ήγσ)Έξ╝ ΉΓυΉγσΊΧαΉπΑ ΉΧΛΆ│ι ΉδΦ, Ήζ╝, ΉΜε, ΉαρΈΠΕ, ΉΛ╡ΈΠΕ, ΊΤΞΉΗΞΉε╝ΈκεΈπΝ ΉαΙΉ╕κΉζΕ ΉπΕΊΨΚΊΧε Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΈςρΈΞ╕ΉζΑ ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρ Ά░ΤΉε╝Έκε 0.9492 Ά░ΤΉζΕ ΈΓαΊΔΑΈΓ┤ΉΩΙΉε╝Έσ░, ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉΓυΉγσΊΧαΉαΑΉζΕ ΉΜε Έ│┤ΈΜν Ά░εΉΕιΈΡε 0.9488 Ά░ΤΉζΕ ΈΓαΊΔΑΈΓ┤ΉΩΙΈΜν.
4. Ά▓░ Έκι
Έ│╕ ΈΖ╝Έυ╕ΉΩΡΉΕεΈΛΦ ΉΕεΉγ╕ΉΜε Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░ΉβΑ ΊβΦΉηυΈΞ░Ήζ┤ΊΕ░Έξ╝ Ά▓░ΊΧσΊΧε ΊβΦΉηυΈ░εΉΔζ ΊΗ╡ΊΧσΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉΔζΉΕ▒ΊΧαΉαΑΉε╝Έσ░, 7ΈΖΕ ΈΞ░Ήζ┤ΊΕ░Έξ╝ ΉΓυΉγσΊΧ┤ Ήζ╕Ά│╡ΉΜιΆ▓╜ΈπζΉζΕ ΊΧβΉΛ╡ΉΜεΊΓρ ΊδΕ 3ΈΖΕ ΈΞ░Ήζ┤ΊΕ░Έκε ΉΕ▒ΈΛξΊΠΚΆ░ΑΈξ╝ ΉπΕΊΨΚΊΧαΉαΑΈΜν. ΊβΦΉηυΈΛΦ ΉΩυΈθυ Ά░ΑΉπΑ ΈΜνΉΨΣΊΧε Έ│ΑΉζ╕ΈΥνΉζα ΉΔΒΊα╕ΉηΣΉγσΉζΕ ΊΗ╡ΊΧ┤ Έ░εΉΔζΊΧαΈΛΦ ΉΓυΆ│ιΉζ┤ΈψΑΈκε ΈΜρΉΙεΊΧαΆ▓Ν ΈΓιΉπεΉβΑ Ά╕░ΉΔΒΈΞ░Ήζ┤ΊΕ░ΈπΝΉε╝Έκε ΉαΙΉ╕κΊΧαΆ╕░ΉΩΡΈΛΦ ΊΧεΆ│ΕΆ░Α Ήκ┤ΉηυΊΧεΈΜν. ΈΦ░Έζ╝ΉΕε Έ│╕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ ΉπΑΉΩφΈ│Ε ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░(Ήζ╕Ά╡υ, Έσ┤ΉιΒ, ΊΗιΉπΑΉζ┤Ήγσ)Έξ╝ Ά│ιΈινΊΧαΉΩυ ΉιΧΊβΧΈΠΕΈξ╝ ΈΗΤΉζ╕ ΉιΧΆ╡ΡΊΧε ΉαΙΉ╕κΈςρΈΞ╕ΉζΕ Ά░εΈ░εΊΧαΉαΑΈΜν. ΉΕεΉγ╕ΉΜε ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░Έξ╝ ΊβεΉγσΊΧαΉΩυ ΉΕιΊαΧΊγΝΆ╖ΑΈςρΈΞ╕ΉζΕ Ά░εΈ░εΊΧαΉαΑΉε╝Έσ░, ΈςρΈΞ╕Ήζα Ά▓░Ά│╝Έξ╝ Ήζ╕Ά│╡ΉΜιΆ▓╜Έπζ ΊΧβΉΛ╡ΉΩΡ ΉΓυΉγσΊΧαΉαΑΈΜν. ΉδΦ, ΉΜεΈξ╝ ΉαΙΉ╕κΈ│ΑΉΙαΈκε ΉΓυΉγσΊΧαΈΛΦ Ά╕░Ήκ┤Ήζα ΉζαΉΓυΆ▓░ΉιΧΊΛ╕ΈουΉβΑ ΈΜυΈου ΉδΦ, Ήζ╝, ΉΜε, ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░Έξ╝ ΈςρΈΣΡ ΉαΙΉ╕κ Έ│ΑΉΙαΉΩΡ Έ░αΉαΒΊΧι ΉΙα ΉηΙΈΛΦ ΉηξΉιΡΉζΕ Ά░ΑΉπΑΆ│ι ΉηΙΉΨ┤ Έ│┤ΈΜν ΉιΧΊβΧΈΠΕ ΈΗΤΉζΑ ΉαΙΉ╕κΉζΕ ΊΧι ΉΙα ΉηΙΈΜν. Ά╖╕ Ά▓░Ά│╝, ΉΕεΉγ╕ΉΜε ΊβΦΉηυΈ░εΉΔζ ΊβΧΈξι ΉαΙΉ╕κ ΉΔΒΈΝΑΉιΙΈΝΑΉανΉ░ρΆ░Α 0.9594ΉΩΡΉΕε 0.9488Έκε Ά░εΉΕιΈΡε ΉιΧΊβΧΈΠΕΈξ╝ Έ│┤ΉΩυΉμ╝Έσ░ ΈΞΦΉγ▒ Ήγ░ΉΙαΊΧε ΈςρΈΞ╕ΉηΕΉζΕ ΉοζΈςΖΊΧαΉαΑΈΜν.
ΊΧαΉπΑΈπΝ ΊΗ╡Ά│ΕΈΞ░Ήζ┤ΊΕ░Ήζα ΈΜρΉεΕΆ░Α ΉΩ░ ΈΜρΉεΕΉζ╕ ΉιΡΉζΕ Ά│ιΈινΊΧαΈσ┤ ΉΜε ΈΜρΉεΕ ΉαΙΉ╕κ ΈςρΈΞ╕ΉΩΡ ΉιΧΈ░ΑΊΧαΆ▓Ν ΉιΒΉγσΈΡι ΉΙα ΉΩΗΈΛΦ ΊΧεΆ│ΕΆ░Α ΉηΙΈΜν. ΈΦ░Έζ╝ΉΕε Ήζ┤ΊδΕ ΉΩ░Ά╡υΉΩΡΉΕεΈΛΦ Έ│┤ΈΜν ΉιΧΊβΧΊΧε ΉαΙΉ╕κΈςρΈΞ╕ Ά░εΈ░εΉζΕ ΉεΕΊΧ┤ΉΕε, ΉΜε ΈΜρΉεΕΈκε ΉΙαΉπΣΊΧι ΉΙα ΉηΙΈΛΦ ΊΗ╡Ά│Ε Έ░Π ΈΜνΉΨΣΊΧε ΊβΦΉηυΉγΦΉζ╕ΈΥνΉζΕ Ή╢ΦΆ░ΑΉιΒΉε╝Έκε Έ░αΉαΒΊΧαΉΩυ ΉιΧΊβΧΈΠΕ ΊΨξΉΔΒΉζΕ ΉεΕΊΧε ΉΩ░Ά╡υΈξ╝ ΉπΕΊΨΚ ΊΧι Ά│ΕΊγΞΉζ┤ΈΜν.