Spatio-temporal Analysis of Crime Occurrence: the Case Study of Alice, Texas, USA
Article information
Abstract
Various geostatistical models, including cluster and hot spot analyses, are employed to identify spatio-temporal characteristics of four types of crimes in Alica, Texas; property crime, violent crime, drug crime, and traffic events. The analytical findings show that 1) commercial areas and low income Hispanic residential areas are considered to be hot spots of property crimes, 2) the frequency of violent crimes does not show much variation with time periods as commercial and dilapidated residential areas proved to be hot spots, and 3) drug crimes mainly occur in low income residential areas during night time. These findings would provide evidence for any unequal exposure to urban crime of the socioeconomically disadvantaged, and the methodological approach of this study, including both physical and socio-economic properties of urban neighborhoods, would guide a future urban crime “hot spot” research in Korea.
Trans Abstract
본 연구는 범죄에 취약한 미국 텍사스주 알리스시를 대상으로 범죄 유형별 발생장소의 특성을 시공간적으로 분석함으로써 도시 범죄 장소와 관련된 시사점을 도출하고자 하였다. ‘핫스팟’ 분석 등 지리통계적 분석방법을 활용한 연구결과에 따르면 첫째, 사유지 침입과 관련된 범죄는 아침부터 자정시간대까지는 상업지역에서 집중적으로 발생하며 새벽에는 저소득층 히스패닉 주민이 밀집한 주거지역에서 빈발하였다. 둘째, 폭력범죄 발생은 다른 유형과 달리 전체 시간대에 걸쳐 고루 발생했으며 침입 범죄와 유사하게 아침부터 자정까지는 주로 상업지역에서, 새벽시간에는 취약계층이 밀집한 주거지역에서 빈발하였다. 마약과 관련된 범죄의 경우, 저녁과 새벽에 주로 발생했으며 주간에는 상업지역에서 야간에는 주거환경이 취약한 지역에서 주로 발생하는 것으로 나타났다. 이와 같은 연구결과는 저소득층과 취약계층이 각종 유형의 범죄에 불평등하게 노출되어 있음을 나타내는 객관적 자료로 활용될 수 있을 것으로 판단되며, 본 연구는 향후 토지이용 등 물리적 특성은 물론 지역 구성원의 사회경제적 특징을 고려한 국내 도시 범죄 ‘핫스팟’ 분석 연구를 위한 방법론에 응용될 수 있을 것으로 판단된다.
1. Introduction
Public safety is a critical factor to provide a better living environment for the community. Crime is a major cause of a significant degradation to the quality of life. Unfortunately, South Texas is known as having some of the least safe cities among the cities in the State of Texas. Based on the FBI’s uniform crime report in 1999 (FBIUCR, 1999), most of the cities in South Texas are ranked as higher crime rate cities, with ranges from 8th to 78th among 180 Texas cities and towns with populations of 10,000 or more in 1999. The crime rate for the city of Alice in 2005 is 9,779 which could be ranked as high as 3rd highest among the 180 cities. Geographic Information System (GIS) is a digital mapping and database system which is well-known for its powerful functionalities in spatial analysis, sophisticated mapping and visualization. It provides the science of crime mapping to police officers, crime analysts, and other people in visualizing crime data through the medium of maps. The robust capabilities of crime mapping and analysis have been proven by many studies (Boba, 2005; Chainey & Ratcliffe, 2005; Eck & Weisburd, 1995; Goldsmith, McGuire, Mollenknpf, & Ross, 2000; Paynich & Hill, 2010).
In Korea, the spatial and temporal patterns of crime locations has also been analyzed since the mid 2000s through the lens of GIS and spatial statistic models. Kim, Young Hwan et al. (2007) categorized and plotted urban crimes by crime type, crime location, intruder type, and intrusion type. They laid a foundation of urban crime hot spot research in Korea. Neighborhood characteristics such as land or building use, house price, population density, and old age population ratio proved to be related to some of five major crimes including robbery and assault crime (Jeong et al., 2009). Dong-Kun Kim et al. (2007) also investigated urban crime hot spots in Seoul in consideration of land use patterns and Floor Area Ratio (FAR). Spatio-temporal approach (Jeong et at., 2009; Jeong et al., 2010) was made but without statistical explanation about neighborhood characteristics. This study uniquely attempts to locate spatio-temporal urban crime hot spots in Alice, Texas and to identify statistically significant neighborhood characteristics including socio-economic conditions. Given that, this study would be unique in American and also Korean fields of urban crime study. The following shows briefly urban crime issue in Alice, Texas.
Due to the lack of advanced computational technology, the city of Alice has no information on spatial and temporal characteristics of crime occurrence. Moreover, the cities in South Texas including Alice have unique demographic distributions showing higher Hispanic populations compared to other cities in Texas. Due to the geographic characteristics of South Texas sharing the border with Mexico, a significant number of crime is related to illegal immigrants. Therefore, spatio-temporal crime patterns and types of crimes are critical issues to be analyzed to reduce the crime occurrence and effective dispatch of emergency vehicles to the crime sites. In a GIS environment, this study maps the crimes that occurred in city of Alice, TX during 2007, identifies crime hot spots, and analyzes their spatial distribution over time by specific types of crimes regarding to socio-economic and land use land cover information.
The city of Alice is located in the center of South Texas, 86 miles northeast from the closest Mexican border and 120 miles south of San Antonio with an area of 40.0 km2 (Fig. 1). 34 % of the city is occupied by residential area, and commercial/industrial area accounts for 26 % of the total area. Alice plays as a commercial center for the petroleum industry with more than 100 different oil field companies located around the area, and is also known as the “Hub City” due to its geographic location between nearest big cities. Alice’s location between the big cities makes it an ideal center for distribution and immigration from Mexico.
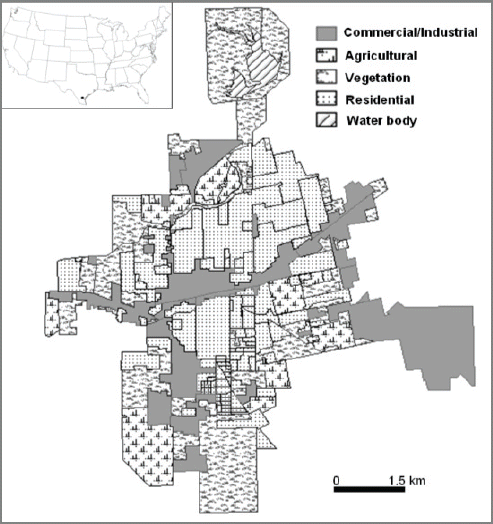
Maps of Land Use Land Cover of Alice, TX.
Based on 2000 Census (USCB, 2000), the population of the city is 19,010 with a median age of 32.9. This city shows a characteristic demographic distribution having a 78% Hispanic population. Moreover, this city is considered one of the poor cities in Texas indicated by median household income $30,365, families below poverty level of 17.9%, and median house values of $44,500 compared to the national averages of $41,994, 9.2%, and $119,600 respectively.
2. Data
The police department of Alice, TX provided one year of crime data from December, 2006 to November, 2007. The police reports contain the crime information including address, date, time, ID, and nature of call. This study constructed the crime data base based on 9,337 records. Depending on the nature of crime, we classified the crime into five different categories; property crime, drug crime, violent crime, traffic accidents, and miscellaneous. Among the 9,337 records, 2,733 crimes are classified as property crimes. The property crimes include theft, burglary, and mischief. PI, PIOU, narcotics, overdose and DWI are grouped as drug crimes with 362 crime records. Violent crimes are recorded 989 times and assault, sexual assault, robbery, criminal trespassing, and indecency are considered as violent crimes. 1,209 traffic records include accident, hit and run, DWLS, reckless driving, UUMV and DWI. About half of total records are categorized as miscellaneous, and they are civil matter, request officer, disturbance, warrants, lost/found property, dog related accidents, and harassment. This study disregards miscellaneous records from spatial and temporal crime analysis due to unclear representation of specific crimes.
Land use and land cover information provides critical value in crime analysis since it provides the characteristics of the physical environment which the census data can not provide. This study utilized four NAIP (National Agricultural Imagery Program) digital ortho photo images which were taken June, 2004 and downloaded from Texas Natural Resources Information System to classify land use and land cover. The digital ortho quarter quads (DOQQS) shows 1 meter spatial resolution rectified to a horizontal accuracy of ±5 meters. The NAIP quarter quads are rectified to the UTM coordinate system NAD83. Five different classes, commercial/industrial, residential, agricultural, vegetation, and water, were manually delineated for accurate crime analysis (Fig. 1). Census data plays an important role in crime analysis since it provides detailed demographic, social and economic information. This study mainly focuses on population, demographic distribution, house income and poverty level for spatio-temporal analysis of crime occurrence. The census data can be combined with spatial data in the GIS environment, and both the table and GIS layer are provided by US census bureau. The census data supports three different spatial levels; census tract, census block group, and census block.
This study employs census block as a base layer to analyze the crime occurrence in the best spatial resolution. However, economic information for Alice, TX is only available at the census block level. To resolve this issue, this study only uses median house income and percent poverty population as economic factors. This study pays attention to population density and the percent Hispanic for social parameters in crime analysis. The population density map, percent Hispanic population map, and median house income map at census block level are shown in Figs. 2, 3, and 4, respectively. In addition to census data, the US census bureau provides topologically integrated geographic encoding and referencing (TIGER) data. TIGER files contain address range. This study uses the TIGER file for Jim Wells County provided by US Census Bureau as a reference layer of geocoding process.
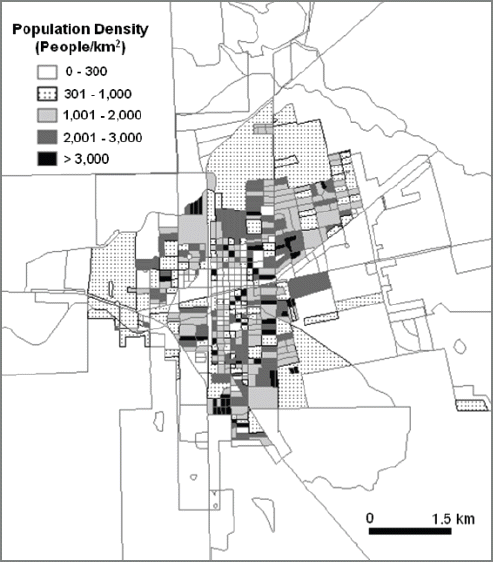
Maps of Population Density
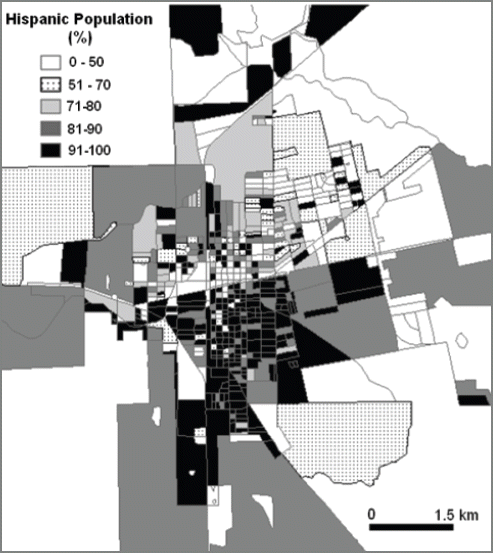
Maps of % Hispanic Population
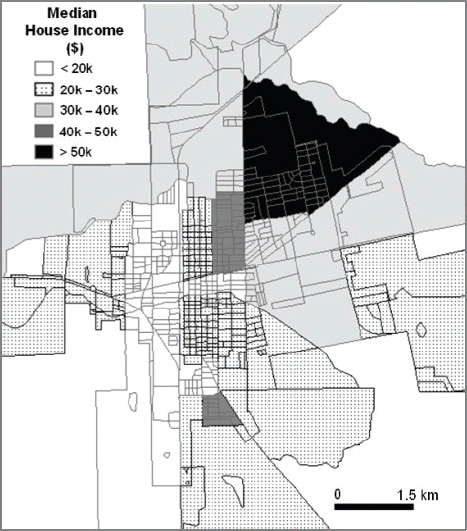
Maps of Median House Income
3. Methods
3.1 Crime hot spot mapping
Much of crime mapping is applied to detecting high-crime density areas known as hot spots. A hot spot is a condition indicating some form of clustering in a spatial distribution (Harris, 1999; Paynich & Hill, 2010). Hot spot analysis aids police in identifying high-crime areas, types of crime being committed, and the best response. There are a few major approaches for identifying hot spots. However, first of all, any crime location must be mapped before hot spot identification. Geocoding is the most commonly used method to get crime data into a GIS (Harris, 1999). Since the crime records almost always have street addresses or other locational attributes, this information enables the link between the database and map. Geocoding (Block, 1995) is the process of assigning a location, usually in the form of coordinate values (points), to an address by comparing the descriptive location elements in the address to those present in the reference material. As mentioned before, this study utilizes US census TIGER file as a reference file to geocode 9,337 crime records. Throughout two rounds of automatic matching, and two rounds of interactive matching, 98 % of data was mapped and the point map of crime occurrence was generated.
A number of simple global statistics tests can be utilized to understand general patterns in the crime data spatial distribution. This study employs mean center and standard deviation distance to show the center point of each crime type and general dispersions. The mean center is the average x and y coordinate of all crime points (Mitchell, 2005). The mean center is given as:
where xi and yi are the coordinates for crime point i, and n is equal to the total number of crime points. Since this is very effective to show center point of crime, the mean center is also used for temporal analysis in this study.
The standard distance provides a single value indicating the dispersion of points around the center (Mitchell, 2005). The value is a distance, and the compactness is drawn as a circle with the radius equal to the value. The standard distance is given as:
where xi and yi are the coordinates for crime point i, (
The mean center and standard distance provides information regarding the center crime point and dispersion. However, it is necessary to test the clustering of crimes for crime hot spot identification. This study employs the nearest neighbor index and the spatial auto correlation tests to present the clustering of crime distribution. The nearest neighbor index calculates the distance between each crime location and its nearest neighbor’s crime location. All the nearest neighbor distances are averaged. If the average distance is less than the average for a hypothetical random distribution, the distribution of the features being analyzed are considered clustered. If the average distance is greater than a hypothetical random distribution, the features are considered dispersed. The index is expressed as the ratio of the observed distance divided by the expected distance (Ebdon, 1985). Therefore, the nearest neighbor index less than 1 indicates clustering of crime locations whereas the nearest neighbor index greater than 1 indicates a uniform pattern of crime locations. The nearest neighbor index is given as:
where
where di is the distance between crime location i and its nearest crime location, n corresponds to the total number of crime locations and A is the total study area.
A z-score test statistics can be offered to support confidence in the nearest neighbor index. This test describes how different the actual average nearest neighbor distance is from the average random nearest neighbor distance. The general rule to follow is that the more negative the z-score, the more confidence can be placed in the nearest neighbor index (Eck, Chainey, Cameron, Leitner & Wilson, 2005). The z-score for the nearest neighbor index is calculated as:
where:
Spatial autocorrelation techniques assess whether the distribution of point events are related to each other. Positive spatial autocorrelation indicates the crimes are clustered. Moran’s I test is commonly used for crime event clustering (Chakravorty, 1995). This technique is based on both crime locations and crime values simultaneously. Given a set of crimes and associated values, it tests whether the pattern expressed in clustered, dispersed, or random. In general, a Moran’s index value near +1.0 indicates clustering while an index value near -1.0 indicates dispersion (Goodchild, 1986). The z-score test provides statistical significance of this index. The Moran’s I statics for spatial autocorrelation is given as:
where zi is the deviation of an value for crime i from its mean (
The z-score of this test is calculated as:
where:
In general, higher positive number places more confidence in Moran’s I. Since this test requires crime location and intensity value, this study summarizes the crime points into a census block layer based on spatial location. The center point of each census block is utilized as crime location and the number of crimes in each census block is used as the intensity value (concentration). The Euclidian distance is employed as a distance calculation method. Since the number of crime occurrence is summarized into different size of census block polygons where as NNI directly incorporating individual crime locations, the result of this method is not always valid. Thus, the results between the two methods could show some differences. Due to the limitations, this study mainly rely on NNI for clustering analysis and the Moran’s I is used as supporting index.
There are many ways to map crime hot spots. A popular technique for representing spatial distribution of crime is geographic boundary thematic mapping. This study uses census blocks as geographic boundaries. Crime locations mapped as points are aggregated to the census blocks. These counts by census blocks are thematically mapped to display the spatial pattern of crime in the city of Alice, TX. However, the thematic mapping only shows the spatial distribution, and has limitations for identifying crime hot spots statistically. To overcome this limitation, this study uses quadratic kernel density statistics.
The quadratic kernel density is the most suitable method for visualizing crime data as a continuous surface (Chainey, Reid, & Stuart, 2002). The quadratic kernel density method calculates the density of crime locations around each output raster cell. This method fits a smoothly curved circular surface (kernel surface) over each point where the radius of the surface is set by a user. The value of the surface is highest at the crime point and decrease as it reaches the radius of the kernel surface. The density at each output raster cell is calculated by adding the values of all the kernel surfaces where they overlay the raster cell center (Silverman, 1986). This method requires two parameters to be set; grid cell size and search radius. The larger grid cell size will result in more coarse or blocky-looking maps while the smaller grid cell size shows the better visual appeal of the continuous surface. The increasing search radius does not change the output density values. However, the larger search radius shows a more generalized output raster where the smaller search radius shows smaller and narrowed down hot spots. This study uses 20m for the grid cell size for better visualization of relatively small study area and 250m for the search radius (band width). The small bandwidth is effective to show only highly concentrated area. However, the small bandwidth size has limitations to figure out secondary hot spots. The bandwidth 250m is optimal to show primary and secondary crime hot spot in different land-use and socio-economic characteristics. The areas in top 35% of density are defined as primary crime hot spots and 36% to 66% of density areas are considered as secondary crime hot spots. This study used spatial statistics tools and spatial analyst tools of ArcGIS 9.3® for the output calculations described in this section.
3.2 Spatio-temporal Analysis
The geostatistical methods mentioned above provide information on crime distribution including center point, clustering, and hot spot. The spatial characteristics of each crime pattern will be linked to physical and socio-economic information to identify the vulnerable area against each type of crimes. The spatial distribution will provide clues on vulnerable land use, population density, percent Hispanic population, and median house income. Moreover, the variation of crime distribution in time is analyzed based on the spatial distribution and corresponding physical and socio-economic information. It visualizes space and time interaction on crime occurrence.
This study subdivides a 24 hour day into three different time periods. The first time period represents dormant time when most people are in bed and least amount of life activities are happening, 0:31 to 7:30. The second time period represents working period when most people are working and the most of amount of life activities are happening, 7:31to 17:30. The third period indicates the rest period when most people rest and prepare for the next day, 17:31 to 0:30. Depending on the type of crime, the temporal distribution of crime varies. It is summarized in Table 1. The subdivided crime data is geostatistically tested to identify spatio-temporal characteristics of each crime type.

Temporal Distribution of Property Crime, Violent Crime, Drug Crime, and Traffic Accidents of Alice, TX
4. Results and Discussion
4.1 Spatial pattern of crimes
As mentioned in the previous section, the mean center and the standard distance provides center location of the crime and dispersion of the crime. Based on the 2,734 records of property crime location, the mean center of property crime is located in the center of the city where the commercial area is concentrated (Fig. 5). Due to the large volume of data and dispersed crime distribution, the standard distance draws larger circles compared to other types of crimes showing 1,682m of radius. This tells that the property crime shows the most dispersed crime pattern of all crime types. The mean center of violent crime is also located in the commercial area close to the city center about 500m southwest of the property crime mean center based on 989 points. Compared to the property crime, the violent crime draws a smaller standard distance of 1,513m radius (Fig. 6). The drug crime points to the commercial area in the city center as the mean center which is only 130m from the violent crime mean center (Fig. 7). The radius of standard distance for drug crimes is 1,430m which is close to that of the property crime although the number of points mapped (362) is a lot smaller than other types. The 1,209 points of traffic related events calculate the mean center located 30m from the property crime mean center. The standard distance is 1,568 m (Fig. 8).
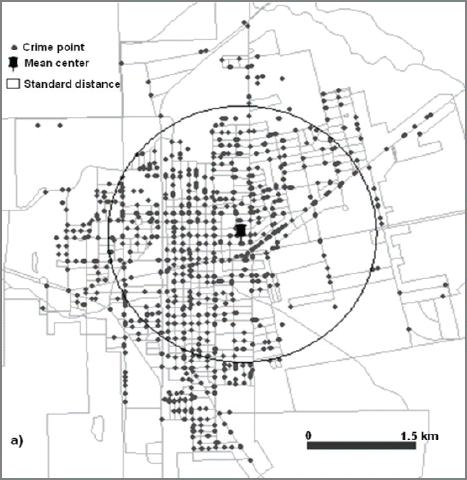
Crime Location, Mean Center, and Standard Distance of Property Crime

Crime Location, Mean Center, and Standard Distance of Violent Crime

Crime Location, Mean Center, and Standard Distance of Drug Crime

Crime Location, Mean Center, and Standard Distance of Traffic Accidents
Considering all crime types together, the mean centers are located in 800m radius in the city center most likely in a commercial area. The dispersion is lowest in violent crimes and is highest in property crimes.
The nearest neighbor index (NNI) and Moran’s index (Moran’s I) on spatial autocorrelation are calculated to test clustering of each crime type and are summarized in Table 2. The nearest neighbor index is calculated based on the point location, and the Moran’s I is calculated on the basis of census block polygons with summed number of points in each block as the intensity value. The NNI indicates strong clustering for all four types of crimes with the highest clustering in property crimes of 0.2 at confidence level of –79.45 z-score whereas the standard distance informed the most dispersion. The drug crime is listed as the weakest clustering of all four types showing 0.42 NNI with –20.81 z-score. The spatial autocorrelation also supports the clustering of all crime types with a high confidence level. However, this index implies the highest clustering on traffic events with 0.06 and weakest clustering on property crimes. This study gives more significance on NNI because it is not biased by the size of census blocks and higher confidence level.

Summary of NNI and Spatial Autocorrelation for Each Crime Type
The choropleth map is created for each type of crime showing the number of crimes in each census block. The property crimes are mapped the most in the commercial area along the main street (Fig. 9).
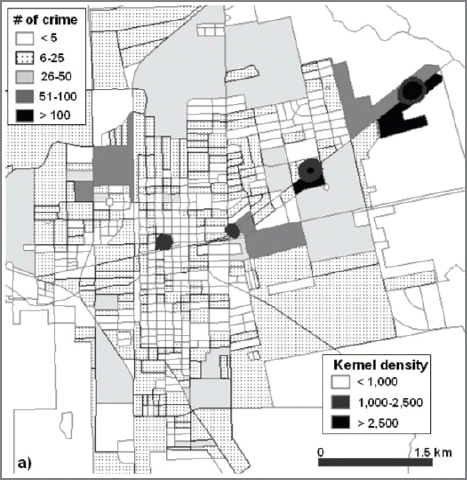
Kernel Density Grids Overlaid on Thematic Maps of Number of Property Crime
Checking the census blocks with six or more crimes, 1,536 crimes occurred in a 3.91km2 area. It indicates 42% of property crimes are concentrated in only 10% of the city area. 1,131 out of 1,536 crimes occurred in commercial area. Since the socio-economic data for the commercial area is not available, a lot of property crime can not be characterized in socio-economic vulnerability. However, the socio-economic characteristics of the high property crime residential area shows the median house income ranging from $ 20,000 to $ 53,000 with an average median income of $ 32,000, the population density from 181 to 3,216 /km2 with the average of 1,093. Compared to the city average of $30,000 for median household income and 1,327 for population density, it is most likely the average level residential area has the highest probability for property crime next to the commercial area. The percent of Hispanic population does not show any characteristic numbers. The hot spot of the property crime mapped by kernel density method is distributed in the commercial areas along the main street crossing the town EW. The higher crime density is located in the commercial area in the NE side of the city. No residential area is overlapped with hot spot areas.
The violent crime shows quite a different pattern from the property crimes (Fig. 10). There are many residential blocks with high numbers of violent crimes. Only four commercial blocks are identified to have more than 15 violent crimes whereas twelve residential blocks are mapped with more than 15 violent crimes. The socio-economic data shows average median house income of $30,000 and a population density of 1,231. This may provide the impression of average level life style vulnerable to violent crime. However, the hot spot distribution shows bimodal distribution. The highest density is mapped over the commercial area and lower average median house income ($12,000) in the west of the city center. The second highest density is mapped over the commercial and residential area with average median house income of $30,800.
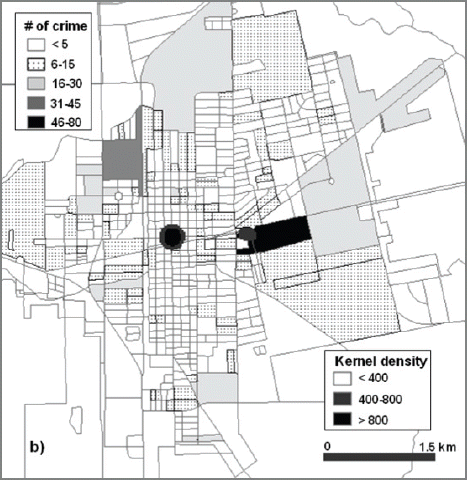
Kernel Density Grids Overlaid on Thematic Maps of Number of Violent Crime
The drug crimes show an even more dispersed pattern at various land use types, although the frequency and intensity is relatively low compared to that of property and violent crimes (Fig. 11). A lot of small patches of commercial area are mapped with higher drug crimes across the study area. 14 of 20 census blocks with 153 crimes are mapped in commercial land use with more than 5 drug crimes where as 63 crimes are mapped over the high drug crime residential area. The hot spots are distributed over the commercial areas and residential areas with low median house incomes ranging from $12,000 to $18,000 and high Hispanic population areas showing 90% to 100% Hispanic population which is the poorest area of the city. The traffic events are highly concentrated in commercial areas with more than 90 % of the events occurred in the commercial area (Fig. 12). There are no socio-economic characteristics identified. All the hot spots are mapped along the main street with higher concentration in northeast side of downtown.

Kernel Density Grids Overlaid on Thematic Maps of Number of Drug Crime
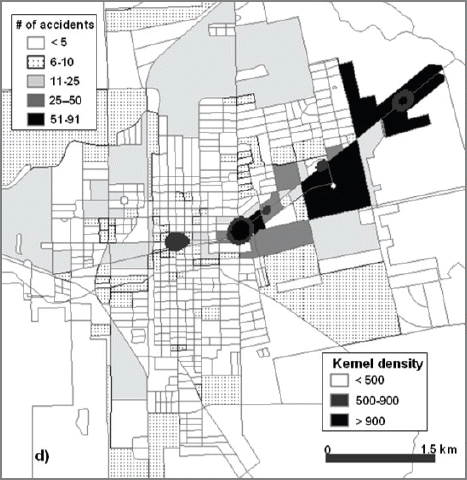
Kernel Density Grids Overlaid on Thematic Maps of Number of Traffic Accidents
4.2 Spatio-temporal characteristics of crime occurrence
There are noticeable temporal changes in the number of property crimes. More than half of the property crimes occurred during day time (T2) where as only 13 % of crime occurred during dormant times (T1). Moreover, the spatial distribution and clustering of crimes also varies temporally. The mean centers of property crimes move from commercial areas to residential areas located in the city center shifting northeast 600m between T1 and T2 and 200m between T2 and T3. The standard distance increased from 1,611m at T1 to 1,969m at T3 indicating higher dispersion during evening periods (T3) (Fig. 13).
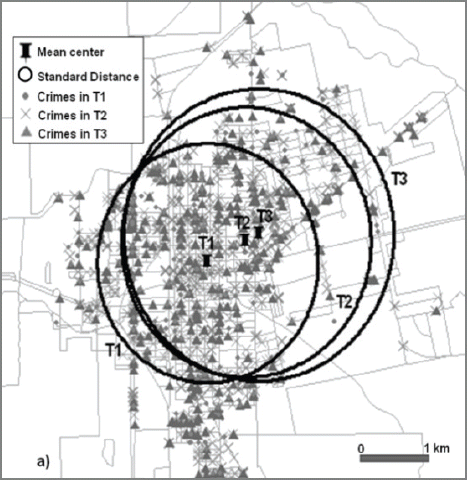
Spatio-temporal Analysis of Property Crimes; Mean Center and Standard Distance
The clustering of property crimes is strongest during day time (T2) whereas the weakest clustering is found during dormant time (T1) (Table 3). However, in general, all time periods show strong clustering with high confidence levels based on NNI and Moran’s I (Table 3).

Temporal Change of NNI and Spatial Autocorrelation of Property Crimes
The hot spot maps show very well defined variations in spatial distribution of property crimes over time (Fig. 14). Significant portion of property crimes occurred in residential areas during T1 while T2 and T3 show high concentrations in commercial areas. In addition, the spatial distribution during T1 is dispersed over the city. The socio-economic characteristics reveal that the residential areas with below average median house incomes ($20,000~$30,000) and with high Hispanic populations (90% or more) are exposed to property crimes. The day time property crimes are evenly located in commercial areas along the main street in EW whereas the commercial areas in northeast are the property crime centers during the evening.
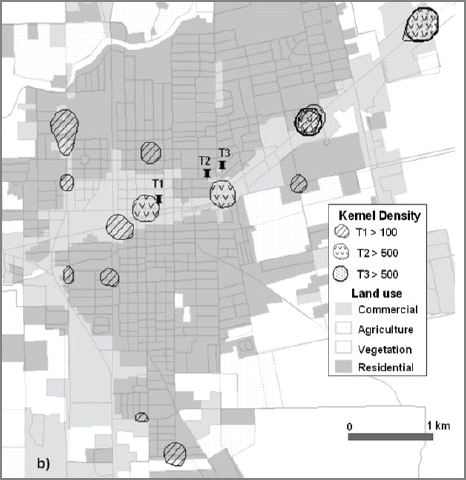
Spatio-temporal Analysis of Property Crimes; Hot Spots Overlaid on Land Use Land Cover Map
The violent crime shows relatively low spatial and crime number variations over the time periods. The mean center of T1 and T3 are almost identical and that of T2 is located only 300m shifted to the northeast located in the city center commercial area (Fig. 15). The standard distance ranges from 1,453m at T3 to 1,566m at T2 indicating less dispersion than property crimes. The clustering is relatively weak during evening time period showing NNI of 0.87 while the other two time periods show stronger clustering with high confidence (Table 4). However, even NNI of T3 shows strong clustering in general. The spatial autocorrelation also shows strong clustering for all three time periods. The hot spots of violent crimes at T2 and T3 are very identical in terms of size and location. Those are located at the commercial area in lower income areas which is the western side of the city center. Conversely, the hot spots during dormant time period (T1) are more dispersed over the residential and commercial area (Fig. 16).
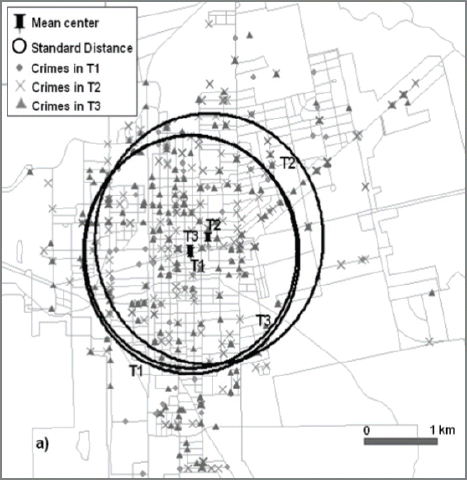
Spatio-temporal Analysis of Violent Crimes; Mean Center and Standard Distance

Temporal Change of NNI and Spatial Autocorrelation of Violent Crimes
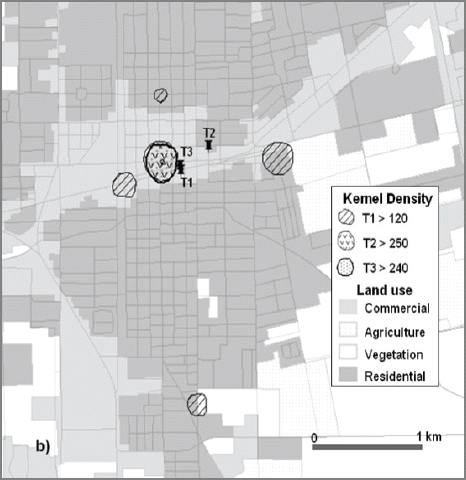
Spatio-temporal Analysis of Violent Crimes; Hot Spots Overlaid on Land Use Land Cover Map
The socio-economic information shows a very broad range with the median house income from $12,000 to $30,000 and Hispanic population of 79% to 100%. However, in general, it is more probable that residential areas with below average house income and with higher Hispanic populations are vulnerable against the violent crimes during the night time (T1).
The drug crimes mainly occur during evening and night times showing a higher number of crimes compared to day time. It is very different from other types of crimes. In addition, the drug crimes show more shift between the time periods. The mean center of drug crime shifts about 600 m to the northeast from between T1 and T2 and shifts back to the southwest 500 m between T2 and T3. The mean centers are located in low income commercial and residential areas near the city center and west of the city center. The standard distance is ranging from 1,383 m at T1 to 1,428m at T3 indicating the least amount of dispersion in all crime types (Fig. 17). The clustering of drug crimes does not vary over the time showing strong clustering of 0.58 to 0.61 NNI (Table 5).

Spatio-temporal Analysis of Drug Crimes; Mean Center and Standard Distance

Temporal Change of NNI and Spatial Autocorrelation of Durg Crimes
Although the relatively large number of drug crimes occurred during dormant time (T1), the hot spots at T1 show diverse locations in commercial and residential areas. Many of the hot spots are located in the west side of the city in commercial and residential areas with low median income (<$20,000) except one commercial area in the east (Fig. 18). During the day time (T2), the commercial area is majorly used as drug crimes. In the evening (T3), the western commercial and residential areas near the city center are mapped as drug crime hot spots.
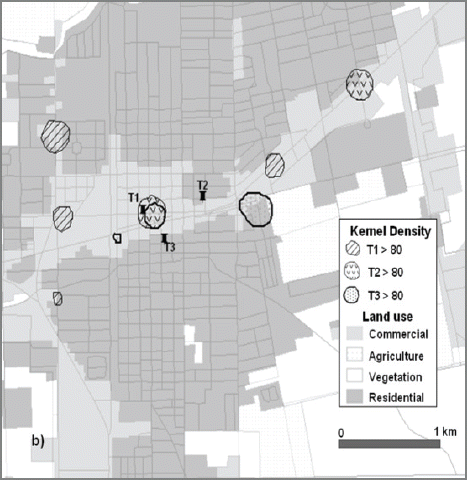
Spatio-temporal Analysis of Drug Crimes; Hot Spots Overlaid on Land Use Land Cover Map
The traffic events are plotted along the streets in commercial areas (Fig. 19). The mean center of traffic events is shifting 500m back and forth between the time periods. The standard distances are consistent throughout each time periods around 1,550m. Clustering is strong during T2 and T3 whereas it shows the weakest clustering during dormant time (T1) among all time periods of all crime types (Table 6). It reveals there are no specific spatial or physical characteristics on traffic events in dormant time when most of the commercial areas are closed.
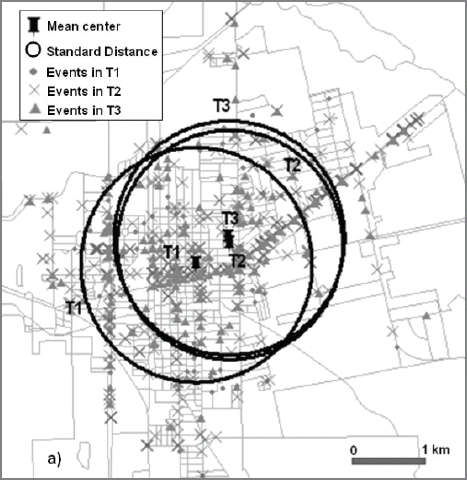
Spatio-temporal Analysis of Traffic Events; Mean Center and Standard Distance

Temporal Change of NNI and Spatial Autocorrelation of Traffic Events
The hot spots of traffic events are distributed over the commercial area except one small patch in a residential area at the northeastern end of the city. The traffic events during dormant time (T1) touch almost all of the commercial area over the study area whereas T2 and T3 are mapped over the main commercial bend in the city center along the main street. The hot spot in the northeast corner shows the highest density for both T2 and T3.
5. Conclusion
This study employed various geostatistical models to identify crime centers, clustering, and hot spots for four different types of crimes; property crime, violent crime, drug crime, and traffic events. The spatial and temporal characteristics of four different types of crimes are investigated for the first time in the study area. Moreover, the physical environment, and socio-economic data is related to the spatial and temporal variations of each crime type. As a result the vulnerable attributes and spatial characteristics of each crime type over the time are clarified. The spatio-temporal characteristics of each crime type can be concluded as following.
First, property crimes show strong clustering at all time periods of day. Commercial areas are considered as the hot spots of property crimes from morning to midnight. From midnight to morning, the residential areas with below median house income and high Hispanic population are most likely vulnerable against property crimes.
Second, the frequency of violent crimes does not show much variation with time periods. However, the clustering is relatively weaker during the dormant time period although the general clustering for this type is strong. Commercial areas are the main hot spot of violent crimes from morning to midnight whereas the residential area below average life style is more exposed during dormant time.
Third, the drug crimes occur in residential areas in below average income areas mainly during the night time. The commercial area is mainly used for drug crimes during daytime. The spatial pattern of drug crimes shows strong clustering for all time periods.
Fourth, traffic accidents and events are highly concentrated in commercial areas at all times showing strong clustering. But, some of the residential areas are included as hot spots for traffic events from midnight to morning with very weak clustering, and it does not show any specific socio-economic characteristics.
This study suggests methodological approach to identify spatio-temporal crime hot spots in consideration of their socio-economic characteristics. Low income residential areas with high Hispanic population ratio are claimed to be vulnerable to property crimes and also violent crimes, which implies an emerging topic in Korean crime hot spot research. Considering Korean government’s multi-cultural policy fighting against population decline from 2018, future crime hot spot studies in Korea need to address physical and economic conditions and also social factors which includes demographic origins and cultural backgrounds. Korean government, Ministry of Public Safety and Security (MPSS) provides Korea Safety Map, which informs hot spots of four crime types of robbery, theft, sexual violence, and violent crimes. Future Korean studies addressing socio-economic conditions on the basis of the map would help allocating police resources and public security services effectively and also identify vulnerable areas where physical, social, and economic conditions need to be addressed and improved.
Acknowledgements
This study has been supported by the internal grant program of Dong-A University.