주성분 분석과 로지스틱 회귀모형을 이용한 호우피해 예측함수 개발
Development of Heavy Rain Damage Prediction Function Using Principal Component Analysis and Logistic Regression Model
Article information
Abstract
본 연구에서는 낙동강 권역을 대상으로 주성분 분석과 로지스틱 회귀모형을 적용하여 호우피해 예측함수를 개발하였다. 주성분 분석을 통해 상관성이 높은 설명변수를 사용할 수 있는 방안을 제시하였고, 로지스틱 회귀모형을 이용하여 피해액이 큰 집단과 작은 집단으로 분류한 다음, 구분된 각 집단에서 호우피해 예측함수를 개발하였다. 최종적으로 선정된 모델의 예측력을 실제피해액과 예측피해액을 비교하여 NRMSE(Normalized Root Mean Squared Error)로 평가한 결과, 12.44%로 낙동강 권역의 호우피해를 적절하게 예측하는 것으로 나타났다. 따라서 본 연구에서 개발한 낙동강 권역의 호우피해 예측함수를 활용하면, 호우피해 발생 전에 사전 대비 차원의 재난관리를 실시할 수 있을 것이다.
Trans Abstract
In this study, we developed heavy rain damage prediction functions for Nakdong river basin by using principal component analysis and logistic regression model. The principal component analysis can be used for the determination of explanatory variables which are highly correlated with the damage. Then the determined variables could be used as the independent variables for the development of heavy rain damage prediction functions. The logistic regression model classified heavy rain damages into two data groups of small and large damage values. Then the functions for two data groups could be developed. Finally, the function performances were assessed by comparing the observed damages and predicted damages. And we obtained NRMSE(Normalized Root Mean Squared Error) of 12.44%. Therefore, we can use the developed heavy rain damage prediction functions in the Nakdong river basin area for preparing for disaster occurred by heavy rainfall and also for the effective disaster management for damage reduction.
1. 서론
기후변화로 인해 자연재난의 피해는 전 세계적으로 더욱 강력해지고 있다(Choi et al., 2016). 또한 도시화 및 산업화에 따른 불투수면적의 증가로 인해, 집중호우에 따른 도시침수와 홍수피해가 심화될 것으로 예상되고 있다(Kim et al., 2015). 방재 선진국인 미국과 영국 등에서는 자연재난으로 인한 피해를 사전에 예측하여 피해를 저감하는 노력을 하고 있지만, 우리나라는 아직까지 사후 복구 위주의 재난관리가 진행되고 있다. 만약 재난 발생 전에 피해규모를 예측할 수 있다면, 적절한 재난관리를 통해 피해를 저감할 수 있을 것이다.
자연재난 피해를 사전에 예측하는 국외 연구사례를 살펴보면 Mandal et al. (2005)은 인공신경망(Artificial Neural Network, ANN)을 이용하여 홍수 피해액을 종속변수로 하는 홍수피해 예측모형을 개발하였다. 설명변수로는 해당 지역에 위치하는 센서에서 제공하는 기온, 습도, 지하수위, 강우, 풍속 자료를 사용하였다. Prahl et al. (2012)은 독일 439개의 지자체를 대상으로 Winter Storms 피해 예측함수를 개발하였다. 독일 보험협회에서 제공하는 1997년부터 2007년까지의 보험 손실 자료를 종속변수로 사용하였고, 일최대풍속을 설명변수로 사용하였다. Zhai and Jiang(2014)은 Multi-variate least squares regression을 이용하여 허리케인으로 인한 피해를 예측하는 함수를 개발하였다. 미국에서 발생한 1998년부터 2012년의 73개의 열대 저기압의 최대풍속과 storm의 크기 자료를 수집하였고, 이를 설명변수로 사용하였다. ICAT에서 제공하는 보험 손실 데이터를 종속변수로 사용하여 허리케인으로 인한 피해를 예측하는 함수를 개발하였다. Kim et al. (2016)은 미국 Texas를 대상으로 다중회귀모형을 이용하여 허리케인 피해를 예측하였다. Texas Windstorm Insurance Association에서 제공하는 500개의 허리케인으로 인한 상업시설의 피해를 보험 지급금으로 나눈 비율을 종속변수로 사용하였고, 설명변수로 건물의 수명, 면적, 가치와 최대 풍속 등을 사용하였다.
국내의 연구사례를 살펴보면 Choi(2010)은 신경망과 유전자 알고리즘을 이용하여 자연재난 피해 예측모형을 제안하였다. 설명변수로 누적 강우량, 최대풍속, 재해사상 발생 5일 이내의 선행강우량을 사용하였고, 총 피해액을 종속변수로 사용하였다. Yang et al. (2016)은 다중회귀모형을 이용하여 태풍으로 인한 건물피해율 예측함수를 개발하였다. 2003년부터 2014년까지 국내에 상륙 또는 영향을 미친 태풍을 경로별로 분류하고 태풍정보요인, 지리정보요인, 건설환경요인을 설명변수로 사용하였다. Lee et al. (2016)은 경기도 3개 지역을 대상으로 비선형 회귀식을 이용한 홍수피해액 예측함수를 개발하였고, Choi et al. (2017)은 한강 권역을 대상으로 선형회귀모형, 일반화선형모형, 주성분 회귀모형, 인공신경망 모형을 적용하여 호우피해 예측함수를 개발하였다. Kim et al. (2017)은 호우피해 위험도 지수를 개발하고, 이를 통해 군집화된 지역별 호우피해 예측함수를 개발하였다. Choo et al. (2017)은 행정안전부(구 국민안전처)에서 제공하는 1993년부터 2014년까지의 풍랑피해 자료를 종속변수로 하는 풍랑피해 예측함수를 개발하였는데, 설명변수로 유의파고, 최대파고, 풍속, 조위, 연안재해노출지수, 연안민감도지수, 연안재해영향지수 등을 고려하였다.
국내⋅외 연구를 살펴보면, 주로 피해액의 범위가 넓은 재난 피해의 특성을 고려하지 못하고, 모든 피해액을 하나의 함수로 예측하려고 하다 보니 예측력이 낮아지는 결과들이 도출되었다. 따라서 본 연구에서는 로지스틱 회귀모형을 적용하여 피해액이 큰 집단과 작은 집단으로 구분하였고, 집단별 함수식을 개발하여 피해액의 범위가 넓어서 예측력이 떨어지는 문제를 해결하였다.
2. 주성분 분석과 로지스틱 회귀모형
본 연구에서는 주성분 분석을 이용하여 다양한 설명변수들을 사용시에 다중공성성 문제가 발생하는 문제를 해결하였고, 로지스틱 회귀모형을 이용하여 피해액이 큰 집단과 작은 집단으로 구분하여 호우피해 예측함수를 개발하였다.
2.1 주성분 분석
데이터를 이용해 모형 적합 시 변수의 개수가 너무 많아 모형에 적용할 수 없는 경우가 있는데, 이러한 경우 주성분 분석(Principle Component Analysis)을 이용하여 변수의 개수를 축소하는 방법을 고려할 수 있다. 특히 변수 사이의 강한 선형관계 때문에 설명변수를 선택하기 어려운 경우, 주성분 분석을 통해 소수의 주성분을 설명변수 대신 사용하는 것이 가능하다. 이러한 소수의 주성분은 설명변수의 대부분의 변동(variation)을 포함하고 있으므로 사실상 설명변수의 정보의 대부분을 보유하고 있으므로 좋은 대안이 될 수 있다. 주성분 분석은 변수들의 공분산행렬이나 상관행렬을 이용하여 변수들의 선형결합으로 적은 차원의 새로운 변수, 즉 주성분(Principal Component)이라고 부르는 서로 상관되어 있지 않은 새로운 변수를 찾아낸다. Fig. 1은 주성분 분석의 개념도를 나타낸 것이다.

Conceptual Diagram of Principal Component Regression Analysis
주성분 분석에 있어 신뢰도 검정이 선행되어져야 한다. 신뢰도 검정은 주성분 분석의 적용 가능성을 판단하며, 방법으로는 KMO(Kaiser Meyer Olkin) 테스트, Bartlett 테스트, 편상관계수 값의 부호를 반전시킨 역상관계수(Anti-image correlation)의 값, 개별 변수에 대한 표본적합성 측도(Measure of Sampling Adequacy, MSA) 등이 있다. 주로 사용되는 KMO 테스트는 잔영상관행렬(Anti-Image Correlation Matrix)을 사용하여 계산된 통계량으로 자료가 주성분 분석에 적합한지를 판단하며, Bartlett 테스트란 모집단으로부터 추출한 표본의 상관계수 행렬의 행렬식 값을 계산하여 상관계수 행렬이 단위행렬인지 아닌지 카이제곱 분포를 이용해서 검정하는 방법을 말한다. 적용기준은 KMO 테스트의 표본적함도가 0.6 이상이거나, Bartlett 테스트의 유의확률이 0.05 이하일 때 적용이 가능하다.
만약 확률벡터 X=(X1, X2, …, Xm)가 평균벡터 μ와 공분산행렬 Σ를 갖는다고 가정한다면, Σ의 대각원소는 각 확률변수의 분산
주성분 변수 Y=(Y1, Y2,…, Ym)의 공분산행렬은 고유값과 고유벡터의 성질에 의해 Eq. (1)과 같음을 보일 수 있다.
여기서 Λ는 Σ의 고유값 λ1, λ2,…, λm를 대각원소로 하는 대각행렬이다. 위의 식은 주성분 Y1, Y2,…, Ym는 서로 상관성이 없고, 기하학적으로 이들 주성분들은 원래의 축을 직교 회전한 것임을 의미한다. 그리고 주성분λj의 분산이λj임을 나타내는데, 고유값들은 λ1 ≥ λ2, ≥ … ≥ λm로 가정했으므로 첫째 주성분 Y1은 변수X1, X2, …, Xm의 선형결합 중에서 가장 큰 분산을 갖고, 마지막 주성분 Ym는 가장 작은 분산을 갖는 선형결합임을 의미한다. X의 공분산행렬 Σ의 대각원소들의 합(즉, Xi분산들의 합)은 Eq. (2)와 같이 모든 고유값들의 합(즉, 주성분Yi들의 분산들의 합)과 같음을 보일 수 있다.
고유값은 크기순으로 정렬되어 있기 때문에 주성분의 분산 몇 개가 전체 변수들의 분산합의 많은 부분을 설명할 수도 있음을 의미한다. 즉, 소수 k개의 주성분Y1, Y2,…, Yk의 분산만으로 전체 m개의 Xi의 분산을 잘 설명할 수 있다는 뜻이다. 주성분 분석은 공분산행렬보다 상관행렬을 이용하는 경우가 많다. 만일Xi변수들을 표준화 하였다면 X=(X1, X2, …, Xm)의 공분산행렬은 상관행렬이 되고, 이때 주성분 Y=(Y1, Y2,…, Ym)의 분산의 합은 m이 된다. 이 경우 주성분의 분산(고유값)이 1보다 크면, 이 주성분의 공헌도가 평균 1보다 큼을 알 수 있다. 전체 X1, X2, …, Xm개의 변수대신 공헌도가 1보다 큰 적은 수의 주성분 Y1, Y2,…, Yk로 차원을 축소하여 분석을 한다.
2.2 로지스틱 회귀모형을 이용한 집단분류
피해액의 범위가 넓어서 예측력이 떨어지는 문제를 해결하기 위해, 호우피해가 “피해액이 큰 집단”과 “피해액이 작은 집단”의 서로 다른 두 집단으로 이루어졌다고 가정하였다. 피해액이 큰 집단과 작은 집단을 분리하기 위해서는 특정 피해액을 기준으로 분리시켜주는 분류 모형이 필요한데, 정확히 어떤 수준에서 집단을 분리해야 할지 알 수 없으므로 주어진 데이터셋에서 통계적 모형화를 통해 최적의 값을 검출하기로 하였다.
우선 피해액의 백분위수(10, 15, …, 90, 95)를 기준으로 두 집단을 분리할 수 있다고 가정하고 특정 분위수를 기준으로 그룹을 나누었을 때, 피해액이 크면 1, 피해액이 작으면 0의 이항(binary) 범주를 갖는 집단 구분을 위한 범주형 변수를 생성하여 집단별 회귀모형을 생성하였다. 그러나 실제 예측에서는 설명변수의 정보만 주어지고 종속변수의 정보만 주어지지 않으므로 이미 구축해놓은 “피해액이 큰 집단”의 모형과 “피해액이 작은 집단”의 모형 중 어느 것을 이용하여 피해액을 예측해야 할지 알 수가 없다.
따라서 “피해액이 큰 집단”과 “피해액이 작은 집단”을 분류할 수 있는 분류모형을 주어진 데이터로부터 개발하여 미래 설명변수의 값이 주어졌을 때 집단이 분류될 수 있도록 해야 한다. 이를 위해 현재 집단을 특정 피해액을 기준으로 분류한 이항(binary) 범주형 변수를 종속변수로 이용하여 로지스틱 회귀모형을 구축하였다. 구축된 로지스틱 회귀모형은 설명변수가 주어졌을 때, “피해액이 큰 집단”으로 분류될 확률값을 제시한다. 그런데 정확히 확률값이 얼마 이상이어야 “피해액이 큰 집단”으로 분류하여야 할지에 대한 알려져 있는 기준 또한 주어져있지 않으므로 주어진 데이터를 통해 최적의 값을 추론하여야 한다. 이를 위해 로지스틱 회귀모형의 학습과정에서 계산되는 검증용 데이터에 대한 ROC(Receiver Operating Characteristic) 곡선을 참고하여, 이 곡선 아래의 면적인 아래 면적인 AUROC(Area Under ROC)를 최대화하는 확률 경계를 최적의 분류 경계값으로 선정하였다. 이러한 확률 경계는 미래 피해액의 예측에서 설명변수 정보만 주어졌을 때, 피해액을 어떤 집단으로 분류할지 결정하는 중요한 역할을 하게 된다. 실제 자료 분석 시에는 학습용 데이터는 k-등분하여 k-분할 교차검증법(k-fold Cross-validation)을 적용한 CV-AUROC(Cross-validated AUROC)를 참고하여 확률 경계값을 찾는다.
3. 대상지역 선정 및 자료 구축
주성분 분석과 로지스틱 회귀모형을 이용한 호우피해 예측함수를 개발하기 위해 낙동강 권역을 대상지역으로 선정하였고, 해당 지역의 자료를 수집하여 종속변수와 설명변수를 구축하였다.
3.1 대상 지역 선정
본 연구의 대상 지역은 낙동강 권역으로 선정하였다. 낙동강 권역은 경상남도, 경상북도, 강원도, 부산광역시, 대구광역시, 울산광역시로 이루어져 있으며, 총 69개의 시군구를 포함하고 있다. Fig. 2는 낙동강 권역의 행정구역을 나타낸 것이다.
Target Area
3.2 종속변수 산정
낙동강 권역의 호우피해 예측함수를 개발하기 위해 종속변수로 행정안전부(구 국민안전처)에서 매년 자연재난 피해를 집계하여 제공하는 재해연보의 자료를 활용하였다. 재해연보에 집계된 2005년부터 2015년까지의 시군구별/재해기간별 호우피해액을 종속변수로 활용하였으며, 과거의 화폐가치와 현재의 화폐가치가 다르기 때문에 이를 현재의 가치로 환산해야 한다. 본 연구에서는 재해연보에서 사용한 방법과 동일하게 생산자 물가지수를 이용하여 2015년을 기준으로 현가화 하였다. Table 1은 생산자 물가지수를 고려한 연도별 환산지수를 나타낸다.

Conversion Index Considering the Producer Price Index
3.3 설명변수 산정
본 연구에서는 호우피해 예측함수의 설명변수로 선행강우량(1~7일), 총 강우량, 지속시간별 최대강우량(1~24시간), 재해일수, 시군구 면적을 사용하였다. 선행강우량은 재해 시작 1~7일전의 누적 강우량을 의미하며, 총 강우량은 재해기간 동안의 누적 강우량이다. 또한 지속시간별 최대강우량은 재해기간 동안의 지속시간 1~24시간 누적 강우량에 대한 최댓값을 의미하며, 재해일수는 재해연보상에 집계된 재해가 발생한 일자를 이야기한다. 시군구 면적은 낙동강 권역 69개 시군구별 면적을 의미한다.
선행강우량(1~7일), 총 강우량, 지속시간별 최대강우량(1~24시간)은 기상청에서 제공하는 낙동강 권역의 124개 방재기상관측장비(Automatic Weather System, AWS)의 관측치를 Thiessen 면적법을 활용하여 행정구역별 기상자료로 환산하여 사용하였다.
4. 호우피해 예측함수 개발 및 예측력 평가
3.3에서 언급한 설명변수들 중 상관성이 강한 선행강우량(1~7일)과 지속시간별 최대강우량(1~24시간)에 대한 주성분 분석을 실시하여 새로운 설명변수로 도출하였다. 또한 종속변수인 호우피해의 분포가 “피해액이 큰 집단”과 “피해액이 작은 집단”의 서로 다른 두 집단이 혼합되었다고 가정하고, 로지스틱 회귀모형을 이용하여 각 집단을 분류하였다. 이후 각 집단별 모형을 개발한 다음, 평가용 데이터에 적용하여 예측력을 평가하였다.
4.1 주성분 분석을 통한 설명변수 변환
먼저 Table 2와 같이 선행강우량(1~7일)과 지속시간별 최대강우량(1~24시간)에 대한 주성분 점수 도출을 위하여 적용성 검토를 위한 신뢰도 검정을 진행하였다. Table 2에서 볼 수 있듯이 KMO 테스트의 적용기준인 0.6 이상과 Bartlett 테스트의 적용기준인 P-Value 0.05 이하이므로 모두 주성분 분석의 적용이 가능하였다.

KMO and Bartlett’s Test Result of Independent Variables
다음으로 성분 개수를 선정하기 위하여 총 분산과 스크리도표를 활용하여 고유값이 1이상이거나, 누적 분산이 95% 이상일 때의 성분 개수로 결정하였다. 분석 결과, Table 3과 같이 4개의 성분에서 95% 이상을 차지하는 분산을 포함하였으며, 고유값이 1 이상인 성분만을 도출하였을 때 총 4개의 성분이 도출되었다.

Total Variance Explained of Independent Variables
마지막으로, 해당성분에 포함된 각 변수들을 파악하기 위하여 성분 적재량을 검토하였다. 분석 결과인 Table 4를 살펴보면 지속시간별 최대강우량(1~2시간)인 x1, x2는 성분 3으로, 지속시간별 최대강우량(3~24시간)인 x3~x24는 성분 1로 구성되었다. 선행강우량(1~4일)인 d1~d4는 성분 2에, 선행강우량(5~7일)인 d5~d7은 성분 4에 해당하는 것을 알 수 있었다.

Rotated Component Matrix of Independent Variables
지속시간별 최대강우량에 대하여 도출된 주성분 1, 2를 PC1.x, PC2.x로 선행강우량에 대하여 도출된 주성분 3, 4를 PC1.d, PC2.d로 나타냈다. 이는 향후 피해액을 분류한 각각의 집단에서 호우피해 예측함수를 개발하는데 있어 설명변수로 활용하였다. 새롭게 도출된 이 4가지 주성분은 각각 독립적이기 때문에 다중공선성의 문제도 해결이 가능하다. 또한 회전된 성분행렬을 통해 사용할 변수가 어느 성분에 포함되는지를 파악할 수 있다. 여기서 판단의 기준은 0.5~0.6 이상일 때 해당성분에 포함된다고 알 수 있다.
4.2 로지스틱 회귀모형을 이용한 집단분류
피해액을 구분하기 위한 확률
여기서 첨자 j는 지역을 의미하며, i는 지역별 i번째 호우 피해를 의미한다. region은 낙동강 권역 시도(강원도의 경우 태백시 1개만 존재하기 때문에 울산광역시와 통합하여 구축함)를 구분하는 범주형 변수이며, area는 시군구 면적(km2), Date는 재해일수, tot는 총 강우량이며, PC1.d와 PC2.d는 7개(1일전부터 7일전까지)의 선행강우량으로부터 만들어지는 주성분이고, PC1.x와 PC2.x는 24개(1시간부터 24시간까지)의 지속시간별 강우량으로부터 만들어지는 주성분이다. 이러한 주성분들은 다중공선성을 나타내는 선행강우량과 지속시간별 강우량 대신 설명변수로 사용된다.
추정된 확률
위의 모형화를 위해서는 피해액 경계값c1과 확률 경계값c2를 정해야하는데, c1에 대해서는 피해액의 백분위수(10, 15, …, 90, 95)를 할당하고, 각 c1값을 기준으로 분류된 데이터에 대해 로지스틱 회귀모형을 적합하여 계산된 CV-AUROC으로부터 확률 경계값 c2를 계산한다. 각각의 확률 경계값 c2에 대하여 집단별로 주성분 회귀모형이 적합된다.
4.3 예측력 평가
본 연구에서는 낙동강 권역에서 발생한 2005년~2012년의 실제 피해액과 설명변수를 이용하여 호우피해 예측함수를 개발하였고, 함수의 성능을 검증하기 위해 2013년부터 2015년의 실제 피해액과 모의된 피해액을 비교하였다. 예측력 평가의 척도는 RMSE(Root Mean Squared Error)를 표준화한 NRMSE(Normalized Root Mean Squared Error)를 사용하였는데 NRMSE는 Eq. (6)과 같다.
모형화에 대한 예측력 평가 결과는 Table 5와 같다. 여기서 NRMSE 값이 최소인 피해액 분위수 75%에 대응되는 피해액 경계값 1,884,242와 확률 경계값 0.479가 최적의 c1, c2가 된다.

Assessment of Predictive Power by Damaged Quantiles
4.4 최종 모형 제시
앞에서 예측력을 평가하기 위하여 2005년부터 2012년까지의 자료를 활용하여 함수를 개발하였는데, 최종모형으로 제시한 함수는 2015년까지의 자료를 모두 학습하여 회귀계수를 갱신하였고, Table 6에서 지역별로 큰 집단과 작은 집단으로 분류하는 함수, 큰 집단의 호우피해 예측함수, 작은 집단의 호우피해 예측함수를 나타냈다. 각 지역별로 피해 집단을 분류하기 위한 로지스틱 회귀모형, 피해액이 큰 집단의 주성분회귀 회귀모형, 피해액이 작은 집단의 주성분 회귀모형을 지역별 피해예측함수로 구성하였다. 최종적으로 5개 권역의 호우피해 예측함수에 해당하는 시군구의 면적을 입력하면 69개 시군구 각각의 호우피해 예측함수가 도출된다. Fig. 3은 낙동강 권역의 실제피해와 예측피해 비교의 예시를 나타낸 것이다.

Final Model
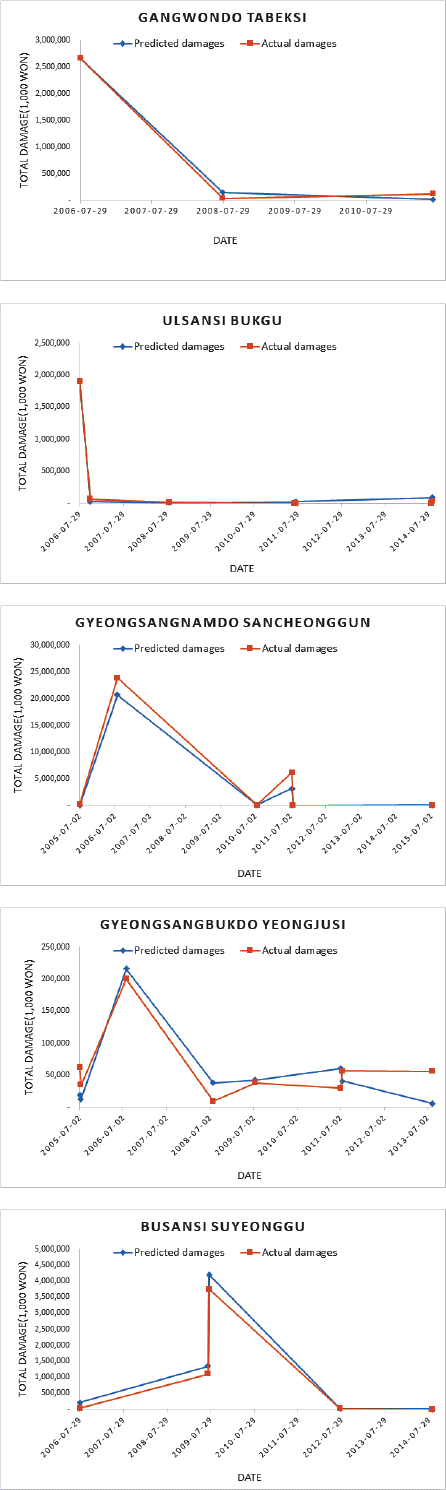
Result of Comparison Between Predicted Damages and Actual Damages of Final Model (example)
5. 결론
최근 기후변화로 인하여 극한 강우사상의 발생빈도가 증가하고 있으며, 급격한 도시화로 인해 불투수 면적이 늘어나고 있다(Han et al., 2016). 이로 인해 집중호우에 의한 홍수로 재산 피해가 증가하는 추세에 있어 피해를 저감하기 위한 적절한 대책이 필요한 시점이라 할 수 있다. 따라서 본 연구에서는 호우로 인한 피해가 발생하기 전에 시군구별로 피해 규모를 예측할 수 있는 함수를 개발하였다. 개발한 함수에 의해 예측한 피해 규모를 토대로 대비 차원의 효율적인 재난관리를 수행함으로써 피해를 저감하는데 기여하고자 하였다. 이를 위해 주성분 분석과 로지스틱 회귀모형을 이용하여 낙동강 권역의 호우피해 예측함수를 개발하였다. 주요 연구 결과를 요약하면 다음과 같다.
(1) 호우피해 예측함수의 종속변수로 2005년부터 2015년까지 시군구별/재해기간별 호우피해 자료를 사용하였고, 이를 로지스틱 회귀모형을 이용하여 피해액이 큰 집단과 작은 집단으로 분류하였다.
(2) 설명변수로 선행강우량(1~7일), 총 강우량, 지속시간별 최대강우량(1~24시간), 재해일수, 시군구별 면적을 사용하였고, 상관성이 강한 선행강우량과 지속시간별 최대강우량에 대한 주성분 분석을 실시하여 새로운 설명변수를 도출하였다.
(3) 2005~2012년의 변수를 이용하여 호우피해 예측함수를 개발하였고, 개발된 함수의 성능을 검증하기 위해 2013~2015년의 실제 피해액과 모의된 피해액을 비교하여 예측력을 평가하였다.
(4) NRMSE 값을 최소로 하는 피해액 분위수 75%에서 최적의 경계값이 선정되었고, 이때의 NRMSE는 12.44%로 낙동강 권역의 69개 시군구의 호우피해를 적절하게 예측하는 것으로 판단하였다.
(5) 선행 연구들에서는 피해액이 큰 현상을 적절하게 모의하지 못했는데, 본 연구결과에서는 피해액이 작은 사례 외에 피해액이 큰 사례에서도 적절하게 예측하는 것으로 나타나 기존의 문제점을 해결하는데 도움이 된 것으로 판단된다.
그러나 본 연구에서는 몇 가지 한계점이 있는데 우선, 각 시군구의 지역적 특징 및 사회⋅경제적 요소를 고려한 설명변수를 적용하지 못하였다. 따라서 예방사업비 및 복구비 집행액, 취약인구수, 불투수면적, GRDP(Gross regional domestic product) 등의 방재⋅인문⋅사회⋅경제적 요소를 설명변수로 사용한다면 지역 특성과 예산 투입에 따라 좀 더 예측력 높은 호우피해 예측함수를 개발할 수 있을 것으로 판단된다. 또한 설명변수로 사용한 강우자료의 경우 AWS 관측치를 사용하였는데, AWS 관측치의 경우 2005년 이후부터 신뢰할 만한 자료가 존재한다. 이로 인해 전체적인 자료의 개수가 다소 부족한 한계점이 있었다.
기존의 연구에서는 피해액의 범위가 넓은 자연재난 피해의 특징을 고려하지 못하였는데, 본 연구에서는 로지스틱 회귀모형을 이용하여 피해액이 큰 집단과 작은 집단으로 구분하여 회귀모형을 구축하였기 때문에 자연재난 피해특징을 적절하게 고려하였다. 또한 주성분 분석을 이용하여 상관성이 높은 설명변수들을 사용할 수 있는 방안을 제시하였다. 본 연구결과를 활용하면 호우 피해가 발생하기 전에 낙동강 권역 69개 시군구에 대한 신속한 피해 예측이 가능하며, 이를 통해 사전 대비 차원의 재난관리를 실시하여 호우로 인한 피해를 저감할 수 있을 것으로 사료된다.
감사의 글
본 연구는 정부(행정안전부)의 재원으로 재난안전기술개발사업단의 지원을 받아 수행된 연구임[MOIS-재난-2015-05].