Faster R-CNN 학습데이터 구축과 모델을 이용한 안전모 탐지 연구
A Study on Data Collection and Object Detection using Faster R-CNN for Application to Construction Site Safety
Article information
Abstract
우리나라의 산업재해 중 건설 분야의 경우 전체의 28.55%의 고위험분야에 해당한다. 이러한 산업재해를 저감하기 위한 활발하게 진행되고 있지만, 건설 안전분야 적용 연구는 아직 미비한 실정이다. 본 연구에서는 건설 안전분야의 안전 보호구 착용 판별에 대한 최신 인공지능 R-CNN 알고리즘을 활용하여 한국형 데이터 학습모델 구축 연구를 수행하였고, 실시간 영상 접목이 가능한 객체 탐지 솔루션을 구현하여 검증하였다. 본 연구수행 결과, 신규 한국형 안전모 착용 여부에 대한 판별 데이터 학습모델은 평균 정밀도(mean Average Precision) 0.82의 우수한 결과로 건설 안전분야의 산업재해 저감을 이룰 것으로 판단된다.
Trans Abstract
Among the industrial accidents occurring in Korea, the construction sector accounts for 28.55% of theaccidents associated with this high-risk sector. Although active progress is being made to reduce such industrial accidents, studies concerning the applications to construction site safety are currently insufficient. In this study, research is conducted on the development of a Korean data learning model using the latest in artificial intelligence algorithms, R-CNN, for the identification of safety protection equipmentworn by workers in the field. As a result of this study, the discriminant data learning model concerning the donning of a new Korean safety hard hat provided excellent results with a mean average precision of 0.82. This advancement is expected to reduce industrial accidents in the field of construction and improve safety.
1. 서 론
우리나라의 산업재해로 인한 경제적 손실은 22조원이다. 이 중 건설업은 전체 산업재해 분포의 약 28.55%에 해당하는 고위험분야이다(MOEL, 2018b). 건설업 부문의 재해 유형은, 2017년 기준으로 떨어짐, 부딪힘 및 물체에 맞음 부문이 각각 14,308명, 6,720명 및 6,677명으로 집계되었으며, 이는 교통사고 재해자 3,792명의 2배 정도의 수준으로, 그 빈도가 매우 잦음이 확인 가능하다(MOEL, 2018b).
국내에서는 이러한 건설현장에서의 산업재해의 감소를 위해 건설기술진흥법(MOLIT, 2019) 및 산업안전보건법(MOEL, 2018a)을 법제화하여 관리하고 있다. 또한, 발주자의 안전조치 이행 및 안전관리비 등 체계적인 법적 절차를 제시, 현장에서의 활용을 유도, 해당 영역에서의 재해를 감소를 위해 다방면으로 노력하고 있다(Joint Ministries, 2018).
하지만, 이러한 법제화 및 현장 안전관리 등의 노력에도 불구하고, 건설노동자의 사고는 매년 꾸준히 발생하고 있다. 이 중 앞서 제시한 떨어짐, 부딪힘 및 물체에 맞음과 같은 유형의 경우, 안전모 착용 등을 통해 해당 사고를 예방하거나 피해를 저감할 수 있다. 이를 위해, 안전모의 지급과 착용에 대한 관리(MOEL, 2019)를 해당 현장의 안전 관리자가 관리, 감독하도록 유도하고 있다. 그러나, 이러한 소수의 안전 관리자가 현장의 노동자 전체를 관리하는 현 시스템은 시․공간의 제약과 인적 자원의 한계가 존재한다. 이러한 한계를 해결하기 위하여 인간의 눈에 해당하는 컴퓨터 비젼(computer vision)과 뇌에 해당하는 인공지능(artificial intelligence) 분야의 적용가능성 검토의 필요성 또한 대두되고 있다.
대표적으로 최근 건설현장내의 카메라를 설치하고 움직임을 예측(Zhu et al., 2016) 하거나, 영상분야와 인공지능을 활용(Shim and Choi, 2019)하는 등 많은 연구가 활발하게 이루어지고 있다. 이 중 영상을 활용한 컴퓨터 비젼의 경우 머신러닝 및 인공지능 분야와의 접목 등을 통해 지속적인 연구가 이루어지고 있다.
인공지능 분야에서는 기하학적인 특징을 기반으로 한 기계학습에서 신경망을 구성하는 인공지능 알고리즘 연구(Vishnu et al., 2017)가 대표적이며, 여러 인공 신경망 구성 기법 중 다층 퍼셉트 학습 알고리즘인 뉴럴네트워크에 전처리 단계로 합성곱신경망(Convolutional Neural Network, CNN)을 접목한 알고리즘의 경우, 건설업 분야뿐만 아니라 여러 분야에서 다양하게 연구되고 있다. 또한, CNN 알고리즘과 Fully-Connected 방식의 연산 효율을 증대하기 위한 ResNet Block기법을 접목한 Region-based Convolutional Neural Network (R-CNN) 기반의 연구(Girshick et al., 2014) 및 여러 관련 연구가 진행 중이다.
본 연구에서는 여러 인공지능 알고리즘 중, R-CNN 계열의 알고리즘 기법을 사용하여 효율적인 의사결정을 지원하기 위한 한국형 안전모 착용 여부 확인 인공지능 학습모델을 구축하였다. 또한 해당 모델의 현장 적용가능성을 검토 하였다.
2. Faster R-CNN
Faster R-CNN의 전체 시스템 네트워크는 객체 탐지를 위한 단일 통합시스템으로 구성되어 있다(Fig. 1). 이 단일 통합시스템은 region을 제안하는 deep fully convolution network와 그 region을 사용하는 fast R-CNN detector의 두 가지 모듈로 구성된다. 또한, deep fully convolution network의 내부에 Region Proposal Network (RPN)를 도입하여 object bounds와 objectness score를 동시에 예측한다. 이러한 이유는 예측의 향상과 GPU 병렬연산의 이점을 최대화시키기 위한 방법이다(Ren et al., 2015).
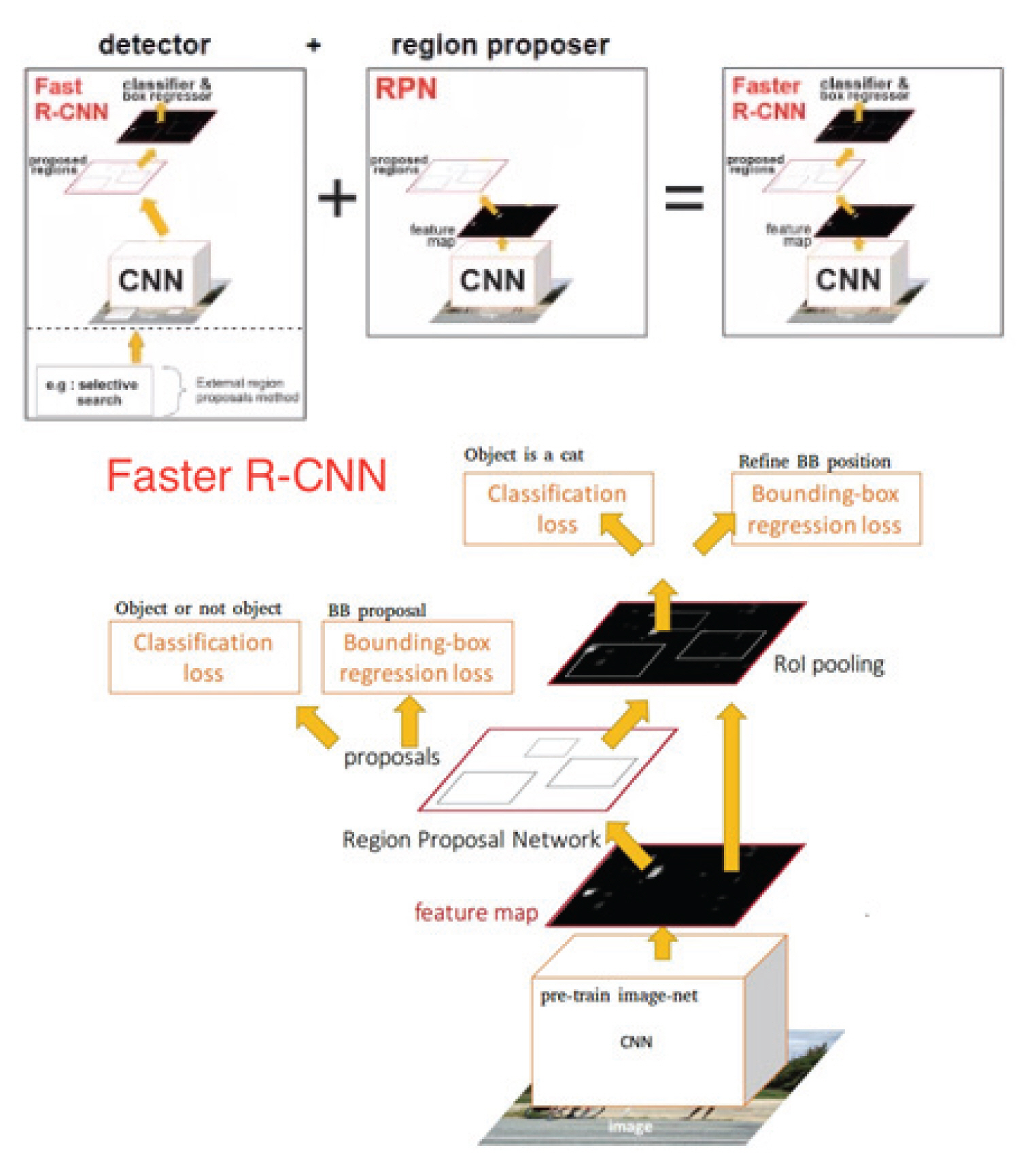
Faster R-CNN
단일 통합 시스템 네트워크 모듈에 대한 faster R-CNN의 두 가지 연산구조의 흐름은 다음 단계와 같다.
1단계: RPN에서 입력한 이미지가 CNN을 통과하여 정보 파라미터가 압축된 final feature map을 연산한다. 2단계: detecting 대상에서 object의 예상 region을 제안하고 동시에 fast R-CNN는 제한된 region에 대한 object를 판단 및 탐지를 한다.
2.1 VGGNet
Visual Geometry Group Net (VGGNet)은 대량의 이미지 분류에서 네트워크의 깊이(depth)와 성능 영향관계를 확인하고자 설계된 네트워크이다(Simonyan and Zisserman, 2015). 네트워크 시작부터 끝까지 동일하게 3 × 3 convolution과 2 × 2 max pooling을 사용하는 구조로 차원의 축소를 통한 깊은 학습이 가능하여 많이 사용되어진다. VGGNet의 일반적인 사용 구조는 컨볼루션이 16개 층으로 구성되어 있는 VGG-16방식이 많이 사용되고 있다(Fig. 2).
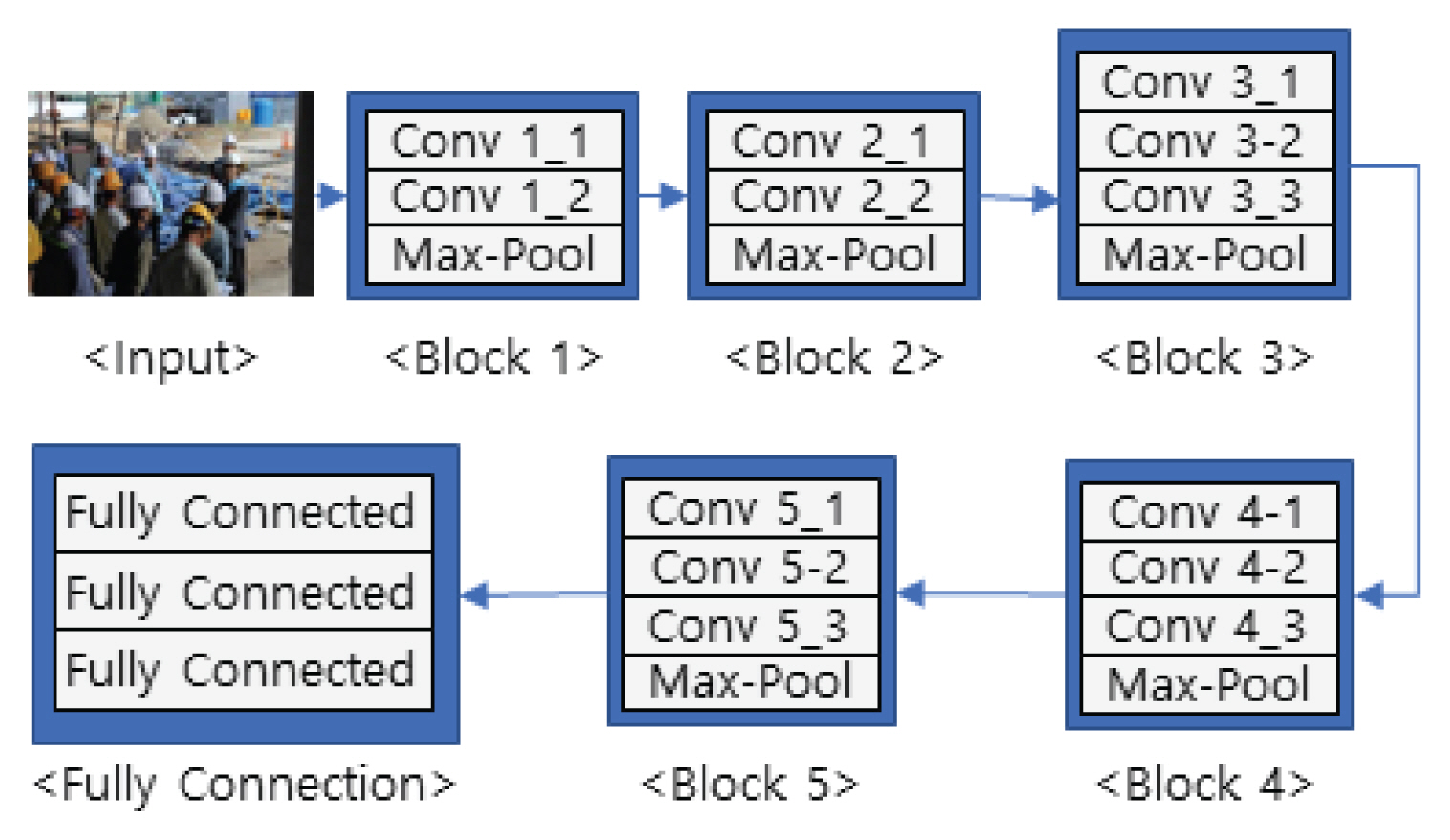
VGG-16 Architecture
2.2 ResNet
네트워크가 매우 깊은 층(layer)으로 구축되면 연산 증가에 따른 성능향상과 정확도 부분에서 성능저하가 일어나는 vanishing gradient 현상이 발생한다. 이러한 컨볼루션 층의 구조적 성능 저하 문제를 해결하기 위하여 residual learning이라는 학습방법을 적용한 네트워크가 Residual Network (ResNet)이다(He et al., 2016).
residual learning은 두 개의 컨볼루션 층과 ReLU 층으로 이루어진 잔여 블록(residual block) 단위로 연산 층을 설계한다(Fig. 3). 기본 블록은 입력에서 바로 출력으로 연결되는 identity shortcut를 두어 불필요한 컨볼루션 연산층을 건너뛴다. 즉, 출력 값과 identity shortcut에 의한 입력 값의 합은 출력 값과 입력 값의 차이 값인 residual은 0이 되는 방향으로 학습이 이루어진다. 따라서 많은 연산이 필요한 깊은 층의 네트워크는 vanishing gradient 현상을 우회하여 성능 저하 문제를 해결할 수 있다.
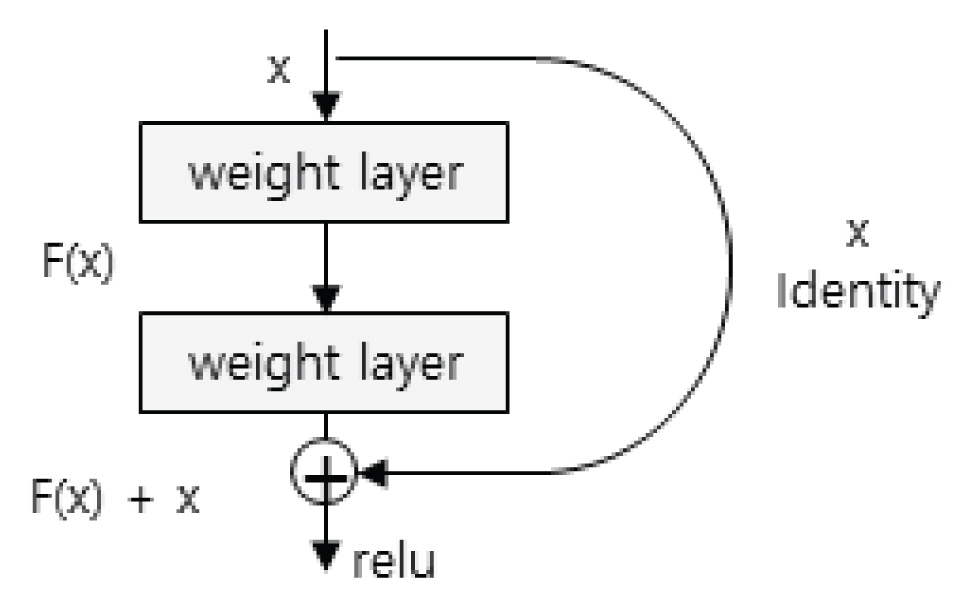
Residual Learning: a Building Block
2.3 Region Proposal Networks
Resion Proposal Networks (RPN)은 입력 이미지 상에서 object가 있을만한 구역을 region으로 제안하는 network이다(Fig. 4).
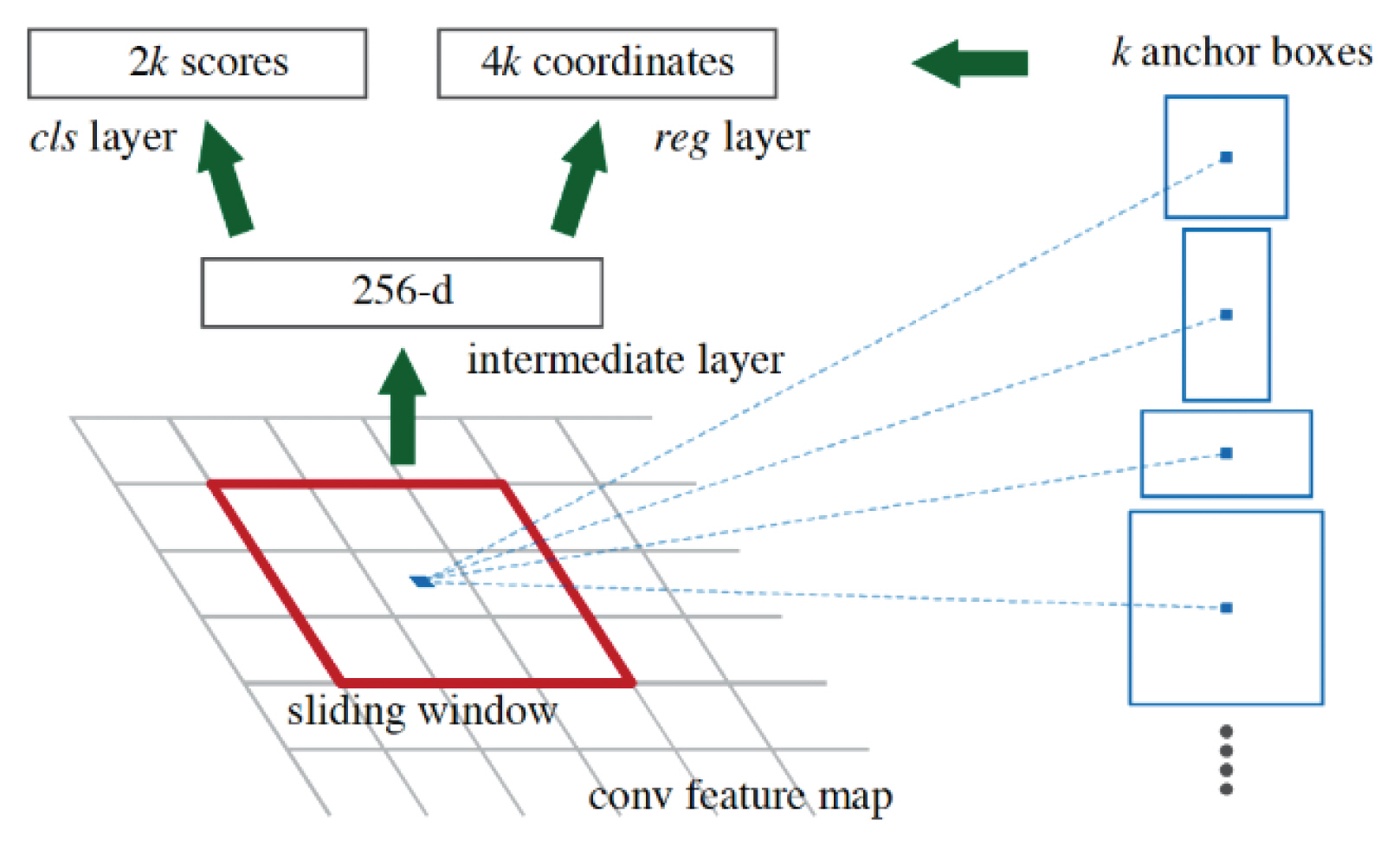
Region Proposal Network (RPN)
RPN training은 anchor라고 하는 candidate region에 대해 region의 크기인 scale과 종횡 비율인 aspect ratio을 계산한다. 이는 scale을 128 × 128, 256 × 256, 512 × 512 3가지로 지정하고, aspect ratio을 1:1, 2:1, 1:2 3가지로 지정했을 때 총 9종류의 다양한 anchor가 정의되는 것이다. 이렇게 정의된 각 anchor에 대해 supervision을 부여하여 각 anchor별로 가장 가까운 ground truth를 찾도록 한다. 이후, ground truth와 일정 비율 이상 겹치면 positive이고 일정 비율 이하 겹치면 negative로 labeling로 판별을 한다. RPN은 CNN에서 생성한 feature map위에서 n × n의 window가 sliding하면서 convolution 연산을 수행하고 해당 중심에 위치한 anchor들에 대해서 object가 있는지 없는지 여부를 판단하고 anchor의 세부 모양을 보정한다.
3. 안전모 AI 모델과 객체 탐지
3.1 실험 환경
본 연구에서 안전모 착용 여부의 객체를 탐지하기 위한 하드웨어, 소프트웨어 및 알고리즘 실험환경은 Table 1과 같다.

Summary of Hardware and Software
3.2 실험 절차
본 연구는 faster R-CNN 알고리즘을 이용한 안전모 탐지를 위해 다음의 4단계 진행절차에 의해 수행되었다(Fig. 5).

Flow of Study
• 1단계: 데이터 수집과 데이터 세트 구축
• 2단계: 인공지능 학습데이터 프로토콜 버퍼
• 3단계: 학습과 training 모델 평가
• 4단계: training 모델의 솔루션 구현
3.3 데이터 수집과 데이터 세트 구축
일반적으로 알고리즘 연구의 학습과 평가를 위한 데이터는 ImageNet (Deng et al., 2009), CIFAR (Krizhevsky, 2009), MS COCO (Lin et al., 2014), PASCAL VOC (Everingham et al., 2010) 등과 같은 각종 챌린지의 데이터 세트를 사용하고 있다. 하지만 이는 모두 외국 자료이고 건설 보호구에 대한 데이터는 없다.
한국 건설현장에서 안전모를 착용하고 작업하는 데이터를 구축하기 위해서는 자체적인 데이터 베이스의 구축이 필요하였으며 이는 웹싸이트(구글, 네이버 등)를 이용하여 스크롤링으로 데이터를 수집하였다. 데이터 세트의 구분은 안전모 착용여부에 대한 객체 탐지를 위해서 안전모 착용과 미착용로 데이터로 구분하여 수집하였다. 동일한 스케일의 이미지 데이터를 구축하기 위하여 사람의 머리를 기준으로 수집한 데이터를 구축하였다.
또한, 건설 노동자의 작업 방향에 따른 변화에 대하여서도 객체학습을 시키기 위하여 전, 후, 좌, 우 4면을 고려한 데이터를 구축하였다(Figs. 6 and 7).

Viewpoin of Hard Hat
Viewpoint of Head
학습을 위해 구축한 데이터 이미지의 개수는 안전모 착용 200개와 미착용 55개를 적용하였고 방향별 안전모에 대한 이미지 개수는 각각 50개로 구성하였다. 안전모 미착용에 대한 방향별 이미지 개수는 총 55개로 구성하였다. 학습모델의 성능을 평가하기 위한 데이터는 안전모 착용과 미착용에 대하여 각각 17개, 15개 이미지를 사용하였다(Table 2).

No. of Image Per Direction
3.4 인공지능 학습데이터 프로토콜 버퍼
구축한 데이터 세트를 가지고 인공지능 학습도구로 컴퓨터를 이용하기 위해서는 직렬화 데이터로 구조화시켜 바이트 스트림화하고 스키마 프로토를 만들어 객체를 인공지능 알고리즘이 읽을 수 있는 것으로 만드는 것이다. 이를 위해 이미지 데이터에서 원하는 객체에 라벨링을 지정하여 각 이미지의 라벨링 데이터가 포함된 xml 파일로 저장시킨다. Fig. 8은 이미지(Chungbuk Daily, 2011; Nocut News, 2017)에서 사람의 머리와 안전모에 대한 라벨링을 지정하는 것과 xml파일의 일부이다(Chungbuk Daily, 2011; Nocut News, 2017). 여기서 라벨링은 클래스를 의미하며 xml 파일은 텐서플로우 학습에 대한 입력 중 하나인 TFRecord로써 직렬화 바이트 스트림 형태로 텐서플로우는 딥러닝 학습을 하는데 필요한 데이터들을 보관하기 위해 바이너리 데이터로 읽고 쓰기를 한다.
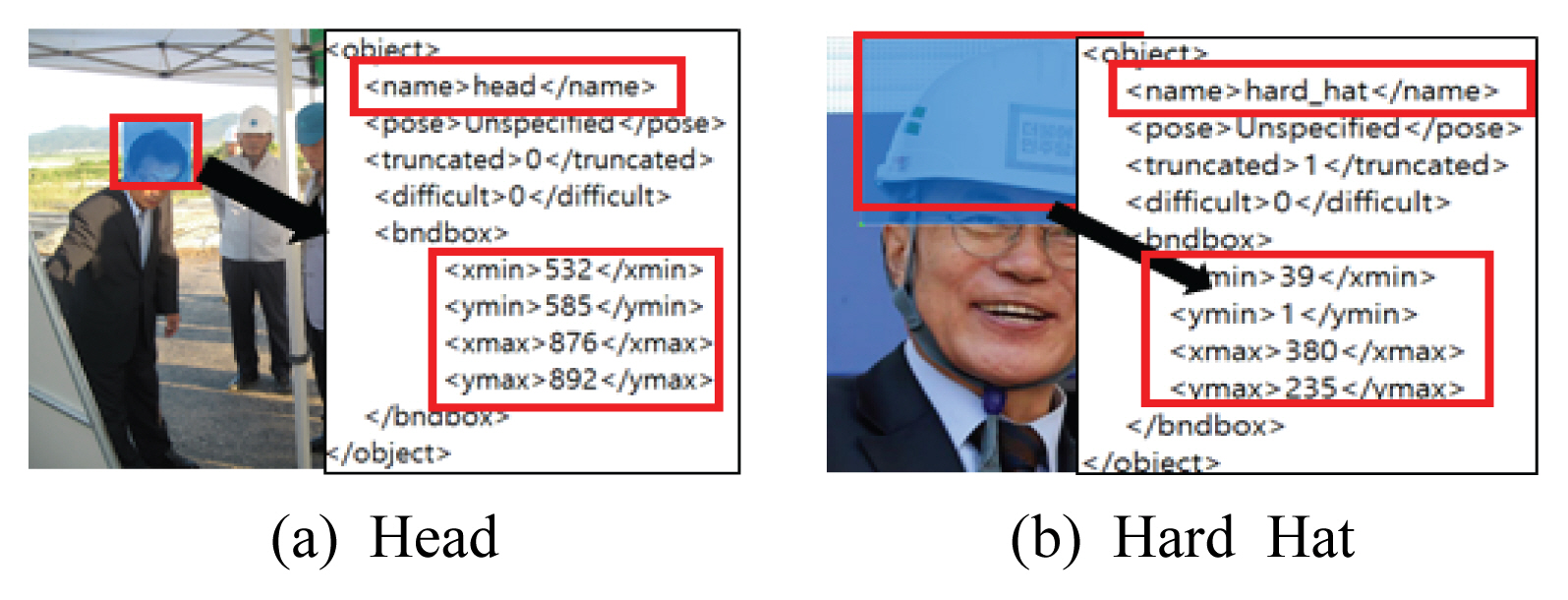
Example of Labelling
3.5 학습과 training 모델 평가
학습모델은 faster R-CNN 알고리즘의 CNN 구조층의 경우 ResNet50으로 학습을 구현하였다. 반복회수(epoch)는 임의로 결정하여(예를 들면 1,000번 또는 10,000번) 학습을 수행하고 완료된 후에는 학습 모델의 성능을 평가한다.
학습 평가에 대한 성능평가지표는 비젼분야 객체탐지에서 사용되어지는 평균 정밀도(mean Average Precision, mAP)를 적용하였다. 평균 정밀도는 PASCAL VOC에서 평가 기준으로 사용된 성능평가지표로서, 각 분류 클래스별 Average Precision (AP)의 평균으로 객체 탐지 알고리즘의 성능을 한 가지 지표로 나타낼 수 있다(Everingham et al., 2010).


4. 객체 탐지 분석
객체 탐지는 학습을 통한 training 모델 평가와 training 모델 구현으로 나누어 분석을 수행하였다. 이때 training 학습 모델의 평가 결과인 총손실(total loss)과 training 모델의 평가 결과인 평균 정밀도는 tensorboard의 값을 이용하였다.
4.1 training 모델 평가 결과
4.1.1 training 학습 모델 평가 결과
학습은 학습 데이터 세트를 이용하여 총손실로 평가되며 반복회수에 따른 총손실은 Table 4에 정리하였다.

Total Loss in the Training Step
학습모델의 총손실은 반복회수에 따라 일정한 값을 갖지않고 변화되는 것을 볼 수 있다. 이때 총손실은 최소 2 (이상적으로 1 이하)에 도달하도록 하는 것이 좋으며(Vladimirov, 2019) 본 논문에서는 학습회수에 관계없이 0.1보다 작게 분석되었으므로 적절하게 학습된 것으로 판단된다(Fig. 10).

Total Loss in the Training Step
4.1.2 training 모델 평가 결과
학습이 완료된 모델에 대하여 평가 데이터 세트로 성능을 평가한 결과는 반복회수에 따라 성능평가기준인 평균 정밀도의 값은 Fig. 11에서 볼 수 있듯이 일정한 값이 갖지 않고 변화되는 값을 갖는다(Table 5).

mAP in the Evaluating Step

mAP in the Evaluating Step
성능평가기준인 평균 정밀도는 반복회수를 1,000에서 20,000까지 수행하였을 때, 15,000번에서 가장 높은 값으로 평가되었다(Table 5, Fig. 11). 이때 안전모와 사람 머리에 대하여 각각 0.81, 0.82의 평균 정밀도를 보여주고 있다. 또한 두 개의 클래스 평균은 0.82로 평가되었다. 이것은 faster R-CNN에 대한 기존 연구(Ren et al., 2015)에서 분석된 평균 정밀도(0.67~0.79)와 유사한 값으로 학습은 정상적으로 진행되었음을 알 수 있다.
반복회수가 15,000일 때, 안전모와 사람의 머리에 대한 탐지 결과는 Figs. 12와 13에 나타내었다.

Successful Detections with Evaluating Dataset

Unsuccessful Detections Evaluating Dataset
안전모와 사람의 머리를 정확하게 탐지하는 경우, 주변 명암과 뚜렷해하거나 사람들이 서로 겹쳐 있어도 잘 탐지하는 것을 확인할 수 있다(Fig. 12). 하지만 머리를 숙이고 있는 특이한 자세는 객체를 탐지하지 못하는 것을 볼 수 있다(Fig. 13). 이는 학습모델의 특성상 학습 데이터 양에 따라 탐지 능력이 좌우되며 해당 사례의 경우, 노동자의 특이한 자세에 대한 학습 데이터 양이 부족하여 탐지 능력이 떨어진 것으로 판단된다.
4.2 training 모델의 솔루션 구현 결과
학습 완료된 모델을 사용하여 앞서 언급한 솔루션 형태로 구현하였다. 솔루션을 검증하기 위해 학습과 평가에서 사용되지 않은 새로운 데이터 세트가 필요하다. 이를 위해 사용된 이미지수는 총 30장이다.
솔루션을 검증한 결과, 총 30장의 이미지 중에서 28장에 대하여 안전모와 사람의 머리를 탐지할 수 있었다(Fig. 14(a), (b), (c)). 또한 2장의 이미지는 안전모와 사람의 머리를 탐지하지 못하였다(Fig. 14(d)). 학습모델 솔루션은 93%의 탐지 능력이 있는 것으로 분석되었다(Table 6).

Detecting Results of Construction Site

Result of Detection at Construction Site
앞서 언급한 바와 같이 본 연구에서 제시된 솔루션은 Fig. 14(d) 사례를 제외한 모든 경우(Fig. 14(a), (b), (c))에서 정상적으로 작동되는 것을 확인할 수 있었다. 하지만 Fig. 14(d)는 원거리에서 촬영된 경우와 이미지 사이즈에 따른 객체가 너무 작은 경우로서 객체를 탐지하지 못하였다. 이는 CNN 구조체의 알고리즘 내에서 입력된 이미지는 CNN 구조체의 pooling 단계를 반복 수행됨에 따라 차원 축소가 이루어기 때문에 픽셀이 적은 객체는 그 특징을 추출할 수 없기 때문이다. 따라서 원거리 학습 데이터를 추가로 확보하여 학습을 통해 개선시킬 수 있을 것으로 판단된다.
5. 결 론
본 연구는 건설현장 안전관리시 안전 관리자 일임 관리 체계로 인한 시간과 공간의 제약과 같은 단점을 보완하기 위하여, 건설현장 안전 관리에 이용 가능한 이미지 기반 객체 탐지 및 인공지능분야 적용 가능성에 대한 기초적인 연구를 수행하였다.
본 연구에서는, 이미지 기반 객체 탐지에 이용되는 faster R-CNN 기법을 기반으로, 건설 노동자의 안전모 착용 여부를 학습한 모델을 이용하고, 솔루션을 작성, 예시를 통해 적용성을 확인하였다.
해당 학습 모델에 사용된 데이터 세트는 국내 현장 상황 반영을 위하여, 외국 데이터가 아닌 한국 데이터만으로 신규 구축하였다. 신규 구축된 데이터 세트를 활용하여 분석한 결과, 성능평가지표인 평균 정밀도는 0.82로 평가되었다. 또한, 해당 모델을 타 현장 이미지로 평가하였을 때에도 안전모 착용과 사람의 머리에 대한 감지 성능이 93%로 확인되었다. 따라서 실제 현장에 적용할 수 있을 정도로 충분함을 확인할 수 있었다.
다만, 해당 모델의 경우, 원거리 이미지와 건설 노동자의 자세에 따라 감지 성능이 저하되므로 향후 추가적인 원거리 연구가 수행되어야 할 것으로 판단된다. 하지만 향후 이러한 안전모 착용 여부 탐지를 위한 인공지능 기술은 안전관리자의 의사결정지원과 건설인의 산업재해 저감 효과가 클 것으로 판단된다.
Acknowledgements
본 연구는 ㈜고려스마트기술정책연구소의 안전모 착용 여부에 따른 객체감지 상용화 기술 개발을 위한 연구비 지원에 의해 수행되었습니다.