



1. мДЬ л°†
к±імґХлђЉмЭШ кµђм°∞к∞А л≥µмЮ°нЩФ, лМАнШХнЩФлРШл©імДЬ кЄ∞м°і нЩФмЮђ к∞РмІАкЄ∞мЭШ м†БмЪ© л≤ФмЬДмЩА мД±лК•мЧР нХЬк≥Дл•Љ л≥імЭік≥† мЮИмЬЉл©∞ л≥ілЛ§ мЛ†мЖНнХШк≥† м†ХнЩХнХШк≤М нЩФмЮђл•Љ к∞РмІАнХШлКФ мГИл°ЬмЪі кЄ∞мИ†мЭШ к∞Ьл∞ЬмЭі мЪФкµђлРШк≥† мЮИлКФ мЛ§м†ХмЭілЛ§. мЭімЧР лФ∞лЭЉ мЧівЛЕмЧ∞кЄ∞вЛЕк∞АмК§ лУ± лђЉл¶ђм†Б мДЉмЛ± кЄ∞мИ† кЄ∞л∞ШмЭШ кЄ∞м°і к∞РмІА кЄ∞мИ†мЭД к≥†лПДнЩФнХШлКФ лŪ놕к≥Љ лНФлґИмЦі л≥імХИ лґДмХЉ лУ±мЧРмДЬ лДРл¶ђ мВђмЪ©лРШк≥† мЮИлКФ CCTV мШБмГБ мДЉмЛ± кЄ∞мИ†мЭД нЩЬмЪ©нХЬ нЩФмЮђ к∞РмІА кЄ∞мИ†лПД к∞БкіСл∞ЫкЄ∞ мЛЬмЮСнЦИлЛ§.
л≥Є мЧ∞кµђмЭШ лМАмГБмЭЄ мІАлК•нШХ CCTVлКФ нШДмЮ•мЧРмДЬ мЛ§мЛЬк∞ДмЬЉл°Ь міђмШБлРЬ мШБмГБ мЭілѓЄмІАл•Љ мІАлК•нШХ лґДмДЭ л™®лУИк≥Љ к≤∞нХ©нХШмЧђ нЩФмЮђмЭШ л∞ЬмГЭк≥Љ мЦСмГБмЭД к≤АмґЬнХШлКФ кЄ∞мИ†мЭілЛ§. мЭі л∞©мЛЭмЭА м£Љл°Ь лФ•лЯђлЛЭ(Deep Learning)мЭШ мШБмГБ лґДмДЭ кЄ∞л≤ХмЭЄ CNN (Convolutional Neural Network) л™®лНЄмЧР кЄ∞л∞ШмЭД лСРк≥† к∞Ьл∞ЬлРШк≥† мЮИлЛ§. нШДмЮђкєМмІА мІДнЦЙлРЬ CCTV нЩФмЮђ к∞РмІА кЄ∞мИ†мЭА м£Љл°Ь лЛ®мЭЉ мєіл©ФлЭЉмЭШ мЭілѓЄмІАл•Љ лґДмДЭнХШк≥† к≤АмґЬнХШлКФ л∞©мЛЭ(Fig. 1)мЭД м±ДнГЭнХШк≥† мЮИмЦімДЬ мєіл©ФлЭЉ м£Љл≥АмЭШ мҐЕнХ©м†БмЭЄ нЩШк≤љ м†Хл≥і мИШмІСмЭі мֳ놵лЛ§. мШИл•Љ лУ§мЦі к∞Б CCTVл≥Дл°Ь к≤АмґЬлРЬ к∞Эм≤ік∞А м§См≤©лРШмЦі мЭЄмЛЭлРШлКФ лУ±мЭШ лђЄм†Ьк∞А л∞ЬмГЭнХ† мИШ мЮИмЬЉл©∞ мЭіл°Ь мЭЄнХШмЧђ к∞ЩмЭА мЮ•мЖМмЧРмДЬ л∞ЬмГЭлРЬ лПЩмЭЉ нЩФмЮђмЮДмЧРлПД лґИкµђнХШк≥† мДЬл°Ь лЛ§л•Є л≥µмИШмЭШ нЩФмЮђл°Ь мШ§мЭЄнХШлКФ лУ±мЭШ лђЄм†Ьм†РмЭі мЮИлЛ§.
л≥Є лЕЉлђЄмЧРмДЬлКФ мЭілЯђнХЬ мєіл©ФлЭЉмЭШ м§См≤©мЭД нХік≤∞нХШк≥† мЭіл•Љ м†БкЈєм†БмЬЉл°Ь нЩЬмЪ©нХШмЧђ нЩФмЮђ л∞ЬмГЭ мЬДмєШл•Љ мЛ†мЖНнХШк≤М кµђм≤інЩФнХШк≥†мЮР нЩФмЮђ л∞ЬмГЭлњР мХДлЛИлЭЉ л≥µмИШмЭШ мєіл©ФлЭЉл•Љ мГБнШЄ мЧ∞лПЩнХШмЧђ л∞ЬмГЭ мЬДмєШл•Љ мґФм†ХнХШлКФ л∞©л≤ХмЭД м†ЬмХИнХШк≥†мЮР нХЬлЛ§. мЭі л∞©мЛЭмЭА лЛ®лПЕ мєіл©ФлЭЉлІМмЭШ мЭілѓЄмІА лґДмДЭ л∞©мЛЭл≥ілЛ§ м†ХнЩХнХШк≤М нЩФмЮђмЭШ м†ХлПДмЩА мГБнЩ© м†Хл≥іл•Љ нХ®кїШ мЦїмЭД мИШ мЮИлЛ§. кЄ∞м°і мІАлК•нШХ CCTV мЭілѓЄмІАмЧРмДЬлКФ м§См≤© лґАлґДмЭШ нЩФмЮђ л∞ЬмГЭмЭЄ к≤љмЪ∞мЧР кіАм∞∞мЮРк∞А CCTV мЭілѓЄмІАл•Љ лєДкµРнХШмЧђ м§См≤© лґАлґДмЮДмЭД мЬ°мХИмЬЉл°Ь нМРлЛ®нХШлКФ л∞©мЛЭмЭЄлН∞ л≥Є лЕЉлђЄмЭА мЭіл•Љ мЮРлПЩнЩФнХШлКФ л∞©л≤ХмЭД м†БмЪ©нХШмШАлЛ§.
м†ЬмХИнХШлКФ л∞©мЛЭмЭА к∞РмЛЬ к≥µк∞ДмЭД нСЬнШДнХШлКФ кЄ∞міИ мІАлПДл•Љ мЮСмД±нХШлКФ лЛ®к≥ДмЩА нЩФмЮђ к≤АмґЬмЧР лФ∞лЭЉ мЬДмєШл•Љ нСЬмЛЬнХШмЧђ мІАлПДл•Љ мЩДмД±нХШлКФ лСР к∞АмІА лЛ®к≥Дл°Ь мЭіл£®мЦімІДлЛ§. кЄ∞міИ мІАлПД мЮСмД±мЭА мєіл©ФлЭЉ мД§мєШмЛЬ 1нЪМмЧР к±Єм≥Р к≤©мЮРнШХ кµђмЧ≠мЭД лВШлИДк≥† міИкЄ∞ мІАлПДл•Љ мЮСмД±нХШлКФ к≥Љм†ХмЭД лІРнХЬлЛ§. кЄ∞міИ мІАлПД мЮСмД±к≥Љ нЩФмЮђ к≤АмґЬ к≥Љм†ХмЭД мЬДнХЬ к≤АмґЬ мЧФмІДмЬЉл°ЬлКФ мµЬкЈЉ мД±лК•к≥Љ мХИм†ХмД±мЭД мЭЄм†Хл∞Ык≥† мЮИлКФ CNN кЄ∞л∞ШмЭШ лґДмДЭ л™®лНЄмЭЄ YOLOv5 л•Љ м†БмЪ©нХШмШАлЛ§. нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶ШмЧРмДЬлКФ мєіл©ФлЭЉл≥Дл°Ь мЮСмД±лРЬ к≥µк∞ДмІАлПДл•Љ кµРм∞®нХШлКФ л∞©мЛЭмЬЉл°Ь к≥µнЖµмЭШ мШБмЧ≠ мЭЄлН±мК§л•Љ мґФмґЬнХШлКФ л∞©мЛЭмЭілЛ§. нХШмІАлІМ лФ•лЯђлЛЭ кЄ∞л∞Ш к≤АмґЬ л∞©мЛЭмЭА нХЩмКµ мГШнФМмЭШ мЦСк≥Љ м†Им∞®мЧР лФ∞лЭЉ мД±лК•мЭі нБђк≤М лЛђлЭЉмІИ мИШ мЮИлЛ§. мЭімЧР л≥Є лЕЉлђЄмЧРмДЬлКФ лФ•лЯђлЛЭ мЧФмІДмЬЉл°Ь нЩФмЮђ, мЧ∞кЄ∞, мВђлЮМ лУ± лђЉм≤і к≤АмґЬмЬ®мЭД лЖТмЭікЄ∞ мЬДнХЬ лЛ§мЦСнХЬ мГШнФМ мИШмІС л∞©л≤Х, нХЩмКµ мІДнЦЙ мИЬмДЬ лУ± лЛ§мЦСнХЬ мЛ§нЧШмЭД мІДнЦЙнХШмШАк≥† мЭімЧР лФ∞л•Є мД±лК• л≥АнЩФл•Љ 4мЮ•мЧРмДЬ мД§л™ЕнХШмШАлЛ§.
2. мД†нЦЙ мЧ∞кµђ к≥†м∞∞
CCTVмЩА к∞ЩмЭА мєіл©ФлЭЉл°Ь міђмШБлРЬ мЭілѓЄмІАл•Љ лґДмДЭнХШмЧђ лђЉм≤іл•Љ мЭЄмЛЭнХШк≥† м∞ЊмХДлВілКФ мЭЉмЭА мїінУ®нД∞ лєДм†Д(Computer Vision) лґДмХЉмЭШ мЮСмЧЕмЬЉл°Ь мЮРмЬ® м£ЉнЦЙ мЮРлПЩм∞®, л°ЬліЗ лУ± мЮРлПЩнЩФ кЄ∞к≥ДмЭШ м£ЉмЪФ мДЉмЛ± кЄ∞мИ†л°Ь мЮРл¶ђмЮ°к≥† мЮИлЛ§. мЭілЯђнХЬ мїінУ®нД∞ лєДм†ДкЄ∞мИ†мЭА лЛ§мЦСнХЬ л≤Фм£ЉмЩА лМАмГБмЬЉл°Ь нЩХлМАлРШмЦі нЩФмЮђ к≤АмґЬ кЄ∞лК•мЭД к∞ЦлКФ мІАлК•нШХ CCTVл°Ь мІДнЩФнХШк≥† мЮИлЛ§.
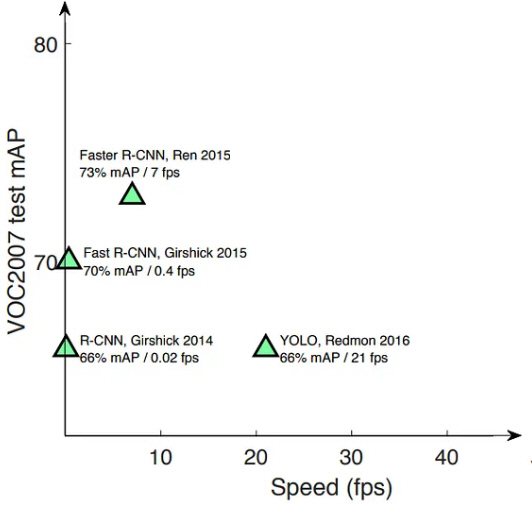
нЩФмЮђ к≤АмґЬк≥Љ к∞ЩмЭі мЭілѓЄмІА лВімЭШ к∞Эм≤іл•Љ мЭЄмЛЭ(Object Detecton)нХШлКФ мЮСмЧЕмЭА нХілЛє лМАмГБмЭі лђімЧЗмЭЄмІАл•Љ мЛЭл≥ДнХШлКФ к∞Эм≤і лґДл•Ш лЛ®к≥Д(Classification)мЩА мЭілѓЄмІА лВі мЦілКР мІАм†РмЧРмДЬ л∞Ьк≤ђ лРШлКФ к∞Ал•Љ к≤∞м†ХнХШлКФ мЬДмєШ мД†м†Х лЛ®к≥Д(Localization) лУ± лСР к∞АмІА мДЄлґА мЮСмЧЕмЬЉл°Ь мЭіл£®мЦімІДлЛ§(Zhong-Qiu et al., 2019). мЭЉл∞Шм†БмЬЉл°Ь к∞Эм≤і мЭЄмЛЭмЭД мЬДнХімДЬ м£Љл°Ь мВђмЪ©лРШлКФ нФДл°ЬкЈЄлЮ®мЭА мЭілѓЄмІА лФ•лЯђлЛЭ лґДмДЭмЬЉл°Ь нКєнЩФлРЬ CNN (Convolution Neural Network) нШХмЛЭмЬЉл°Ь лМАнСЬм†БмЭЄ к≤ГмЬЉл°Ь R-CNN (Region-CNN), Fast R-CNN, YOLO (You Only Look Once) лУ±мЭі мЮИлЛ§(Sojasingarayar, 2022). R-CNNмЭА Fig. 2мЩА к∞ЩмЭі мЭілѓЄмІАл°ЬлґАнД∞ лЛ§мЦСнХЬ л∞©мЛЭмЬЉл°Ь мШБмЧ≠ лґДнПђл•Љ лІМлУ§к≥† к∞Ьк∞Ь мШБмЧ≠л≥Дл°Ь нКємІХмЭД кµђнХЬ лТ§ CNN кµђм°∞м≤іл°Ь м≤Шл¶ђнХШлКФ к≥Љм†ХмЬЉл°Ь мД§л™ЕнХ† мИШ мЮИлЛ§. лЛ§мЛЬ лІРнХімДЬ CNNк≥Љ мШБмЧ≠ м†ЬмХИ(Region proposals)мЭД к≤∞нХ©нЦИлЛ§к≥† нХ† мИШ мЮИлЛ§. R-CNNмЭА 2014лЕД Girshick лУ±мЧР мЭШнХімДЬ мЧ∞кµђлРШмЧИлЛ§(Girshick et al., 2014).

R-CNN л∞©мЛЭмЭА мЬДмЧРмДЬ мЦЄкЄЙнХЬ к∞Эм≤і лґДл•Ш лЛ®к≥ДмЩА мЬДмєШ мД†м†Х лЛ®к≥Дл•Љ кµђлґДнХШмЧђ 2лЛ®к≥Дл°Ь лВШлИДмЦі мИЬм∞®м†БмЬЉл°Ь мІДнЦЙнХШлКФ лН∞ мЭік≤ГмЭД 1лЛ®к≥Дл°Ь нЖµнХ©нХШмЧђ мИШнЦЙнХШлПДл°Э нХЬ к≤ГмЭі YOLO л∞©мЛЭмЭілЛ§. мЭЉл∞Шм†БмЬЉл°Ь R-CNN л∞©мЛЭмЭА к≤АмґЬ м†ХнЩХлПДк∞А лЖТмЭА л∞Шл©імЧР м≤Шл¶ђ мЖНлПДк∞А лКР놧мДЬ мЭіл•Љ к∞ЬмД†нХЬ к≤ГмЭі Fast R-CNN мЭімІАлІМ YOLO л™®лНЄмЧР лєДнХШл©і мЧђм†ДнЮИ мГБлМАм†БмЬЉл°Ь лКРл¶ђлЛ§. Fig. 3мЭА мЭілЯђнХЬ мШБмЧ≠ мД§м†ХмЭШ м∞®мЭіл•Љ лєДкµР мД§л™ЕнХЬ к≤ГмЭілЛ§(Saydirasulovich et al., 2023).
R-CNNмЭА лІОмЭА мИШмЭШ нЫДл≥і мШБмЧ≠мЭД мД†м†ХнХШк≥† мШБмЧ≠л≥Дл°Ь CNNмЭД м†БмЪ©нХШмЧђ нКємІХ л≤°нД∞(Feature Vector)л•Љ мГЭмВ∞нХШлКФ л∞©мЛЭмЭікЄ∞ лХМлђЄмЧР мЛ§мЛЬк∞Д к≤АмґЬ мЪ©лПДл°Ь нЩЬмЪ©нХШкЄ∞ мֳ놵лЛ§. мЛ§мГЭнЩЬмЧР м†БмЪ©нХШкЄ∞ мЬДнХімДЬлКФ мґ©лґДнЮИ лє†л•Є мЖНлПДмЩА мЛ§мЪ©м†БмЭЄ м†ХнЩХлПДл•Љ к∞ЦмґШ л≥ілЛ§ к∞ЬмД†лРЬ л™®лНЄмЭі нХДмЪФнХШл©∞ лМАнСЬм†БмЬЉл°Ь YOLO л™®лНЄмЭД мШИл°Ь нХ† мИШ мЮИлЛ§. YOLOлКФ мЭілѓЄмІАл•Љ 1нЪМ мК§мЇФнХШлКФ л∞©мЛЭмЬЉл°Ь лМАмГБмЭШ мЬДмєШл•Љ к≥ДмВ∞нХШлКФ л∞©мЛЭмЭікЄ∞ лХМлђЄмЧР R-CNNмЬЉл°Ь м†БмЪ©нХШкЄ∞ мֳ놧мЪі мЛ§мЛЬк∞Д м≤Шл¶ђк∞А к∞АлК•нХШлЛ§(Sumit et al., 2020).
мєіл©ФлЭЉ мЭілѓЄмІАл•Љ лґДмДЭнХШмЧђ нЩФмЮђ к≤АмґЬмЭД мЬДнХЬ лЛ§мЦСнХЬ лФ•лЯђлЛЭ лґДмДЭ л∞©л≤ХмЭі м†БмЪ©лРШк≥† мЮИлЛ§(Roh et al., 2022; Lee et al., 2017). Zheng et al. (2023)мЭШ мЧ∞кµђмЧРмДЬлКФ нЩФмЮђ, мЧ∞кЄ∞ к≤АмґЬмЭД мЬДнХЬ лФ•лЯђлЛЭ лґДмДЭ мЛЬмК§нЕЬмЭД кµђмД±нХШк≥† лЛ§мЦСнХЬ л∞©мЛЭмЬЉл°Ь мЛ§нЧШнХШмШАлЛ§. лєДкµР лМАмГБмЬЉл°Ь мВЉмЭА лФ•лЯђлЛЭ л™®лНЄл°ЬлКФ Fater-RCNN, SSD (Single Shot MultiBox Detector), YOLOv3, YOLOv4-tiny, YOLOv4л•Љ мВђмЪ©нХШмЧђ мД±лК• нЕМмК§нКЄл•Љ нХШк≥† мЮРмЛ†лУ§мЭі м†ЬмХИнХШлКФ к∞ЬмД† л™®лНЄ(MobileNetV3-large-YOLOv4)к≥Љ лєДкµРнХШлКФ мЧ∞кµђл•Љ мІДнЦЙнХШмШАлЛ§(Zheng et al., 2023). Saydirasulovich мЭШ мЧ∞кµђлКФ YOLOv6л•Љ мЭімЪ©нХШмЧђ 4,000мЮ• мЭілѓЄмІАл•Љ нХЩмКµ, нЕМмК§нМЕ, мД±лК• нПЙк∞АмЧР мВђмЪ©нХШмШАлЛ§(Saydirasulovich et al., 2023).
3. нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶ШмЭД мЬДнХЬ кЄ∞міИ мІАлПД мЮСмД±
YOLO л™®лНЄмЭД нЩЬмЪ©нХШмЧђ Fig. 4мЧР лВШнГАлВЄ л∞ФмЩА к∞ЩмЭі к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) лВімЧР мД§мєШлРЬ л≥µмИШмЭШ CCTV мЭілѓЄмІАл•Љ лґДмДЭнХШмЧђ нЩФмЮђ л∞ЬмГЭ мЧђлґАмЩА л∞ЬмГЭ мЬДмєШл•Љ лВШнГАлВілКФ мГБнЩ© мІАлПДл•Љ мЮСмД±нХШкЄ∞ мЬДнХімДЬлКФ лСР к∞АмІА лЛ®к≥Дк∞А нХДмЪФнХШлЛ§. м≤Ђ л≤ИмІЄ лЛ®к≥ДлКФ м§АлєД лЛ®к≥Дл°ЬмДЬ к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)мЭД к≤©мЮРл°Ь лВШлИДк≥† мШБмЧ≠л≥Дл°Ь мЭЄлН±мК§л•Љ лґАмЧђнХШлКФ лЛ®к≥ДмЭілЛ§. кЈЄл¶ђк≥† лСР л≤ИмІЄ лЛ®к≥ДлКФ CCTVк∞А мЛ†мЖНнХШк≤М нЩФмЮђмЭШ мЬДмєШл•Љ нМРл≥ДнХШкЄ∞ мЬДнХімДЬ к≤©мЮРл°Ь лВШлИИ мШБмЧ≠к≥Љ мєіл©ФлЭЉл≥Д мЭілѓЄмІАл•Љ мГБнШЄ лєДкµРнХШмЧђ мЬДмєШл•Љ мД†м†ХнХШлКФ лЛ®к≥Дл°Ь кµђлґДлРЬлЛ§. лФ∞лЭЉмДЬ л≥Є мЧ∞кµђмЧРмДЬлКФ л≥µмИШмЭШ CCTV мЭілѓЄмІА лВімЧРмДЬ мЭЄлН±мК§л•Љ кµђлґДнХШмЧђ мШБмЧ≠мЭД лВШлИДк≥†, мГБнШЄ м§См≤©лРШлКФ мЭілѓЄмІАк∞А мЮИлЛ§к≥† к∞Ам†ХнХШмШАлЛ§.
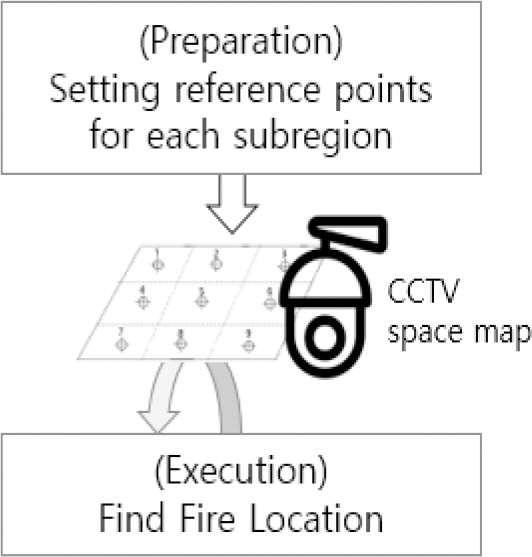
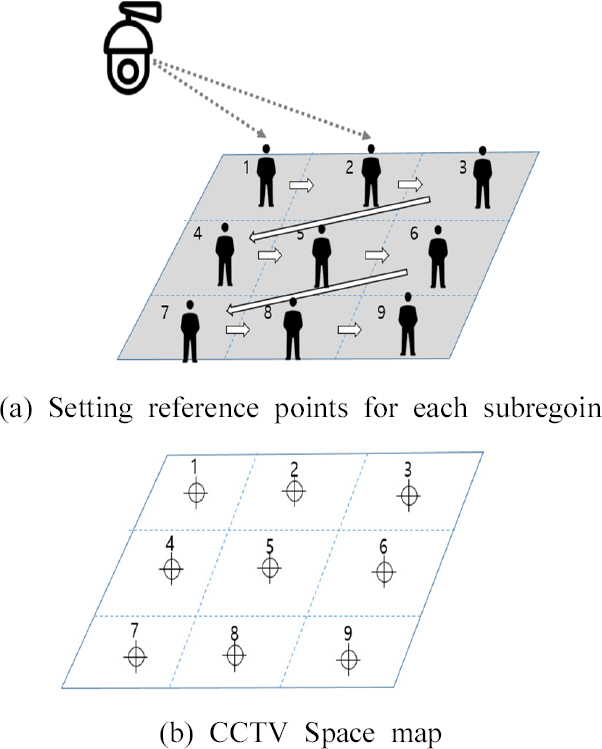
3.1 кЄ∞міИ мІАлПД мЮСмД±
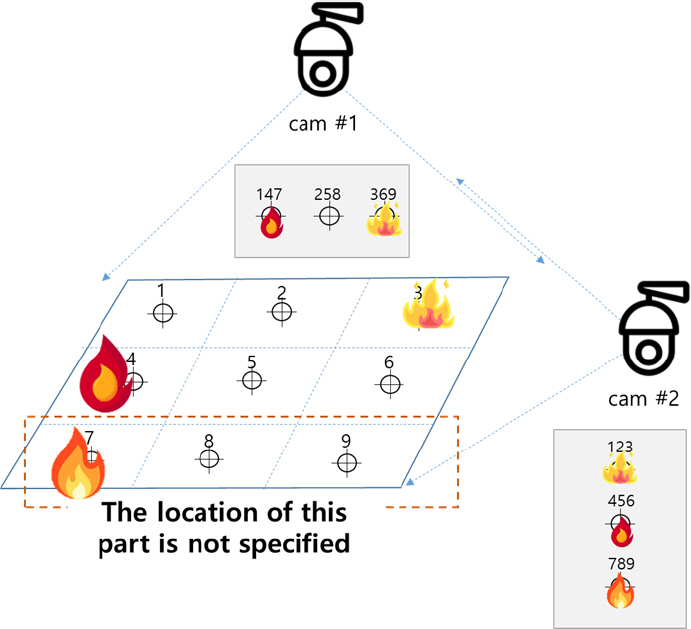
к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) мІАлПДлКФ мєіл©ФлЭЉ мД§мєШ мЛЬ мЭЄмЛЭлРШлКФ к≥µк∞ДмЭД нЖµнХі мЮСмД±нХШл©∞, мєіл©ФлЭЉ мЬДмєШк∞А л≥Ак≤љлРШмІА мХКлКФ нХЬ л∞Шл≥µм†БмЬЉл°Ь мВђмЪ©нХ† мИШ мЮИлЛ§. кЄ∞міИ мІАлПД мЮСмД±мЭД мЬДнХімДЬ Fig. 5мЧР лВШнГАлВЄ л∞ФмЩА к∞ЩмЭі к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)мЭД мЖМ мШБмЧ≠мЬЉл°Ь лВШлИДк≥†, к∞Б мШБмЧ≠л≥Дл°Ь CCTVк∞А мЭілПЩнШХ к∞Эм≤і(мВђлЮМ)л•Љ нЖµнХі кЄ∞м§Ам†Р мД§м†ХнХШк≥† мґФм†БнХШмЧђ л™®лУ† мЖМ мШБмЧ≠л≥Дл°Ь мЬДмєШл•Љ мЭЄмЛЭнХШлПДл°Э нХШмШАлЛ§. мЭім≤ШлЯЉ Fig. 5(a)лКФ м†Дм≤і к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)мЭД 3 √Ч 3 к≤©мЮР нШХмЛЭмЬЉл°Ь мЛ§м†Ь к≥µк∞ДмЭД 9к∞ЬмЭШ мЖМмШБмЧ≠мЬЉл°Ь кµђлґДнХШмШАк≥†, мЭілПЩнШХ к∞Эм≤і(мВђлЮМ)к∞А мЖМ мШБмЧ≠мЧР мЬДмєШнХЬ мИЬмДЬлМАл°Ь мЭЄлН±мК§л•Љ лґАмЧђнХШмЧђ CCTV space map (Fig. 5(b))мЭД кµђмД±нХШмШАлЛ§. Fig. 6мЭА мЛ§м†Ь мЛ§нЧШмЭД нЖµнХі кЄ∞міИ к≥µк∞Д мІАлПД мЮСмД±мЭД мІДнЦЙнХЬ к≤ГмЬЉл°Ь мЭілПЩнШХ к∞Эм≤і(мВђлЮМ)л•Љ мЭЄмЛЭнХЬ нЫД мЫРнХШлКФ мЖМмШБмЧ≠мЧР мЬДмєШнЦИмЭД лХМ мЭЄлН±мК§л•Љ лґАмЧђнХШлКФ л∞©мЛЭмЬЉл°Ь, 3лМАмЭШ CCTVл•Љ мЭімЪ©нХі к∞БкЄ∞ лЛ§л•Є к∞БлПДмЩА к±∞л¶ђмЧРмДЬ к∞Эм≤іл•Љ к≤АмґЬнХШмШАмЬЉл©∞, мЛ§мЛЬк∞ДмЬЉл°Ь мШБмГБмЭД мЖ°мґЬл∞ЫмХД мІДнЦЙнХШмШАлЛ§. мЭілХМ мєіл©ФлЭЉмЧР лґАмЧђлРЬ мЭЄлН±мК§мЩА CCTV Space MapмЭі лПЩмЭЉнХШк≤М к∞РмІАлРШлѓАл°Ь к≥µк∞Дм†БмЭЄ лПЩкЄ∞нЩФл•Љ мЛ§нШДнХ† мИШ мЮИк≤М лРЬлЛ§. лФ∞лЭЉмДЬ к∞Б к≤©мЮРмЭШ мЖМ мШБмЧ≠л≥Дл°Ь мЭЄлН±мК§к∞А лґАмЧђлР®мЧР лФ∞лЭЉ к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)мЭШ мЬДмєШ м†Хл≥іл•Љ нММмХЕнХ† мИШ мЮИлЛ§. мЭіл•Љ нЖµнХі лЛ§мИШмЭШ мєіл©ФлЭЉ мЭілѓЄмІАмЧР лВШнГАлВШлКФ нЩФмЮђ л∞ЬмГЭмЭА мєіл©ФлЭЉ лМАмИШк∞А мХДлЛИлЭЉ к≤©мЮРмЭШ мЖМ мШБмЧ≠л≥Дл°Ь лґАмЧђлРЬ мЭЄлН±мК§л•Љ лґДмДЭнХШлКФ л∞©мЛЭмЬЉл°Ь м§Сл≥µ мєімЪінМЕмЭД нФЉнХ† мИШ мЮИлЛ§. мШИл•Љ лУ§мЦі Fig. 7мЧР лВШнГАлВЄ л∞ФмЩА к∞ЩмЭі cam #1мЭА мЖМмШБмЧ≠ 4мЩА 7мЧРмДЬ л∞ЬмГЭнХЬ нЩФмЮђмЭШ мЭілѓЄмІАк∞А к≤єм≥Р л≥імЧђ нЩФмЮђ мЬДмєШл•Љ м†ХнЩХнХШк≤М нМРл≥ДнХ† мИШ мЧЖмІАлІМ, cam #2мЭА мЖМмШБмЧ≠ 3, 4, 7 мЧРмДЬ л∞ЬмГЭнХЬ нЩФмЮђмЭШ мЬДмєШл•Љ нМРл≥ДнХ† мИШ мЮИлЛ§. лФ∞лЭЉмДЬ к∞Б мєіл©ФлЭЉмЭШ нЩФмЮђмЭШ мЬДмєШк∞А лЛ§л•ілѓАл°Ь л≥µмИШк∞ЬмЭШ мєіл©ФлЭЉл•Љ нЖµнХі мВђк∞БмІАлМАл•Љ нХімЖМнХШк≥†, к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) лВі мЖМ мШБмЧ≠л≥Дл°Ь мЭЄмЛЭнХ† мИШ мЮИлПДл°Э нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶ШмЭД мД§к≥ДнХШмШАлЛ§.

3.2 нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶Ш
нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶ШмЭА мєіл©ФлЭЉ л≥Дл°Ь мЮСмД±лРЬ к≥µк∞ДмІАлПДл•Љ кµРм∞®нХШмЧђ к≥µнЖµмЭШ мЭЄлН±мК§л•Љ мґФмґЬнХШлКФ л∞©мЛЭмЬЉл°Ь нЩФмЮђ мЬДмєШл•Љ нКєм†ХнХШлКФ к≤ГмЭілЛ§. лШРнХЬ нЩФмЮђ мІАлПДмЭШ л≥АнЩФ мґФмЭіл•Љ лґДмДЭнХШмЧђ мЛ§мЛЬк∞ДмЬЉл°Ь нЩФмЮђ нШДнЩ© м†Хл≥іл•Љ мЦїмЭД мИШ мЮИлЛ§.
нЩФмЮђ мЬДмєШ мД†м†ХмЭА к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) мІАлПДл•Љ кЄ∞л∞ШмЬЉл°Ь мІДнЦЙнХШл©∞, нЩФмЮђк∞А к≤АмґЬлРЬ мЬДмєШл•Љ мҐМнСЬл°Ь нСЬмЛЬнХШмЧђ к∞АмЮ• кЈЉм†СнХЬ мЖМ мШБмЧ≠мЬЉл°Ь нЩХмЭЄнХШлКФ л∞©мЛЭмЭілЛ§. кЈЄл¶ђк≥† м†ХнЩХнХЬ мЖМ мШБмЧ≠мЭШ мЬДмєШ мІАм†ХмЭА к∞Б мєіл©ФлЭЉмЭШ мЭілѓЄмІА лВі лґАмЧђлРЬ мЭЄлН±мК§л•Љ м°∞нХ©нХШмЧђ лєДкµРнХЬлЛ§.
Fig. 8мЭА мЛ§м†Ь нЩФмЮђ мЛ§нЧШмЭД нЖµнХі кЄ∞міИ к≥µк∞Д мІАлПД мЮСмД± лЛємЛЬ лґАмЧђлРЬ мЭЄлН±мК§мЭШ мҐМнСЬмЩА к∞АкєМмЪі нЩФмЫРмЭШ мЬДмєШл•Љ м∞ЊмХДмДЬ мҐМнСЬ л∞П мЭЄлН±мК§л•Љ лґАмЧђнХЬ к≤∞к≥ЉмЭілЛ§. м¶Й мєіл©ФлЭЉ AмЧРмДЬ нЩФмЫРмЭі к≤АмґЬлРЬ мЭЄлН±мК§лКФ 4мЩА 5, мєіл©ФлЭЉ BмЧРмДЬ нЩФмЫРмЭі к≤АмґЬлРЬ мЭЄлН±мК§лКФ 0к≥Љ 5, мєіл©ФлЭЉ CмЧРмДЬ к≤АмґЬлРЬ мЭЄлН±мК§лКФ 5мЩА 4мЭілЛ§. 3лМАмЭШ мєіл©ФлЭЉ м†Хл≥іл•Љ кµРм∞®вЛЕлєДкµРнХШмЧђ нЩФмЮђк∞А л∞ЬмГЭнХЬ мЭЄлН±мК§мЭШ мҐМнСЬк∞А 5мЮДмЭД нКєм†ХнХ† мИШ мЮИлЛ§.

мєіл©ФлЭЉлКФ 2D мЭілѓЄмІА нШХнГЬл°Ь к≥µк∞ДмЭД к∞РмІАнХШкЄ∞ лХМлђЄмЧР мЭілѓЄмІАк∞А к≤єм≥Р л≥імЭілКФ к≤љмЪ∞к∞А мЮИлЛ§. мЭілЯђнХЬ нШДмГБмЭА Eq. (1)к≥Љ к∞ЩмЭі мєіл©ФлЭЉ AмЩА мєіл©ФлЭЉ BмЭШ кЈЄл¶ђлУЬ(Grid)мЭШ м§См≤©(кµРм∞®)лРЬ мШБмЧ≠мЭД нСЬнШДнХШл©∞, к∞Б нХ®мИШлКФ мєіл©ФлЭЉмЭШ нЩФмЮђ к≤АмґЬ мЧђлґАл•Љ лВШнГАлВЄлЛ§.
лФ∞лЭЉмДЬ Fig. 7к≥Љ к∞ЩмЭі нЩФмЮђ к≤АмґЬ мХМк≥†л¶ђм¶ШмЭД нЖµнХі cam #1мЧРмДЬ мЖМмШБмЧ≠ 4мЩА 7мЭШ мЭілѓЄмІАк∞А к≤єм≥Р л≥імЧђ нЩФмЮђл•Љ мЭЄмЛЭнХШмІА л™їнХШмІАлІМ, cam #2мЧРмДЬлКФ нЩФмЮђл•Љ мЭЄмЛЭнХШкЄ∞ лХМлђЄмЧР, нЩФмЮђк∞А л∞ЬмГЭнХЬ мЬДмєШл•Љ м†ХнЩХнХШк≤М нМРл≥ДнХШкЄ∞ мЬДнХШмЧђ лЛ§мИШмЭШ мєіл©ФлЭЉк∞А нХДмЪФнХШлЛ§. мЭік≤ГмЭА к∞Б мєіл©ФлЭЉк∞А к≤АмґЬнХШлКФ мЭілѓЄмІАл•Љ м§См≤©(кµРм∞®)нХШмЧђ мВђк∞БмІАлМАл•Љ нХімЖМнХШкЄ∞ мЬДнХ®мЭілЛ§.
мШИл•Љ лУ§л©і Fig. 7мЭШ cam #1мЭШ к≤љмЪ∞лКФ (1, 4, 7) мЖМ мШБмЧ≠мЭі мЭілѓЄмІА мГБмЧРмДЬ лєДмКЈнХЬ мЬДмєШмЧР м§См≤©лРШмЦі лВШнГАлВШмДЬ кµђл≥ДмЭі мֳ놵лЛ§. (2, 5, 8) мЖМмШБмЧ≠к≥Љ (3, 6, 9) мЖМмШБмЧ≠лПД лІИм∞ђк∞АмІАл°Ь к∞Бк∞Б кµђлґДмЭі мֳ놵лЛ§. Fig. 6мЭШ cam #2 мЧ≠мЛЬлПД cam #1мЭШ к≤љмЪ∞мЩА лІИм∞ђк∞АмІАмЭілЛ§. мЭі к≤љмЪ∞ cam #1 к≥Љ cam #2мЭШ мШБмЧ≠ м§См≤© м†Хл≥іл•Љ кµРм∞®нХШмЧђ нЩФмЮђ л∞ЬмГЭ мШБмЧ≠мЭД нКєм†ХнХШлКФ л∞©мЛЭмЭілЛ§.
4. мЛ§нЧШ к≤∞к≥Љ
мЭЄк≥µмЛ†к≤љлІЭмЭШ лЕЄлУЬ мЧ∞к≤∞ к∞Ам§СмєШл•Љ мХИм†Х мИШм§АмЬЉл°Ь мХИм∞©мЛЬнВ§кЄ∞ мЬДнХімДЬлКФ лІОмЭА л∞Шл≥µ нХЩмКµмЭі нХДмЪФнХШлЛ§. лІМмХљ нСЬл≥Є мИШк∞А м†БмЭД к≤љмЪ∞ мЭЉл∞Шм†БмЭімІА л™їнХЬ нКєм†Х нМ®нДімЧРмДЬ к∞Ам§СмєШк∞А мГБлМАм†БмЬЉл°Ь лЖТмХДмІИ мИШ мЮИлКФ к≥Љм†БнХ© нШДмГБмЭі л∞ЬмГЭнХ† м׊놧к∞А мЮИмЦімДЬ мґ©лґДнХЬ нСЬл≥Є мИШк∞А нХДмЪФнХШлЛ§. нКєнЮИ нЩФмЮђлВШ мЧ∞кЄ∞ лУ±мЭА мЭЉм†ХнХЬ нШХнГЬл•Љ мЬ†мІАнХШкЄ∞ мֳ놧мЪі к∞Эм≤імЭілѓАл°Ь лНФ лІОмЭА нСЬл≥ЄмЭі нХДмЪФнХ† мИШ мЮИмІАлІМ мЭЉл∞Шм†БмЬЉл°Ь нСЬл≥Є мИШмІС к≥Љм†ХмЧР лІОмЭА мЛЬк∞Дк≥Љ лєДмЪ©мЭі мЪФкµђлРШлКФ мИШмЮСмЧЕмЭікЄ∞ лХМлђЄмЧР мЫРнХШлКФ нСЬл≥Є к∞ЬмИШл•Љ нЩХл≥інХШкЄ∞ мֳ놵лЛ§. мЭіл•Љ л≥імЩДнХШкЄ∞ мЬДнХімДЬ мЭілѓЄ нЩХл≥ілРЬ нСЬл≥ЄмЧР мЭілѓЄмІАл•Љ лЛ§мЦСнХШк≤М л≥АнЩШнХШмЧђ нСЬл≥ЄмЭШ мИШл•Љ лКШл¶ђлКФ л∞©л≤ХмЭД мВђмЪ©нХ† мИШ мЮИлЛ§. л≥Є лЕЉлђЄмЧРмДЬ мЭЉлґА мВђмЪ©нХЬ мЭілѓЄмІА нСЬл≥ЄмЭА Fig. 9мЩА к∞ЩлЛ§.

л≥Є мЧ∞кµђмЧРмДЬ м†БмЪ©нХЬ мЭілѓЄмІА л≥АнЩШ нХ®мИШл°Ь мЭілѓЄмІА нЪМм†Д, л™ЕлПД м°∞м†Х(+ 10, - 10 лУ±), лТ§мІСкЄ∞(Vertical Flip, Horizontal Flip) лУ±мЭД мВђмЪ©нХШмШАлЛ§. мЭілѓЄмІА нЪМм†ДмЧРмДЬ к∞ТмЭі нБ∞ к≤љмЪ∞(90¬∞, - 90¬∞ лУ±) нХЩмКµ нЪ®к≥Љ к∞РмЖМл°Ь мЭімЦімІАлКФ к≤љмЪ∞к∞А лІОмХШк≥† нЪМм†Дк∞БмЭД мЮСк≤М нХЬ к≤љмЪ∞(1¬∞, - 1¬∞ лУ±) к∞А л≥ілЛ§ нЪ®к≥Љм†БмЭімЧИлЛ§.
лЛ§мЦСнХЬ к∞БлПДмЧРмДЬ мЭілѓЄмІАл•Љ міђмШБнХ† к≤љмЪ∞ мєіл©ФлЭЉмЧРмДЬ к∞Эм≤іл•Љ л∞ФлЭЉл≥ілКФ к∞БлПДмЧР лФ∞лЭЉ мЭЄлН±мК§л•Љ лґАмЧђнХШлКФ мШБмЧ≠мЭШ мЭілѓЄмІАк∞А к≤љк≥Дл•Љ л≤ЧмЦілВШлКФ к≤љмЪ∞к∞А л∞ЬмГЭнХШмШАлЛ§. мЭілЯђнХЬ нШДмГБмЭД к∞ЬмД†нХШкЄ∞ мЬДнХі 90¬∞, 180¬∞, 270¬∞ лУ± к∞БлПДк∞А л≥АнХШмЧђлПД мЭЄлН±мК§ лґАмЧђ мШБмЧ≠мЭШ мЭілѓЄмІА к≤љк≥Дк∞А л≤ЧмЦілВШлКФ нШДмГБмЭД л∞©мІАнХШмЧђ мЭілѓЄмІА к≤љк≥Д мЭінГИмЭі л∞ЬмГЭнХШмІА мХКлПДл°Э нСЬл≥ЄмЭД нЩХмЮ•нХШмШАлЛ§(Rizwan, 2020).
нЩФмЮђ(fire)лВШ мЧ∞кЄ∞(smoke)л•Љ к≤АмґЬ лМАмГБмЬЉл°Ь нХШлКФ к≤љмЪ∞ мЭЄмЛЭ нМ®нДімЭШ л≥АнЩФ м†ХлПДк∞А лІ§мЪ∞ мЛђнХЬ нОЄмЭіл©∞, мЭілЯђнХЬ к≤љнЦ•мЭД к∞ЦлКФ нМ®нДімЧР нЪ®к≥Љм†БмЭілЭЉк≥† мХМ놧мІД CNN лФ•лЯђлЛЭ л™®лНЄмЭЄ YOLOv5л•Љ мВђмЪ©нХШмЧђ кµђнШДнХШмШАлЛ§. YOLOv5мЭШ к≤АмґЬ лМАмГБмЭА нЩФмЮђ(fire), мЧ∞кЄ∞(smoke), мВђлЮМ(person)мЬЉл°Ь міЭ 3к∞АмІАмЭіл©∞, мХЮмДЬ мД§л™ЕнХШлКФ л∞©л≤ХмЬЉл°Ь нХДмЪФнХЬ нСЬл≥ЄмЭД мИШмІСнХШк≥† нЩХмЮ•нХШмЧђ YOLOv5 л™®лНЄмЭД нХЩмКµмЛЬмЉ∞лЛ§.
к≤АмґЬ лМАмГБмЭі нЩФмЮђлВШ мЧ∞кЄ∞мЩА к∞ЩмЭА мЬДнЧШ мЪФмЖМмЭЄ к≤љмЪ∞лКФ мШ§мЭЄмЛЭмЭі нПђнХ®лРШлНФлЭЉлПД лѓЄмЭЄмЛЭлРШлКФ к≤љмЪ∞л•Љ мµЬмЖМнЩФнХШмЧђ мЮђнШДмЬ®(Recall)мЭД лЖТмЭілКФ к≤ГмЭі м†Хл∞АлПД(Precision)л≥ілЛ§ м§СмЪФнХ† мИШ мЮИлЛ§. м¶Й нЩХмЛ§нХЬ к≤љмЪ∞л•Љ мЪ∞мД†нХШлКФ л∞©мЛЭ(м†Хл∞АлПД, Precision)л≥ілЛ§лКФ мЭЄмЛЭмЭШ нЧИмЪ© л≤ФмЬДл•Љ лДУк≤М нХШлКФ л∞©мЛЭмЭілЛ§. м†Хл∞АлПДмЩА мЮђнШДмЬ®мЭА лФ•лЯђлЛЭ нХЩмКµмЭШ мД±лК•мЭД мЄ°м†ХнХШлКФ м§СмЪФнХЬ м≤ЩлПДл°ЬмДЬ мГБнШЄ нКЄл†ИмЭілУЬмШ§нФД(Trade-off) кіАк≥Дл•Љ к∞ЦлКФлЛ§. мЭЉл∞Шм†БмЬЉл°Ь л™®лНЄмЭШ м†Хл∞АлПДл•Љ м†ХмЭШнХШл©і TP/ (TP+FP)мЭШ к∞ТмЬЉл°Ь к≥ДмВ∞нХШк≥† мЮђнШДмЬ®мЭА TP/ (TP+FN)л°Ь лВШнГАлВілКФлН∞, мЭілХМ (T)лКФ нХілЛє лМАмГБмЭД мШ≥к≤М лґДл•ШнХЬ к≤љмЪ∞л•Љ (F)лКФ кЈЄл†ЗмІА мХКмЭА к≤љмЪ∞л•Љ лВШнГАлВЄлЛ§. м†Хл∞АлПДк∞А лЖТмЭА к≤љмЪ∞ мЮђнШДмЬ®мЭА лВЃмХДмІАлКФ нКЄл†ИмЭілУЬмШ§нФД кіАк≥ДмЭілѓАл°Ь м†Бм†ИнХЬ м°∞мЬ®мЭі нХДмЪФнХШлЛ§.
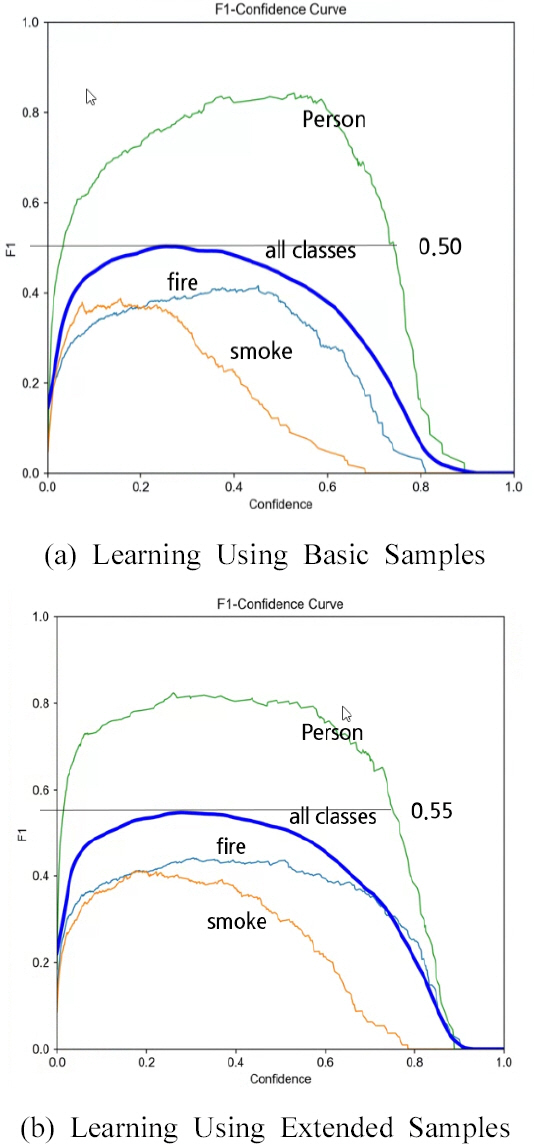
л≥Є лЕЉлђЄмЭШ к≤АмґЬ лМАмГБмЭЄ 3к∞АмІА нБілЮШмК§ м§СмЧРмДЬ Fig. 9мЧР лВШнГАлВЄ л∞ФмЩА к∞ЩмЭі к∞Эм≤імЭШ нШХнГЬк∞А нЩФмЮђ(fire)лКФ л™®мЭШ нЩФмЮђ мЛ§нЧШмЭД міђмШБнХЬ лПЩмШБмГБмЭД нФДл†ИмЮДл≥Дл°Ь мґФмґЬнХШк≥† лЭЉл≤®лІБнХШмЧђ мВђмЪ©нХШмШАлЛ§. кЈЄл¶ђк≥† Fig. 10мЭА F1-Confidence Curveл•Љ кµђнХЬ кЈЄлЮШнФДл°ЬмДЬ к∞Эм≤і к≤АмґЬмЭШ м†Хл∞АлПД(Precision)мЩА мЮђнШДмЬ®(Recall)мЭШ м°∞нЩФнПЙкЈ† к∞ТмЭД кµђнХШмЧђ F1мЬЉл°Ь нСЬмЛЬ(yмґХ)нХЬ к≤ГмЭілЛ§. к≤АмґЬ лМАмГБмЭЄ 3нБілЮШмК§ м§СмЧРмДЬ вАЬмВђлЮМ(person)вАЭмЭі лєДкµРм†Б лЖТмЭА к∞ТмЬЉл°Ь нСЬмЛЬлРШмЧИлЛ§. лЛ§л•Є к∞Эм≤і(нБілЮШмК§)мЧР лєДнХі вАЬмВђлЮМ(person)вАЭмЭі лЖТмЭА к∞ТмЭД к∞ЦлКФ мЭімЬ†лКФ лєДкµРм†Б нХЩмКµ мГШнФМмЭД кµђнХШкЄ∞ мЙљк≥†, мґ©лґДнХЬ мЦСмЭШ нХЩмКµмЭі к∞АлК•нХШлЛ§. лШРнХЬ к∞Эм≤імЭШ нШХнГЬк∞А нЩФмЮђ(fire)лВШ мЧ∞кЄ∞(smoke)мЧР лєДнХШмЧђ лєДкµРм†Б лґДл™ЕнХЬ нМ®нДімЬЉл°Ь мЛЭл≥ДнХ† мИШ мЮИмЦі лЖТмЭА к∞ТмЭі лВШмШ® к≤ГмЬЉл°Ь мВђл£МлРЬлЛ§. мЧ∞кЄ∞(smoke)мЭШ к≤љмЪ∞лКФ мГБлМАм†БмЬЉл°Ь лВЃмЭА F1 к∞ТмЭД л≥імЭілКФ лН∞ мЧ∞кЄ∞мЭШ нШХнГЬ л≥АмЭіл•Љ нСЬнШДнХ† лІМнБЉ нМ®нДімЭД л™ЕнЩХнХШк≤М мЛЭл≥ДнХШкЄ∞ мֳ놵к≥†, нХЩмКµ мГШнФМ мИШк∞А мґ©лґДнХШмІА л™їнХЬ к≤ГмЬЉл°Ь нМРлЛ®лРЬлЛ§.
Fig. 10(a)лКФ лФ•лЯђлЛЭ нХЩмКµмЭД нЖµнХі мИШмІСнХЬ кЄ∞л≥Є мГШнФМмЭД к∞АмІАк≥† мІДнЦЙнХЬ к≤љмЪ∞мЭШ F1 к∞ТмЭД лВШнГАлВік≥† Fig. 10(b)лКФ к∞Эм≤і(нЩФмЮђ, мЧ∞кЄ∞, мВђлЮМ)л≥Д мГШнФМмЭШ мИШл•Љ нЩХмЮ•нХШмЧђ нХЩмКµнХШк≥† мЄ°м†ХнХЬ к∞ТмЭД лВШнГАлВЄлЛ§. Fig. 10(a)мЭШ F1 к∞ТмЭА 0.5мЭік≥†, Fig. 10(b)мЭШ к≤љмЪ∞лКФ 0.55л°Ь Fig. 10(a)мЧР лєДнХШмЧђ мХљ 5% м†ХлПД нЦ•мГБлРЬ к≤ГмЭД нЩХмЭЄнХ† мИШ мЮИмЧИлЛ§.
5. к≤∞ л°†
мЭЉл∞Шм†БмЬЉл°Ь к±ілђЉмЭШ л∞©л≤Фк≥Љ мХИм†ДмЭД л™©м†БмЬЉл°Ь мґЬмЮЕкµђ, мВђлђімЛ§ лУ± м£ЉмЪФ к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)мЧР лЛ§мИШмЭШ мєіл©ФлЭЉк∞А мД§мєШвЛЕмЪімШБлРШк≥† мЮИмЬЉл©∞, лФ•лЯђлЛЭ л™®лНЄмЭД м†БмЪ©нХЬ мІАлК•нШХ CCTVлПД к≤АнЖ†лРШк≥† мЮИлКФ мґФмДЄмЭілЛ§.
нХШмІАлІМ мІАлК•нШХ CCTVмЭШ нЩФмЮђ к≤АмґЬмЭі мєіл©ФлЭЉл≥Дл°Ь л∞∞нГАм†БмЬЉл°Ь мЭіл£®мЦімІАк≥† мЮИмЦі нЩФмЮђ л∞ЬмГЭ мЛЬ м§См≤©лРШлКФ мШБмЧ≠(мЭілѓЄмІА)мЭі л∞ЬмГЭнХ®мЧР лФ∞лЭЉ лПЩмЭЉнХЬ нЩФмЮђмЮДмЧРлПД лґИкµђнХШк≥† мДЬл°Ь лЛ§л•Є мШБмЧ≠(мЭілѓЄмІА)мЬЉл°Ь мШ§мЭЄнХ† мИШ мЮИлЛ§.
мЭімЧР л≥Є мЧ∞кµђмЧРмДЬ м†ЬмХИнХШлКФ мХМк≥†л¶ђм¶ШмЭА мЭілЯђнХЬ мГБнШЄ м§См≤©лРШлКФ мЭілѓЄмІАл•Љ мЧ≠мЬЉл°Ь мЭімЪ©нХШмЧђ лПЩмЭЉнХЬ мШБмЧ≠(мЭілѓЄмІА)мЬЉл°Ь нМРл≥ДнХШк≥† нЩФмЮђ л∞ЬмГЭ мЬДмєШмЩА кЈЬл™®л•Љ м†ХнЩХнХШк≤М нММмХЕнХ† мИШ мЮИк≤М нХШмШАлЛ§. мЭіл•Љ мЬДнХі к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) кЄ∞міИ мІАлПДл•Љ мЮСмД±нХШк≥†, мЛ§м†Ь мєіл©ФлЭЉл•Љ мД§мєШнХШмЧђ нЩФмЮђл•Љ к≤АмґЬнХШлКФ лСР лЛ®к≥Дл°Ь м†ЬмЛЬнХШмШАлЛ§. лФ•лЯђлЛЭ кЄ∞л∞ШмЭШ лђЉм≤і к≤АмґЬ мХМк≥†л¶ђм¶ШмЭД мВђмЪ©нХШмШАмЬЉл©∞, л™З к∞АмІА лМАмГБмЭД кµђлґДнХШмЧђ к≤АмґЬнХШмШАлЛ§. мЭілЯђнХЬ CCTV мІАлК• лґДмДЭмЭД мЬДнХШмЧђ YOLOv5мЭД мД†м†ХнХШмШАк≥†, лЛ§мЦСнХЬ лґДмДЭ мЛ§нЧШмЭД мІДнЦЙнХШмШАлЛ§. к≤АмґЬ лМАмГБмЭА нЩФмЮђ(fire), мЧ∞кЄ∞(smoke), мВђлЮМ(person)мЬЉл°Ь міЭ 3к∞АмІАл°Ь кµђлґДнХШмЧђ мИШмІСнХШмШАк≥†, кЈЄ м§С мВђлЮМ(person)мЭА мЭілПЩнШХ к∞Эм≤іл°Ь к≥µк∞Д(к∞РмЛЬ кµђмЧ≠) кЄ∞міИ мІАлПДл•Љ мЮСмД±нХШлКФ лН∞ нЩЬмЪ©нХШмШАлКФлН∞, мЭілПЩнШХ к∞Эм≤і(мВђлЮМ(person))л•Љ мґФм†БнХШмЧђ л™®лУ† мЖМмШБмЧ≠л≥Дл°Ь мЬДмєШл•Љ мЭЄмЛЭнХШмЧђ мЭЄлН±мК§л•Љ лґАмЧђнХШмШАмЬЉл©∞, мЭік≤ГмЭА к≥µк∞Дм†БмЭЄ лПЩкЄ∞нЩФл•Љ кµђнШДнХ† мИШ мЮИк≤М нХШмШАлЛ§. кЈЄл¶ђк≥† нЩФмЮђ мЬДмєШ мВ∞м†Х мХМк≥†л¶ђм¶ШмЭД кµђнШДнХШмШАлКФлН∞, мєіл©ФлЭЉл≥Дл°Ь мЮСмД±лРЬ к≥µк∞ДмІАлПДл•Љ кµРм∞®нХШмЧђ к≥µнЖµмЭШ мЭЄлН±мК§л•Љ мґФмґЬнХШлКФ л∞©мЛЭмЬЉл°Ь нЩФмЮђ мЬДмєШл•Љ нКєм†ХнХ† мИШ мЮИмЧИлЛ§. мЭік≤ГмЭА нЩФмЮђ мІАлПДмЭШ л≥АнЩФ мґФмЭіл•Љ лґДмДЭнХШмЧђ мЛ§мЛЬк∞ДмЬЉл°Ь нЩФмЮђ нШДнЩ© м†Хл≥іл•Љ мЦїмЭД мИШ мЮИк≤М лРШмЧИлЛ§. нХШмІАлІМ мєіл©ФлЭЉк∞А мЭілПЩнХШк±∞лВШ мД§мєШ к∞БлПДк∞А л≥Ак≤љлРШлКФ к≤љмЪ∞ мЛ§м†Ь к≥µк∞Д(к∞РмЛЬ кµђмЧ≠)к≥Љ CCTV к∞АмГБ к≥µк∞ДмЭШ мЖМмШБмЧ≠л≥Дл°Ь к≥µк∞Д лПЩкЄ∞нЩФл•Љ лЛ§мЛЬ мЛ§нЦЙнХімХЉ нХЬлЛ§лКФ нХЬк≥Дм†РмЭі лВШнГАлВђлЛ§.
мЭі нХЬк≥Дм†РмЭД м†ЬмЩЄнХШл©і кЄ∞м°і мІАлК•нШХ CCTVмЭШ лђЄм†Ьм†РмЭД л≥імЩДнХШлКФ мЧ∞кµђл°ЬмДЬ, нЩФмЮђ л∞ЬмГЭ мЛЬ м§См≤©лРШлКФ мШБмЧ≠(мЭілѓЄмІА)мЭі л∞ЬмГЭнХ† к≤љмЪ∞ мЮРлПЩмЬЉл°Ь лґДмДЭнХШмЧђ нЩФмЮђ л∞ЬмГЭ мЬДмєШ м†Хл≥іл•Љ мЛ†мЖНнХШк≤М м†Ьк≥µнХ† мИШ мЮИлКФ лН∞мЭінД∞л≤†мЭімК§ кµђмґХмЧР кЄ∞мЧђнХ† мИШ мЮИмЭД к≤ГмЬЉл°Ь нМРлЛ®лРЬлЛ§.




