


1. 서론
최근 기후변화의 영향으로 전 세계적으로 홍수, 가뭄, 폭설 등 기상이변에 따른 자연재해가 빈번히 발생하고 있다. 기후변화에 관한 정부간 협의체 (Intergovernmental panel on Climate Change, IPCC)의 제 5차 평가 보고서 (Fifth assessment report, AR5)에 따르면, 기후변화로 극한 기상의 발생패턴이 변화되어 홍수, 가뭄, 폭설 등 기상이변이 더욱 증가하여 피해가 심각해질 것이라고 한다. 우리나라에서 최근에 발생한 자연재해별 피해현황을 살펴보면 대설피해는 홍수피해에 이어 두 번째로 큰 피해를 미치는 것으로 나타나고 있다. 그럼에도 불구하고, 폭설이 주로 발생하는 지역은 인구밀도가 낮은 강원도나 전라도 지역이고 홍수피해 보다 상대적으로 그 영향이나 규모가 작아 많은 관심을 받지 못하고 있다. 실제로 국민안전처에서 발간하는 재해연보에 따르면, 1994년에서 2013년까지 지난 20년간 자연재해에 의한 피해액은 12조 3천억 원으로 집계되었으며, 이 중 강우와 태풍에 의한 피해가 85 %이고, 대설에 의한 피해는 약 13 % 이다. 최근 2014년 2월에는 강원도와 경상도 지역을 중심으로 50 cm이상의 폭설이 내렸으며, 2월 17일 경주의 마우나리조트의 강당이 무너져 10명의 사망자가 발생하는 등 최근 대설피해의 규모가 증가하는 추세이다. 이처럼 최근에는 대설에 따른 인명 및 경제적인 피해가 증가하므로, 이에 대한 대비와 대책 마련이 요구되고 있다.
하지만, 대설피해에 관련된 연구는 어느 정도의 진전되어 있을 뿐 아직 미흡한 실정이다. 국내에서는 자연재해에 의한 피해액을 추정하는 연구도 대부분 강우와 태풍에 의한 홍수 피해에 그 초점이 맞추어져 있으며, 그 동안 대설피해에 관련된 연구는 대부분 지점별 최심적설량이나 최심신적설량 등 극치 통계분석을 통한 피해액을 산정하여 제시하고 있다 (Jeong and Heo, 2014). Lee (2013)는 우리나라의 9개의 권역 (강원도, 수도권, 충남, 충북, 전남, 전북, 경남, 경북, 제주도)을 선정하여 강우와 태풍에 대한 상관성을 분석하고, 복합특성에 따른 각각 최적의 상관계수를 도출하고, 회귀분석을 이용하여 태풍의 피해규모 예측모델을 개발하였다. Kim (2003)은 사업자산에 따른 피해율과 홍수범람구역 내 산업별 자산액으로부터 결정된 행정구역별 피해액을 유역으로 환산하여 이를 서울지역을 대상으로 피해액을 추정하였다. Lee et al. (2006)은 도시지역에 적합하도록 다차원법의 홍수피해 산정 요소들을 보정하고 적용하여 다차원법과 비교하였으며, Kim (2013)은 공공시설물 홍수 피해액 추정 및 홍수피해지수를 개발하여 다차원법의 공공시설물 산정방식에 대한 문제점을 개선하였다. Jeong and Lee (2014)에서는 폭설에 의한 인명피해와 이재민수를 예측하기 위해 기후변수 (신적설량, 대설일수)와 사회⋅경제적 변수 (인구, GRDP, 면적)를 사용한 다중회귀모형을 구축하였다. Kwon, et al. (2016)에서는 대설피해액의 예측모델을 개발하기 위해 최심적설량과 사회⋅경제적 요인 (인구, 면적, GRDP)를 고려하여 다중회귀 모형을 구성하였으나, 효율이 높지 않았다. 이는 피해액 규모에 영향을 미치는 인자들이 복잡하여, 그 메카니즘을 정확히 모의하는 것이 어렵기 때문에 회귀모형이 가지는 한계로 보여진다.
회귀분석을 이용한 피해액 추정 연구를 살펴보면, Dornald et al. (1999)는 기후관련 요인 (폭풍우 피해액, 시간당 최대 풍속)과 사회⋅경제적 요인 (가구당 소득, 주택 및 사업체 수)의 회귀분석을 이용하여 폭풍우의 피해액을 추정하였다. Pielke and Downton (2000)은 미국 전 지역을 대상으로 기후관련 요인 (강수량, 강우강도)의 변화와 인문⋅사회적 요인 (소득, 인구 등)의 영향을 이용하여 다중회귀분석을 이용하여 홍수피해액을 추정하였다. Toya and Skidmore (2007)에서는 자연재해에 따른 인명피해와 GDP당 피해액을 예측하기 위해 사회 ⋅경제적 요인 (학교 수업일수, 정부예산 규모 등)을 고려하여 다중회귀 모형을 구성하고, OECD국가와 개발도상국을 대상으로 분석을 수행하였다. 교육수준과 경제규모가 증가함에 따라 자연재해에 따른 피해가 줄어드는 경향이 있다고 밝혀냈으나 구축된 모형의 수정결정계수가 0.09~0.35로 그 효율이 높지 않았다. Cavallo et al. (2010)은 자연재해 자료 (사상자, 피해 규모 등)를 수집하고 사회⋅경제적 요인 (국내총생산량, 인구 규모, 면적)과의 선형관계를 나타내는 Log-Log 회귀모형을 구축하여 피해액을 추정하였다. Muranae and Elsner (2012)는 허리케인 피해액과 풍속 자료를 바탕으로 분위회귀분석 (quantile regression analysis)을 실시하여, 실제 발생한 허리케인의 피해액을 비교적 정확히 추정할 수 있었다. Mendelsohn and Saher (2011)은 전 세계의 재해피해액 자료와 인구, 소득 자료 그리고 기상 관측자료 (강수량, 기온 등)를 바탕으로 회귀모형을 구축하고, 기후모형과 국내총생산량 성장률 및 인구성장률 적용을 통해 2100년 시점의 각 국가의 자연재해의 피해액을 추정하였다. Liu (2012)는 호우 피해액과 극한 강도의 강우 유출량 등의 수문학적 변수, 1인당 소득, 인구, 기존 피해액의 빈도 등과 같은 사회⋅경제적 변수로 구성된 패널데이터를 구축하여 피해액을 추정하고, Cavallo and Noy (2010)은 기후관련 요인과 사회⋅경제적 요인을 고려하여 대설에 따른 경제적 피해액을 추정하여 제시하고 있다.
본 연구에서는 각기 다른 변수들의 비선형 과정을 고려할 수 있는 인공신경망과 두 개 이상의 독립변수들 사이의 관계를 파악할 수 있는 다중회귀 모형을 이용하여 대설피해 추정 함수를 개발하고자 한다. 이에 따라, 대상지역과 기후관련 요인 (Climate factor) 및 사회⋅경제적 요인 (society-economic factor) 총 10개의 변수를 선정하여, 기술통계기법인 주성분분석을 적용하여 변수들 간의 차원을 축소하고 입력 자료를 구축한 후, 각 지역의 도시면적 비율에 따라 3개 권역으로 구분하였다. 3개 권역으로 구분된 각 입력 자료는 2009년까지의 자료를 이용하여 모형을 구성한 후 나머지 2010년부터 2015년까지의 자료를 검증용 자료로 활용하였다. 인공신경망 및 다중회귀 모형을 구성하여 피해액을 산정하고 동일 기간의 실제 피해액과의 통계오차분석을 수행하였다. 또한, 인공신경망 모형과 다중회귀 모형을 이용하여 통계적으로 예측된 피해액을 각각 비교하여 모형의 성능도 검증하였다.
2. 분석 방법
2.1 인공신경망
인공신경망 (Artificial Neural Network)은 뇌기능의 특성 몇 가지를 컴퓨터 시뮬레이션으로 표현하는 것을 목표로 하는 수학 모델이다. 음성이나 얼굴 인식 등 복잡한 일을 빠르게 수행하는 사람의 뇌는 컴퓨터의 순차처리에 비해 근본적으로 다른 정보처리 방식을 사용한다. 컴퓨터는 단순 계산에서 사람을 훨씬 능가하지만 얼굴인식이나 음성 인식과 같이 사람이 일상에서 아주 쉽게 수행하는 일에서는 아직 낮은 성능을 벗어나지 못하고 있다. 신경망을 개발한 동기는 사람의 뇌를 모방한 새로운 컴퓨터 구조를 설계하여 이러한 지능적인 일을 수행하려는 욕구에서 찾을 수 있다. 이렇게 인공적으로 개발된 신경망을 생물학적 신경망 (BNN)과 구분하여 인공신경망 (ANN)이라고 한다 (Oh, 2000).
인공신경망은 뉴론이라 불리는 인간의 신경세포와 유사한 PE (Processing Element)로 이루어져 있다. PE는 입력, 출력, 가중치, 뉴론함수의 네 부분으로 되어 있다. 입력과 출력은 0/1, 연속치, 집단 등의 다양한 형태를 가질 수 있다. 각각의 입력은 효과에 대한 상대적인 가중치를 가지고, 가중치는 입력신호의 정도를 나타내기 위해 모형 내에서 결정된다. 뉴론함수는 합산 (summation), 활성화 (activation), 전이 (transfer), 학습 (learning)의 네 가지가 있다. 합산합수는 가중치에 따라 입력을 더하고, 그 결과는 활성화함수의 입력이 된다. 전이함수는 활성화함수의 결과를 받아 이미 정해진 크기와 비교한 후, 다음 PE에게 적절한 가중치를 가진 출력을 보내준다. 학습함수는 현재의 출력과 원하는 출력을 비교하여 오차를 감소시킨다. 병렬적으로 동시에 실행되는 PE의 집합을 층 (layer)이라 부른다. 입력층과 출력층이 문제에서 정의된 변수에 따라 확정적인데 반해 은닉층 PE의 수는 유동적이다.
인공신경망은 적응성 (adaptability)과 결점포용력 (fault tolerance)이라는 두 가지의 큰 특징을 가지고 있다. 인공신경망은 하나의 처리 장치가 아닌 다수의 PE들이 상호작용을 통해 처리되므로, 불완전한 자료로부터 학습과 의사결정을 할 수 있는데, 이러한 특성을 결점포용력이라 한다. 적응성은 인공신경망의 자기변화를 의미하는 것으로, 지속적인 학습을 통해 가중치를 변화시키면서 적합한 모델을 만드는 과정을 말한다.
다층퍼셉트론은 Fig. 1과 같이 하나 이상의 은닉층을 사용하고, 처리요소들 사이의 층간 연결은 전부 정방향 (fully-connected feed forward)의 연결 형태이며, 층간 연결은 없다. 지도학습의 대표적인 역전파 알고리즘은 일반화된 델타 학습규칙으로 볼 수 있는데, 이 학습규칙은 전이함수의 미분값을 요구하므로 Rosenblatt의 퍼셉트론에 많이 사용된 계단형 함수 대신 미분이 가능한 비선형 함수인 시그모이드 함수를 PE 내의 전이함수로 많이 사용한다 (Cho, 2003).
2.2 다중회귀분석
회귀분석은 시간에 따라 변화하는 데이터나 어떤 영향은 가설적 실험, 인과 관계의 모델링 등의 통계적 예측에 이용될 수 있다. 하나의 독립변수만을 고려하여 종속변수와의 관계를 분석하는 방법을 단순회귀분석 (simple regression analysis)라고 하고, 두 개 이상의 독립변수을 고려하는 방법을 다중회귀분석 (multiple regression analysis)이라고 한다. 실제로 단일 요인에 의해서 결정되는 경우는 매우 드물며, 현실적으로 종속변수에 영향을 미치는 독립변수를 두 개 이상 고려해야 되는 경우가 빈번하다. 다중회귀분석은 종속변수의 변화를 설명하기 위해 두 개 이상의 독립변수가 사용되는 선형회귀 모형을 말하고, 단순회귀분석을 확장한 것이다.
다중회귀분석은 여러 개의 독립변수를 사용함으로서 예측 능력을 높일 수 있다. 이 모형은 정량적인 종속변수Y 와 독립변수군인X1, X2, X3, …, Xi사이의 관계를 적합 시키기 위해 사용된다. 독립변수가i개인 다중회귀분석의 기본 모형은 Eq. (1)과 같다.
Eq. (1) 에서β0, β1, β2, −, βi 은 회귀계수 (coefficient)이고, ϵ는 종속변수Y를 측정할 때 발생하는 오차이다. 회귀모형의 추정은 회귀계수β0, β1, β2, …, βi를 찾는 것을 말한다. 이를 위해 최소자승법 (ordinary least square: OLS)을 이용하여 추정한다.
또한, 다중회귀식을 추정하는 방식에는 여러 가지가 있는데 가장 대표적인 것이 동시입력방식 (Enter)이다. 동시입력방식 (Enter)은 연구자가 고려하는 모든 독립변수을 한꺼번에 포함하여 분석하는 방법이다. 이 방식을 이용하면 다른 독립변수가 통제된 상태에서 특정 독립변수의 영향력을 알 수 있으며, 또한 연구자가 고려하는 모든 독립변수가 동시에 종속변수를 설명하는 정도를 알 수 있다 (Lee and Lim, 2006).
다중회귀분석의 결과 중에서 단순회귀분석의 결과와 다른 점은 결정계수 (R2) 대신에 수정결정계수 (adjusted coefficient of determination, R a 2
여기서, 수정결정계수는 값이 1에 가까울수록 독립변수가 투입되었을 때 회귀식의 설명력이 매우 크다는 것을 의미한다. 그러나 독립변수 사이에 가장 강한 상관관계가 존재할 경우, 회귀계수의 일반적인 해석은 심각한 문제를 발생할 수 있다 (Park, 2007). 이에 따라 다중공선성 (Multi collinearity) 진단을 통해 분석변수를 조정해야 한다. 다중공선성을 검증할 수 있는 방법으로는 변량의 팽창정도를 의미하는 VIF (Varinance Inflation Factor)가 10 이상이 되거나 공차한계 (Tolerance)가 0.1 이하이면 다중공선성에 문제가 있다고 판단할 수 있다.
2.3 주성분분석
본 연구에서는 서로 상관관계가 있는 지표들의 정보 손실을 최소화하고 시각적인 파악을 위해 주성분 분석의 방법을 선택하였다. 여러 개의 독립변수에 대해 얻어진 다변량 자료를 분석의 대상으로 하는 주성분분석 (PCA)은 다차원적인 변수들을 축소, 요양하는 차원의 단순화와 더불어 일반적으로 서로 상관되어 있는 독립변수들 상호간의 복잡한 구조를 분석할 수 있는 다변량 분석기법이다. 주성분 분석은 독립변수들을 선형변환 (Linear transformation)하고, 독립변수에 다변량 자료의 공분산관계 (Covariance relation)로부터 주성분 (Principal Component)이라고 불리는 서로 상관되어 있지 않고 독립된 새로운 인공변수들을 유도한다. 이는 다변량 통계 분석 기법 중에서 가장 오래되고 폭넓게 사용되는 기법으로 분석자체로 어떤 결론에 도달하기 위한 분석이 아닌 차후의 분석을 위한 수단을 제공하여 주는 단계이다 (Jang, 2004). 즉, 변수들의 전체 분산 대부분을 소수의 주성분을 통해 설명하는 것으로 처음 발생한 주성분은 변수들의 전체 분산 중 가장 큰 부분을 설명하도록 유도되고, 이후 발생한 주성분은 먼저 발생한 주성분과 독립적 관계를 가지면서 앞에서 설명되지 않은 나머지 분산 부분을 최대한 설명되도록 한다 (Yoo and Kim, 2008). 주성분 분석은 변수들 간의 측정단위의 상이함으로 인해 가장 큰 분산을 가지는 변수가 중요한 변수로 해석 될 수 있으므로 이러한 오류를 방지하기 위해 모든 데이터를 표준정규분포로 표준화하고 난 후 주성분 분석에 적용하는 것이 중요하다.
3. 자료 구축
3.1 대상지역 및 변수 선정
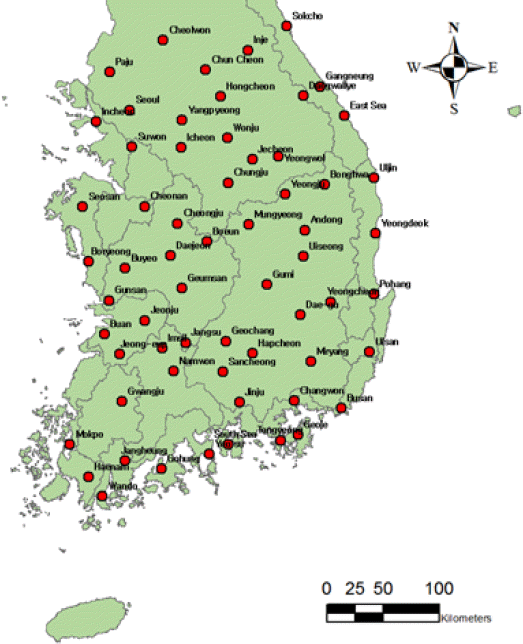
대설피해 추정 함수 개발을 위해 우리나라 남한 전체의 기상청 산하 관측지점 중 1994년 이전부터 최심적설량 및 최심신적설량의 관측 기록이 존재하는 68개의 지점을 선정하였고, 그 관측지점은 Fig. 2와 같다. 대설에 따른 피해액은 재해연보 (MPSS, 2015)의 자료를 활용하였다. 국민안전처에서 매년 발간하는 재해연보는 1970년대부터 작성되었으나, 작성 초기에는 피해지역에 대한 정확한 구분과 피해 시설물에 대한 분류가 체계화되지 않았으며, 현재 국가에서 제공하고 있는 체계화된 자료는 1994년부터 제공되고 있다 (NMDI, 2013). 재해연보는 피해 대상물을 건물, 선박, 농경지, 농작물과 12개의 공공시설 (도로, 하천, 소하천, 수도, 항만, 어항, 학교, 철도, 수리, 사방, 군시설, 소규모 등),
6개의 사유시설 (축대 및 담장, 가축, 축사 및 잠사, 수산증양식, 어망 및 어구, 비닐하우스 등)로 구분하여 피해액을 기록하고 있다. 대설피해액은 1994년부터 2015년까지 데이터를 사용하여 피해기간별 구축하였고, 매년 당해연도의 물가를 기준으로 발표되고 있기 때문에, 2015년 생산자 물가지수기준으로 환산하여 사용하였다. 또한, 대상지역으로 선정된 68개에 해당하는 시⋅군⋅구별 도시면적 비율과 비도시면적 비율을 산정하고, 도시면적 비율이 0~20 % 인 시⋅군⋅구를 Ⓐ권역, 21~80 % 인 시⋅군⋅구를 Ⓑ권역, 81~100 % 인 시⋅군⋅구는 Ⓒ권역으로 총 3개의 권역으로 구분하였다. 대상지역을 3개 권역으로 구분하여 1994년부터 2009년까지의 자료를 이용하여 모형을 구성하고, 나머지 2010년부터 2015년까지의 자료를 검증용 자료로 활용하였다.
대설에 따른 피해규모에 영향을 미치는 여러 가지의 인자들이 복잡하여 그 메카니즘을 정확히 모의하는 것이 중요하다. 변수를 선정하기에 앞서 이를 구조적으로 정립할 필요가 있다. 본 연구에서는 대설피해에 가장 큰 영향을 줄 것으로 예측되는 총 10개의 기후관련 요인 (Climate factor)과 사회⋅경제적 요인 (Society economic factor)을 변수로 선정하였다.
3.1.1 기상관련 요인
본 연구에서는 대설피해 규모에 큰 영향을 줄 것으로 예측되는 기후관련 변수로 최심적설량 (C1), 최심신적설량 (C2), 기간별 최심적설량 합 (C3), 평균기온 (C4), 최대기온 (C5), 최저기온 (C6)인 총 6개를 선정하였다. 최심적설량은 24시간 간격으로 측정한 적설량의 깊이를 의미하고, 최심신적설량은 24시간 간격으로 새로 쌓인 눈만을 측정한 적설량의 깊이를 의미한다. 또한, 각 대상지역의 기상관측소에서 수집된 자료를 시⋅군⋅구 단위의 티센 계수를 산정하고, 이를 면적적설량으로 환산하여 데이터를 구축하였다. 기온에 따라 달라지는 누적적설량을 고려하기 위해 평균기온 (C4), 최대기온 (C5), 최저기온 (C6)을 변수로 선택하였다. 즉, 기온은 높고 낮음에 따라 피해의 정도가 각각 상이할 것으로 예상되어 3개의 기온변수를 선정하였다.
3.1.2 사회⋅경제적 요인
사회⋅경제적인 변수로 선정된 농촌지역의 인구 (SE1), 농촌지역인구밀도 (SE2), 지역총생산량 (SE3), 1인당 지역총생산량 (SE4)은 비닐하우스, 수산증양식, 축사⋅잠사, 농작물에 집중되는 대설피해에 따른 추정 함수 개발을 위해 농촌지역의 범위가 중요하고 판단하여 선택하였다. 농촌지역의 인구는 행정구역별 주민등록인구를 기준으로 농촌지역 인구의 값이고, 농촌지역인구밀도는 농촌지역 인구의 값을 행정구역별 면적으로 나눈 값 (명 / km2)이다. Cavallo and Noy (2010)에 따르면, 지역총생산량이 클수록 폭설 피해에 노출될 가능성이 높은 경향이 있다고 기술하여 지역총생산량 및 1인당 지역총생산량을 변수로 선정하였다. 또한, 통계청에서는 2000년 이전의 자료를 제공하지 않고 있기 때문에, 2000년 이후의 지역총생산량 자료를 이용하여 2000년 이전의 자료를 추정하여 사용하였다. 지역총생산량 및 1인당 지역총생산량 자료는 피해액과 마찬가지로 2015년 생산자 물가지수로 환산하였다.
3.2 주성분분석을 이용한 입력자료 구축
3.2.1 주성분 추출
본 연구에서 선정한 총 10개의 변수들의 설명력을 추정하기 위해 주성분분석을 이용하여 차원을 축소하기에 적합한지 판단하였다. 판단 결과, 전반적으로 추정 값이 큰 값을 가지는 것으로 나타나 주성분 분석을 적용하기에 적합한 것으로 판단하였으며, 각 요인들 간의 고유 값 차이와 각 요인의 분산에 대한 설명정도를 비율로 기후관련 요인과 사회⋅경제적 요인을 구분하여 각각의 요인을 추출하고, 이에 따른 결과는 Tables 1 ~ 3과 같다. 각 군집별 추출된 성분은 기후관련 변수에서 총 변량이 79.07 %, 82.50 %, 80.91 %로 산정되었고, 사회⋅경제적 변수의 총 변량은 85.94 %, 68.41 %, 85.51 %로 산정되었다. 최종적으로 3개의 군집에서 모두 기후관련 변수는 상위 2개. 사회⋅경제적 변수는 상위 2개의 주성분을 선택하는 것이 안정적인 것으로 나타났다.
Table 1
Eigenvalues and Total Variances Explained by Components (Ⓐ Region)
Table 2
Eigenvalues and Total Variances Explained by Components (Ⓑ Region)
Table 3
Eigenvalues and Total Variances Explained by Components (© Region)
3.2.2 성분 부하량 산정
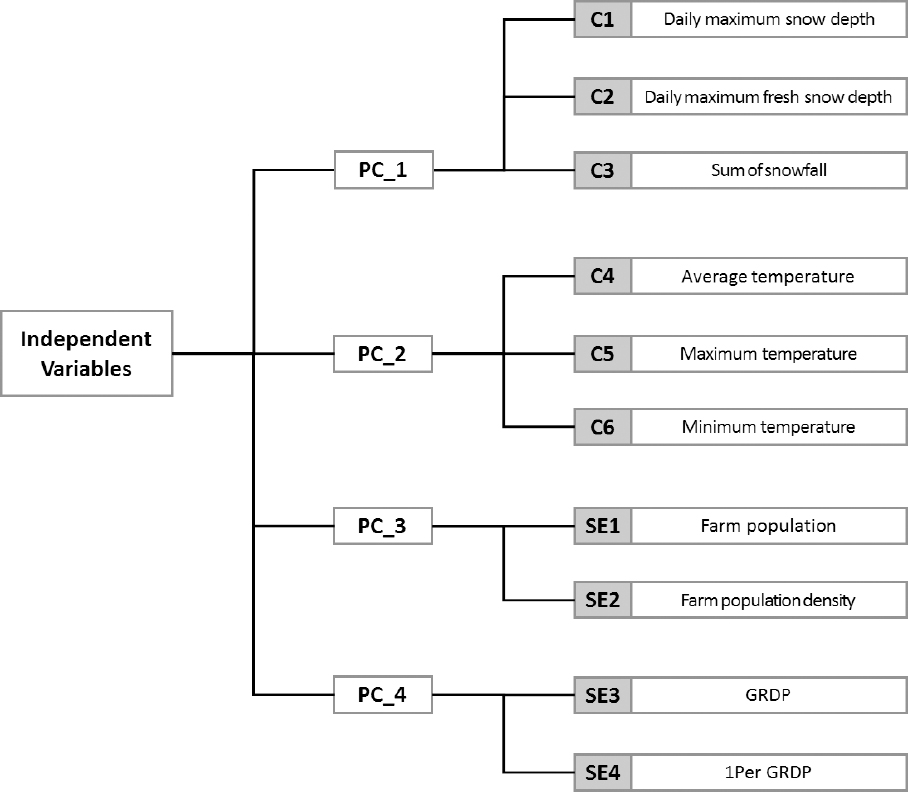
요인에 따른 설명력을 높이기 위해 하나의 요인에 높은 적재 값을 갖고 나머지 요인들에는 낮은 적재 값을 갖도록 요인회전 (Factor rotation) 방법을 적용하였다. 성분을 추출하기 위한 방법 중 가장 많이 사용되는 Varimax 방법을 적용하여 주성분을 추출하였다 (Kim, 2010). 이는 변수들 사이의 관계가 서로 독립적일 때 적용하는 직각회전 방식 중 변수들과 요인 사이에 높게 적재되는 변수의 수를 줄여서 요인의 해석을 쉽게 할 수 있다. 각 주성분의 의미를 설명하기 위해 선택된 주성분과 변수들간의 관련 정도를 분석하였다. 적재값은 그 값이 큰 변수에 해당하는 주성분에서 중요한 변수로 작용한다. 주성분분석을 활용하면 본 연구에서 적용하는 인공신경망 및 다중회귀 모형을 구성할 때 추출된 요인적재 값은 변수들 간의 높은 상관성이 작용할 때 발생하는 다중공선성 (Multi collinearity)을 제거할 수 있으므로, 상관성이 높은 변수들끼리의 다중공선성이 존재하지 않는다. 각 권역별 주성분은 요인적재 값의 크기가 높은 변수들끼리 묶어 주성분을 구성하였으며, Table 4와 같이 순서대로 정리하여 결과를 도출하였다. 또한, Fig. 3은 주성분분석을 이용하여 차원 축소한 독립변수의 계층적 구조를 나타내었다.
Table 4
Result of Factor Loading by Principal Components for Each Region
4. 대설피해 추정 함수 개발
4.1 인공신경망 모형의 구성
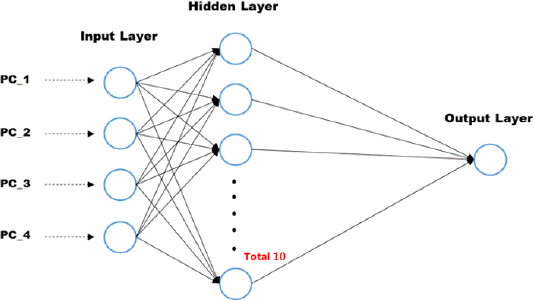
대설피해 추정 함수 개발을 위한 인공신경망 모형의 구성변수는 Table 5와 같다. 일반적으로 인공신경망의 중간층의 개수는 입력 자료의 개수가 d 개 일 때, 2d 또는 2d +1로 정할 수 있다. 이에 따라, 본 연구에서는 입력 자료의 개수에 따라 중간층을 10개, 출력층은 1개로 구성하였고, 모형의 그 구조는 Fig. 4와 같다. 앞서 구축된 각 권역의 입력 자료를 활용하여 1994년부터 2009년까지의 자료를 인공신경망 모형의 학습 자료로 사용하여 각각의 입력층과 중간층, 중간층과 출력층사이의 최적의 매개변수를 추정하고, 학습과정을 통해 추정된 연결강도를 이용하여 2010년부터 2015년까지의 자료로 구축된 모형을 검증하는 자료로 사용하였다.
Table 5
Components of Artificial Neural Network Model
| Components | |
|---|---|
| Input layer | Total snow damages |
| PC_1 | |
| PC_2 | |
| PC_3 | |
| PC_4 | |
| Hidden layer | 10 |
| output layer | 1 |
인공신경망 모형을 대설피해 추정 함수 개발을 개발하기 위해 학습을 통한 모형의 최적화 과정이 필요하며, 적정 오차범위 내에서 학습오차를 최소화하여 예측모형을 구성해야 한다. 신경망 모의의 최적화에 있어 학습률 (α), 모멘텀 (β), 최대학습 횟수, 중간층 수, 중간층의 뉴런 수 등에 결정이 필요하나 어떠한 값이 학습에 적합한지 규정할 수 없으며 일반적인 범위 내에서 값을 변경해 가면서 최적 값을 찾아야 한다 (Oh, 2000). 그러나 본 연구에서는 인공신경망 모형의 학습에 적용되는 학습률 (α), 모멘텀 (β), 최대학습 횟수는 Kim et al. (2014)와 같이 0.05, 0.1, 8,000번을 사용하였고, 3개의 권역으로 구분된 기상관측 및 통계 자료를 활용하여 대설피해액을 추정하였다.
또한, 일반적으로 개별 자료를 이용하여 복합 자료로 만드는 과정에서는 표준화는 각 자료들이 가지는 범위가 결과에 미치는 영향을 최소화하기 위해 적용할 수 있다 (Kim et al., 2007). 대설 피해액 추정을 위해 선정되고 구축된 독립변수들은 그 단위나 중요도가 각각 상이하기 때문에, 자료의 범위와 단위에 따른 편차 문제를 해소하기 위해 표준화 과정을 수행하였다. 본 연구에서는 Eq. (4)와 같은 Z-Score 방식으로 환산된 표준값을 사용하였다.
여기서, Xi: 개개인의 값, μ: 모평균, σ: 모표준편차
4.2 다중선형회귀 모형의 구성
본 연구에서는 대설피해 추정 함수 개발을 위해 68개 대상지역의 기상관측 및 통계 자료를 수집하고, 이를 3개의 권역으로 구분하고 다중선형회귀 모형을 동시입력방식 (Enter)으로 구성하였다. 다중선형회귀 모형에서 사용된 독립변수는 앞에서 설명하는 바와 같이 변수를 선정하고, 4개의 요인으로 차원을 축소하여 독립변수로 적용하였다 (Table 6). 앞서 구축된 각 권역의 입력 자료를 활용하여 1994년부터 2009년까지의 자료를 다중선형회귀 모형의 학습 자료로 사용하고, 인공신경망 모형과 동일하게 2010년부터 2015년까지의 자료로 구축된 모형을 검증하는 자료로 사용하였다. 또한, 독립변수들 간의 상관관계로 인해 나타나는 다중공선성은 다중회귀분석 결과의 유효성에 큰 영향을 미치므로, 공차한계 (Tol.), 분산팽창요인 (VIF)을 계산하였다. 3.2.2절에서 언급하였듯이 추출된 요인적재 값은 독립변수들의 다중공선성 (Multi collinearity)을 제거할 수 있기 때문에, 3개의 권역에서는 다중공선성이 발생하지 않았다. 또한, Table 7과 같이 3개의 권역을 대설피해 추정 함수식을 개발하였으며, F분포 유의확률이 0.05 이하로 회귀모형이 통계적으로 유의미한 것으로 나타났다.
4.3 인공신경망 및 다중선형회귀 모형의 검증
대설피해 추정 함수를 개발에 따른 인공신경망 모형 및 다중선형회귀 모형의 성능을 검증하기 위해 실제피해액과 모의된 피해액을 비교하였다. 또한, 각각의 모형에 따른 권역별 피어슨 상관계수 (Pearson Correlation Coefficient, R), 수정결정계수 (adjusted coefficient of determination), 평균제곱근오차 (Root Mean Square Error; RMSE), 평균절대오차 (Mean Absolute Error; MAE), Nash-Sutcliffe 모형효율계수 (Nash-Sutcliffe Model Efficiency Coefficient; NSE) 등을 사용하여 인공신경망 모형과 다중선형회귀 모형을 비교하였다. 피어슨 상관계수와 수정결정계수, 모형효율계수는 0과 1사이의 범위 값을 나타내며, 1에 가까울수록 모형의 적용성이 우수하다고 판단할 수 있고, 평균제곱근오차는 값이 작을수록 모형의 오차가 작은 것으로 판단할 수 있다. 또한, 평균절대오차는 실제 발생한 피해액과 추정된 피해액의 잔차를 절대값으로 산술평균한 값으로 0에 가까울수록 오차가 적다. 이에 따라 인공신경망 모형과 다중선형회귀 모형을 적용하였을 때, 각 권역별 통계오차분석의 결과를 Table 8에 타내었고, 추정된 피해액을 Fig. 5와 같이 실제 발생한 피해액과 모형의 성능을 검증하였다.
Table 8
Result of Statistical Errors Analysis Using Artificial Neural Network and Multiple Linear-regression
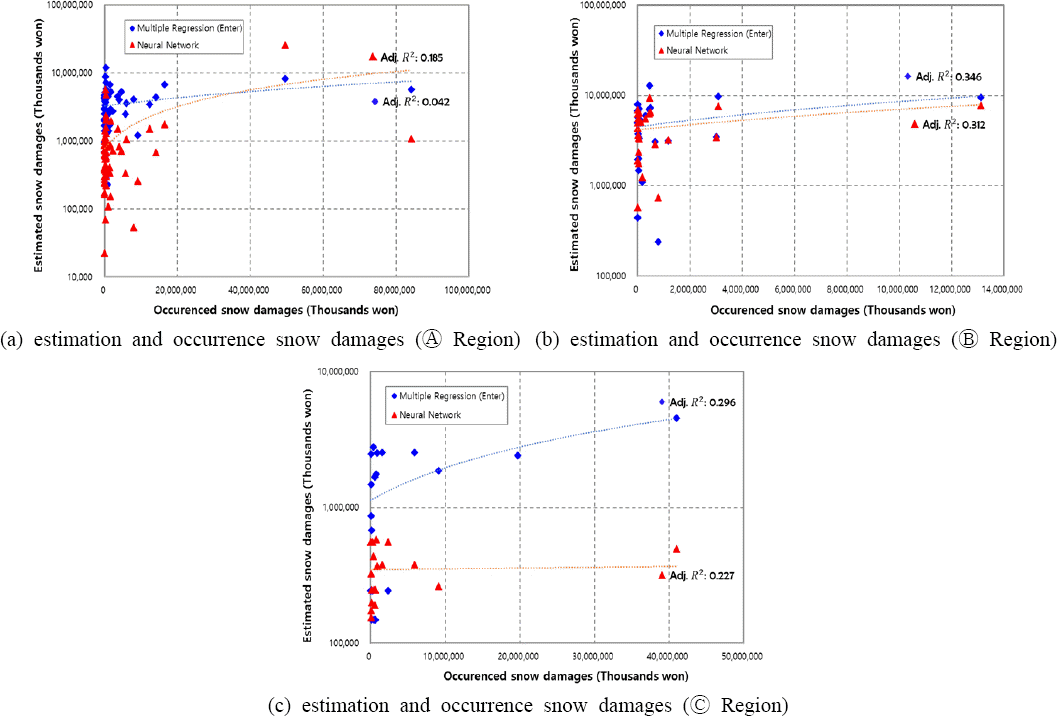
각 권역별 인공신경망 및 다중선형회귀 모형의 추정된 피해액과 통계오차분석을 수행한 결과, 인공신경망의 상관계수 (r)는 0.228 ~ 0.482 로 산정되었으며, 수정결정계수는 0.185 ~ 0.312 로 산정되었다. 다중선형회귀 모형의 상관계수 (r)는 0.092 ~ 0.541 로 산정되었으며, 수정결정계수는 0.042 ~ 0.346 로 산정되었다. 각 권역별 두 모형을 비교한 결과, Ⓐ 권역에서는 인공신경망 모형이 다중선형회귀 모형보다 우수한 결과를 보였으나, Ⓑ, Ⓒ 권역에서는 다중회귀모형이 인공신경망 모형보다 좀 더 우수한 결과를 나타났다.
Toya and Skidmore (2007) 에서 알 수 있는 것과 같이, 사회⋅경제적인 변수들을 모형에 고려하였을 경우, 모형의 설명력이 0.30 이하로 아주 낮게 계산되는 경향이 있으므로, 본 연구에서 제시된 모형도 의미가 있다고 볼 수 있다. 또한, 인공신경망 모형은 기상현상과 같이 수학적으로 해결하기 어려운 비선형문제에 대한 분석 및 예측에 유용하게 활용하지만, 학습을 통해서 모형의 최적화가 이루어지기 때문에 학습 시 적용된 입력 자료의 범위 및 개수는 예측결과에 아주 큰 영향을 미치게 된다 (Kim et al., 2014). 즉, 인공신경망의 경우에는 모형을 통한 추정은 학습에 필요한 입력 자료의 종류가 많아지고, 기상관측소의 데이터 형태가 정확할수록 모형의 효율 및 적용성이 높게 나타난다. 근본적으로 모형의 설명력이 낮은 이유에는 실제 여러 가지의 요인으로 작용하고 있다. 향후 추가적인 자료의 보완이나 모형의 고도화가 필요하다.
5. 결론
본 연구에서는 재해연보에 기록된 대설피해 추정 함수를 개발을 위해 기후관련 요인과 사회⋅경제적 요인 총 10개를 변수로 선정하고, 주성분분석을 사용하여 각 변수들의 차원을 축소한 성분 부하량을 산정하여 4가지의 주성분으로 입력 자료를 구축하였다. 4가지의 입력 자료로 활용한 인공신경망 및 다중선형회귀 모형을 도시면적 비율로 구분한 3개의 권역을 대상으로 구성하였다. 실제 발생한 피해액과 추정된 모의 피해액의 통계오차분석을 통해 대설피해 추정 함수를 개발하였다. 본 연구에서 제안된 인공신경망 및 다중선형회귀 모형은 통계적으로 유의미 하였으나, 각 권역별 가장 큰 수정결정계수의 결과 값은 Ⓐ 권역 0.185, Ⓑ 권역 0.346, Ⓒ 권역 0.296 로 매우 낮았다. 또한, 각 권역별 두 모형을 비교한 결과, Ⓐ 권역에서는 인공신경망 모형이 다중선형회귀 모형보다 우수한 결과를 보였으나, Ⓑ, Ⓒ 권역에서는 다중회귀모형이 인공신경망 모형보다 좀 더 우수한 결과를 나타났다. 극값이 포함되어 있는 경우에는 두 모형 모두 경향성을 잘 재현하지 못하는 한계를 보이기는 하였으나, 이는 기본적으로 자연재해의 규모를 추정하는 것은 매우 어려운 문제이다. 본 연구를 통해 근본적으로 모형의 설명력이 낮은 이유에는 여러 가지의 요인으로 작용할 수 있으나, 크게 다음과 같이 2가지로 판단된다.
첫 번째, 재해연보의 대설 피해액을 활용하여 대설피해 추정 함수식을 개발하는 것은 근본적인 한계를 가지고 있다. 재해연보에 조사된 피해액 자체가 실제 발생한 모든 피해금액을 포함한다고 보기 어려운 부분도 있다. 이는 재해연보의 피해액 산정을 위해, 사유시설의 경우 신고 된 자료를 바탕으로 피해액을 산정하고, 공공시설의 경우 별도의 단가기준을 설정하여 반영하기 때문이다 (NDMI, 2013). 현재 재해연보에 산정된 피해액은 조사 당시에 조사자의 주관에 많이 의존하고 있기 때문이다. 향후 피해액 산정의 객관성 확보를 위한 노력이 필요하다. 즉, 재해에 따른 피해발생 원인은 최심적설량이 많은 이유일 수 있으나, 시설물의 노후화 및 시공의 불량으로 외부적인 요인에 의해 야기될 수 있어 재해에 대한 대비책에 따라 피해가 줄어들 수 있다. 또한, 재해연보는 1970년대부터 작성되었으나, 여러 가지의 문제점으로 인해 현재 국가에서 제공하고 있는 자료는 1994년부터 제공하고 있기 때문에 자료의 수가 현저히 부족한 상황이다. 이러한 기초자료의 문제점들을 근본적으로 해결하기 쉽지 않다.
두 번째, 최심적설량 및 최심신적설량의 경우, 분 단위 또는 시간 단위로 관측되는 강수량과 달리 일 단위 형태로만 제공되고 있는 상황이다. 본 연구에서 활용된 기온자료 (평균기온, 최대기온, 최저기온)가 실제 최심적설량이 발생할 때의 기온으로 보기에는 어렵기 때문에 모형의 설명력은 낮아질 수밖에 없다. 정확도 및 신뢰도가 높은 대설피해 추정 함수 개발하기 위해 분 단위 또는 시간 단위로 관측하는 AWS와 같은 시스템을 활용하여 관측 자료를 구축하게 된다면, 훨씬 정확성 및 효율성 있는 추정 함수를 개발할 수 있을 것으로 판단된다. 또한, 현재 우리나라의 적설량 관측은 유인관측소에서만 측정하고 있다. 최근 일부 관측소에서 시범적으로 자동 적설관측을 시행하고 있지만, 거의 대부분 적설판을 이용하여 사람이 직접 적설량의 깊이를 측정하는 방식으로 이루어지고 있다. 이에 따라, 수동적으로 측정하는 방식의 제약조건으로 적설량 관측을 수행하기 때문에, 적설량의 분포를 정확하고 신뢰도 높은 자료를 수집하는데 어려움을 겪고 있다.
향후 모형의 고도화 및 추가적인 자료의 보완, 이와 같은 문제점을 보완해 나간다면 보다 향상된 대설피해 추정 함수 개발이 가능하고, 폭설시 재난대응 및 폭설대비 관련 정책 수립을 위한 정부에서 종합적으로 판단하여 방재기준을 마련할 수 있을 것으로 판단된다.




